Query Builder
The Visual Query Builder lets you construct SQL SELECT queries using only the mouse — no SQL knowledge required. It opens inside the diagram, is saved to the model file, and can be reopened from the Editors menu.
Opening the Query Builder
There are three ways to open the Query Builder:
- Click a table header in the diagram — opens the builder pre-loaded with that table
- Drag a table from the diagram — start an empty builder and drag a table into it
- Editors menu — choose New Query Builder to start from a blank canvas
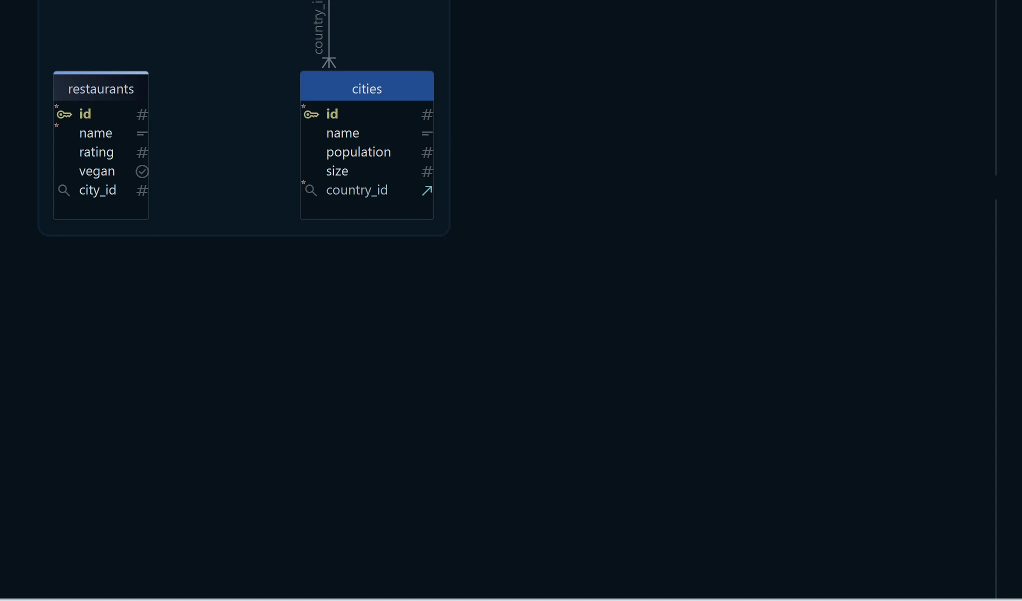
Adding Tables Using Foreign Keys
Once the first table is loaded, expand the query to related tables using foreign keys or virtual foreign keys. Click the small arrow icon next to a column to follow a foreign key and add the related table.
Click the join type label on the connecting line to switch between INNER JOIN, LEFT JOIN, and EXISTS.
Virtual foreign keys can be created in the diagram by dragging one column onto another — they are saved to the model file and work exactly like real foreign keys in the Query Builder.
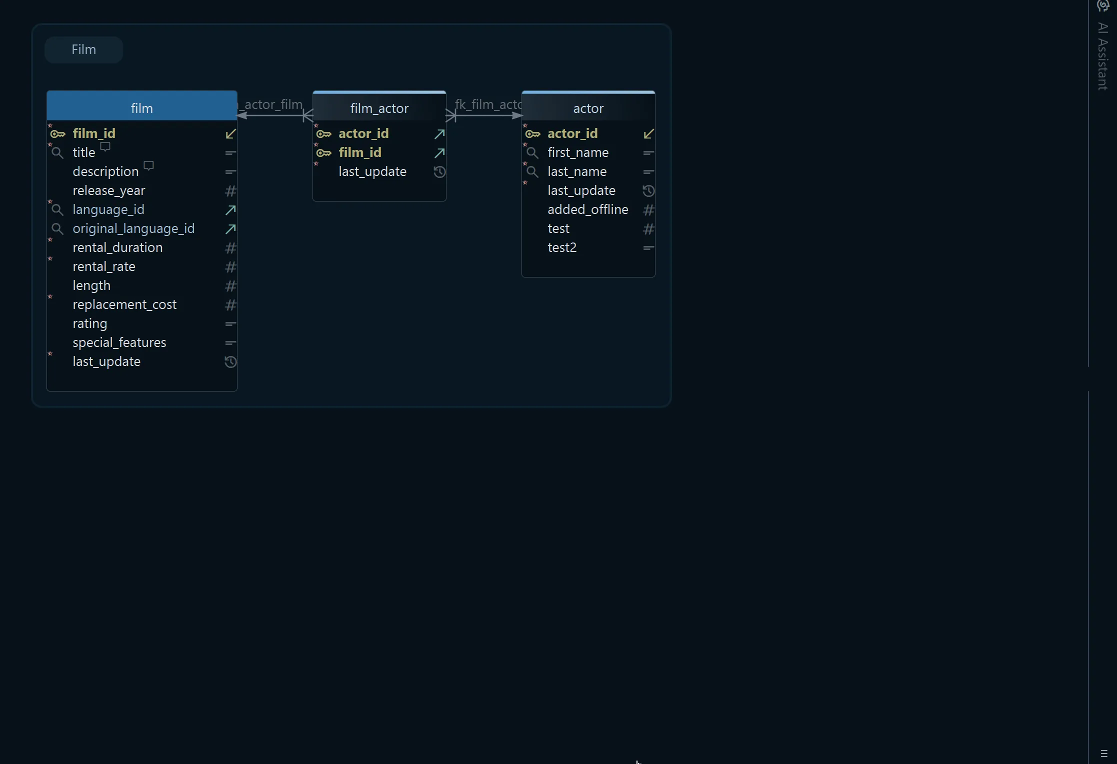
Choosing Columns
Tick the checkbox next to each column you want to include in the SELECT list. Unticked columns are excluded from the generated query.
Filtering Data
Right-click any column and choose Filter to add a WHERE condition on that column. You can set the comparison operator and value directly in the filter dialog.
Aggregate Functions and Group By
Enable Group By mode using the toggle button in the Query Builder toolbar. In this mode:
- Ticked columns without an aggregate function become
GROUP BYcolumns - Right-click any column and choose Aggregate to apply
MIN,MAX,SUM,AVG, orCOUNT
The generated SQL is updated live as you make changes and is visible at the bottom of the builder.
Saving Results to File
Click the Save button in the result pane to export the full result set to a file. The query is re-executed and all rows are written to disk — useful for large result sets that do not fit on screen.
Dropping the Query Builder
To remove a Query Builder, right-click it in the structure tree under Diagrams and choose Drop. When you close a builder, DbSchema asks whether to keep it in the design model for later use or drop it permanently.