Tables, Columns & Indexes
Table of Contents
What is a Schema?
In relational databases, a schema is a named container that groups tables, views, sequences, and other objects. Think of it as a namespace — a schema can contain only one table with a given name. DbSchema displays schemas in the tree panel on the left; expanding a schema reveals all its objects.
Tables
A table is a collection of data focused on a specific topic — for example customers, orders, or products. Tables are made up of columns (which define what data can be stored) and rows (the actual data records). Each row is uniquely identified by its primary key.
Creating a Table
Right-click the diagram canvas and choose New Table, or use the toolbar button. Give the table a name and press Enter. The table appears on the canvas and is immediately listed in the tree panel.
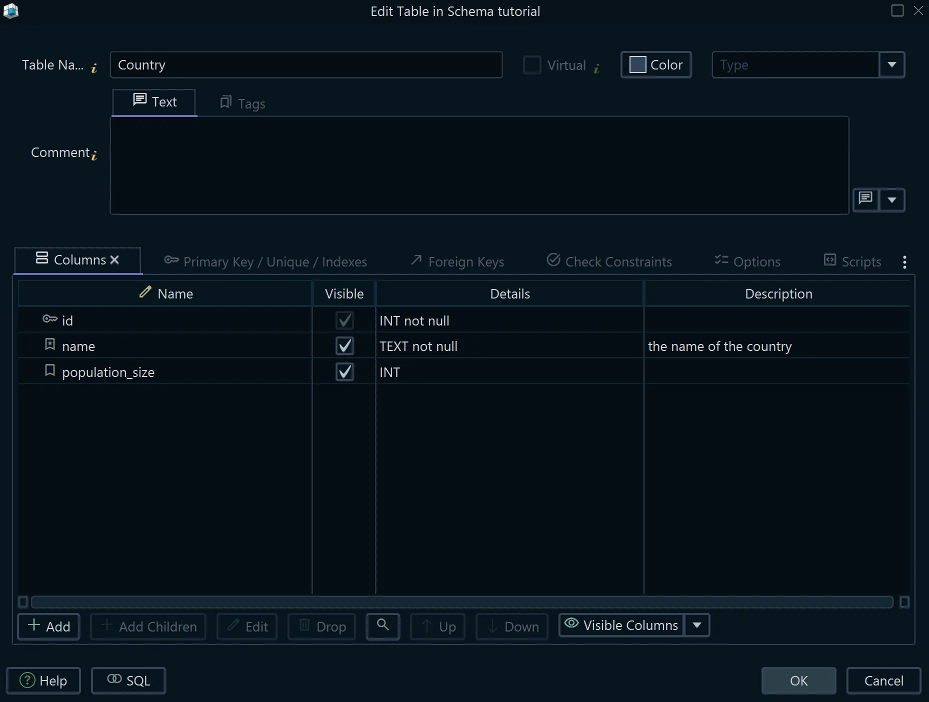
Editing a Table
Double-click the table header on the diagram to open the Table Dialog. From here you can:
- Columns — add, rename, reorder, or remove columns and change their types
- Indexes — define the primary key and additional indexes
- Foreign Keys — manage references to other tables (see Foreign Keys)
- Constraints — add check constraints at the table level, for example
age > 14 OR with_parents = true - Options — set database-specific table options without writing DDL manually
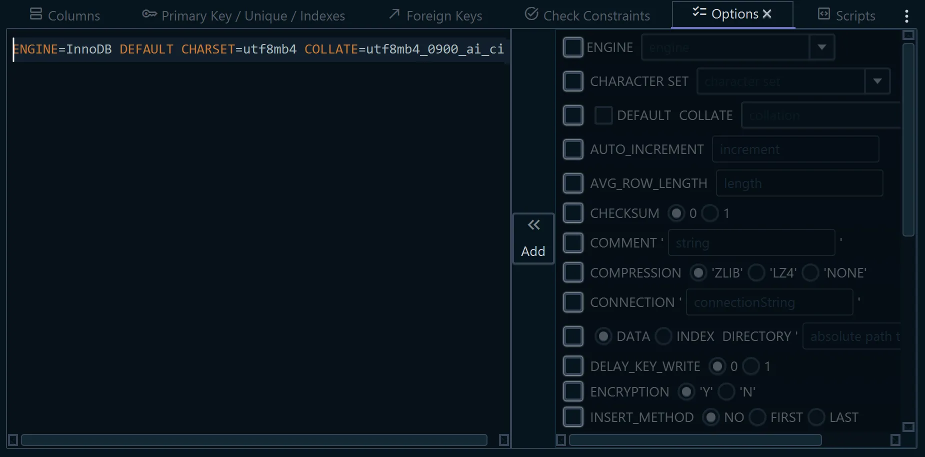
The Options tab covers engine, charset, tablespace, and other settings specific to your database.
Columns
Every column holds one specific type of data. To add or edit a column, open the Table Dialog and go to the Columns tab, or double-click any column directly in the diagram.
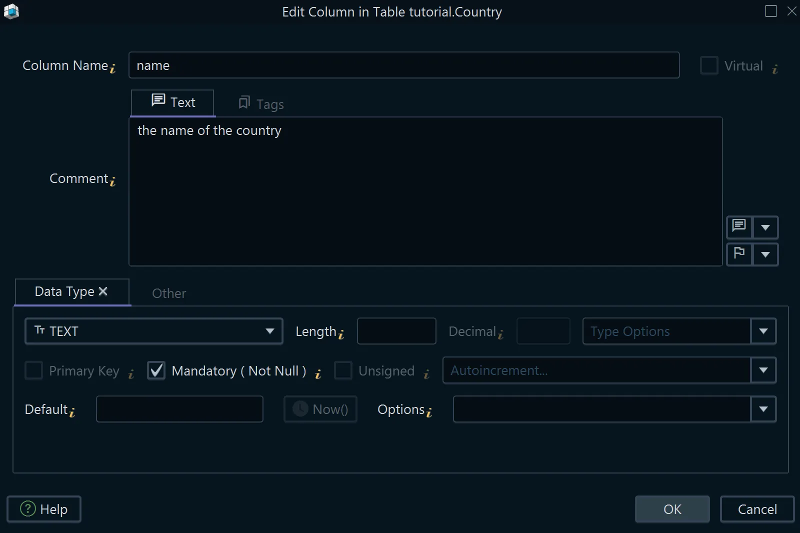
Data Types
Each column must have a data type — for example VARCHAR(100), INTEGER, BOOLEAN, or TIMESTAMP. For numeric types you can also specify precision (total digits) and scale (decimal digits).
Column Properties
- NOT NULL — the column must always contain a value;
NULLis not allowed - Default Value — used automatically when no value is provided on insert. Examples:
truefor booleans,0for numbers,current_date()for dates - Unsigned — restricts numeric columns to non-negative values (MySQL and a few others)
- Identity / Auto-increment — the database generates the value automatically on each insert, commonly used for primary key columns. MySQL uses
AUTO_INCREMENT; PostgreSQL and SQL Server useIDENTITY
Primary Keys
A primary key uniquely identifies each row in a table. It is defined on one or more columns and implies NOT NULL plus UNIQUE constraints. Primary key columns are highlighted with a key icon in the diagram.
To set the primary key, open the Table Dialog and go to the Indexes tab, then flag the relevant column(s) as the primary key.
Indexes
Indexes speed up queries by letting the database locate rows without scanning the whole table. Each index is built on one or more columns.
DbSchema supports three index types:
- Normal — allows duplicate values; used to accelerate searches and joins
- Unique — rejects duplicate values; an error is raised if a duplicate is inserted
- Primary Key — same as a unique index, with the additional requirement that the column is NOT NULL
Manage indexes in the Indexes tab of the Table Dialog.
Typical schema workflow
For most teams, schema editing in DbSchema follows a predictable flow:
- create or reverse-engineer the tables you need
- define column data types and defaults
- set the primary key and any unique indexes
- add foreign keys between related tables
- document the schema and sync the changes to the live database
That makes the schema editor a practical bridge between design, implementation, and documentation. If you want the visual canvas view as well, read DbSchema Diagrams. If you are ready to deploy changes, continue with Synchronize Database.
Foreign Keys
Foreign keys create enforced references between tables — for example, every order.customer_id must match a row in the customers table. For full details on creating, editing, and working with foreign keys (including virtual foreign keys and composite keys), see the Foreign Keys page.
FAQ
Can I design tables in DbSchema without a live database?
Yes. DbSchema supports offline design, so you can create or edit the model first and sync it later.
Where do I define primary keys and indexes?
Open the Table Dialog, then go to the Indexes tab to mark primary keys, unique indexes, and normal indexes.
Can DbSchema handle database-specific table options?
Yes. The Options tab exposes engine, charset, tablespace, and other database-specific settings without requiring hand-written DDL.