Turn Apache Solr Collections Into Readable Diagrams
Connect DbSchema to Apache Solr and turn the live schema into an editable visual model: explore relationships in interactive ER diagrams, plan changes on the canvas, and generate reviewed SQL scripts for deployment.
The workflow is designed for visual modeling, schema documentation, and deployment — keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Apache Solr Features Download Apache Solr JDBC Driver · All drivers
What happens after you download?
Get to your first Apache Solr schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Apache Solr or open a sample
Reverse engineer an existing Apache Solr database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
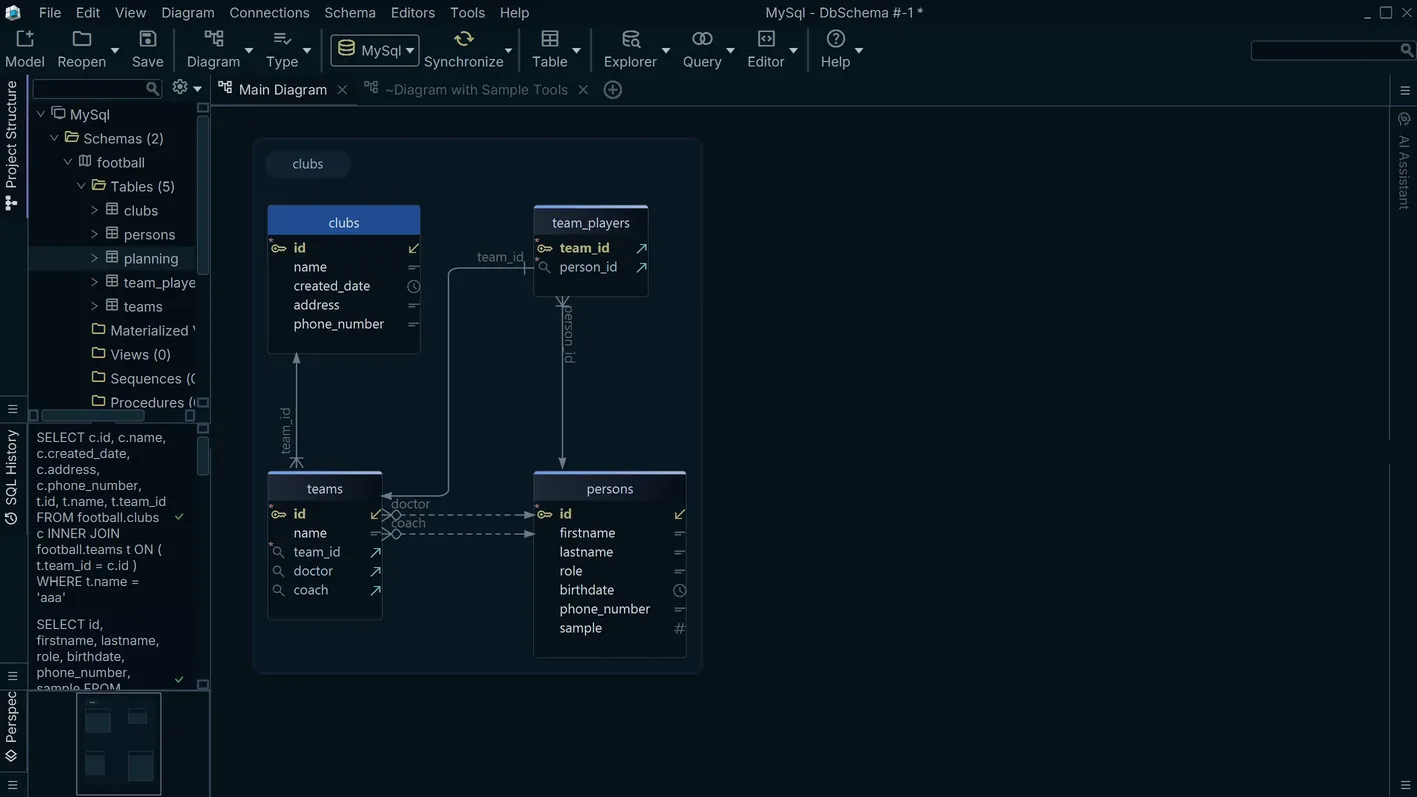
Collection and Core Architecture
Apache Solr is a widely adopted enterprise search platform built on Apache Lucene that powers full-text search, faceted navigation, and real-time indexing for applications of all sizes. In standalone mode, Solr organizes data into cores, each with its own schema and index. In SolrCloud mode, data is stored in collections distributed across nodes and coordinated by Apache ZooKeeper for high availability and automatic failover. Each collection schema defines fields with types, analyzers, and copy-field rules that control how text is tokenized and indexed. DbSchema connects to Solr through the SolrJ JDBC driver and introspects collection field schemas, rendering them as schema diagrams that make the field structure visible without reading raw schema.xml files.
Download DbSchema Free See Apache Solr Features
Writing SQL Queries Against Solr Collections
Solr exposes a SQL interface through Streaming Expressions that translates a subset of standard SQL into
native Solr queries executed across distributed collection shards. DbSchema's SQL editor connects over
this interface and provides auto-completion for collection names and field names, allowing analysts to
write SELECT, GROUP BY, and ORDER BY statements without learning
the Solr query syntax. Complex boolean search filters can be passed as WHERE predicates,
and aggregation functions like COUNT, SUM, and AVG are supported
where Solr's streaming aggregation engine allows them. Results appear in a paginated grid that is easy
to copy for reporting.
Exploring Indexed Documents with the Data Explorer
Paging through indexed Solr documents requires no query at all — the data explorer handles it directly. You can filter the result set by any field value, which internally translates to a Solr filter query, and sort rows by numeric or date fields. This is especially useful for verifying that a newly indexed batch of documents contains the expected fields and values before opening the collection to search traffic. For SolrCloud collections with multiple shards, the explorer merges results transparently so you see a unified view of the full collection rather than shard-by-shard segments.

Connecting DbSchema to a Solr Collection
- Install DbSchema — no account or payment is required to start the download.
- Add the SolrJ driver JAR (
org.apache.solr.client.solrj.io.sql.DriverImpl) to DbSchema's driver manager. - Set the connection URL to
jdbc:solr://localhost:8983?collection=mycollection, where8983is Solr's default HTTP port andmycollectionnames the collection to query. - For SolrCloud, point the URL at any node in the cluster — the ZooKeeper ensemble handles routing
internally. If the cluster is authenticated, add
usernameandpasswordparameters, or configure Kerberos, depending on your security setup. - Connect — DbSchema lists every field defined in the collection schema and renders it for visualization.
Benefits for Search Teams Running Solr
- Visualize Solr collection field schemas as diagrams, making complex schema.xml configurations easier to read than raw XML.
- Write SQL-style aggregation queries against Solr collections in the SQL editor and export results to CSV for reporting.
- Validate newly indexed document batches by browsing collection contents in the data explorer before promoting to production.
- Generate offline schema documentation for Solr collections to share with application developers integrating search features.
- Manage multiple Solr collections in a single project, switching between them on the schema canvas without reconnecting.
Inheriting a Solr collection with no record of what the schema.xml actually defines? Download DbSchema for free and get every field and analyzer laid out as a diagram in minutes.
Related databases
Teams working with Apache Solr often use these engines too. Explore dedicated guides and JDBC setup for each.