Understand Your Apache Pinot Tables at a Glance
DbSchema gives Apache Pinot teams a design-first workflow: import the existing schema as an interactive ER diagram, refine it visually, and ship every change as a reviewed SQL script.
Built for visual modeling, schema documentation, and deployment, with an offline model you can keep in Git, team collaboration, and documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Apache Pinot Features Download Apache Pinot JDBC Driver · All drivers
What happens after you download?
Get to your first Apache Pinot schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Apache Pinot or open a sample
Reverse engineer an existing Apache Pinot database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Segment, Schema, and Tenant Architecture
Apache Pinot was originally developed at LinkedIn and Uber to power user-facing analytics at sub-second latencies. The system organizes data into tables that are each governed by a schema definition, physically stored in immutable segments distributed across server nodes, and logically isolated by tenants for multi-tenancy. Pinot supports both offline and real-time table types, where real-time tables consume directly from Kafka streams. DbSchema connects to Pinot via the Pinot JDBC driver and introspects these table schemas, producing visual schema diagrams that show column names, data types, and index hints. You can document the StarTree, inverted, and sorted index configurations alongside the table layout, giving your team a complete picture of the physical data model.
Download DbSchema Free See Apache Pinot Features
Sub-Second Query Authoring in the SQL Editor
Pinot's SQL dialect follows the ANSI SQL standard closely but adds extensions for time-boundary
predicates and multi-stage query execution across segments. DbSchema's SQL editor surfaces Pinot table
and column names through auto-completion, letting analysts compose GROUP BY aggregations,
HAVING filters, and DATETIMECONVERT function calls without referencing the
schema separately. Query results appear in a paginated grid that handles the large result sets common in
OLAP workloads. Saved queries can be organized by table or use case, making it easy to build a library
of verified analytical queries that the broader team can reuse.
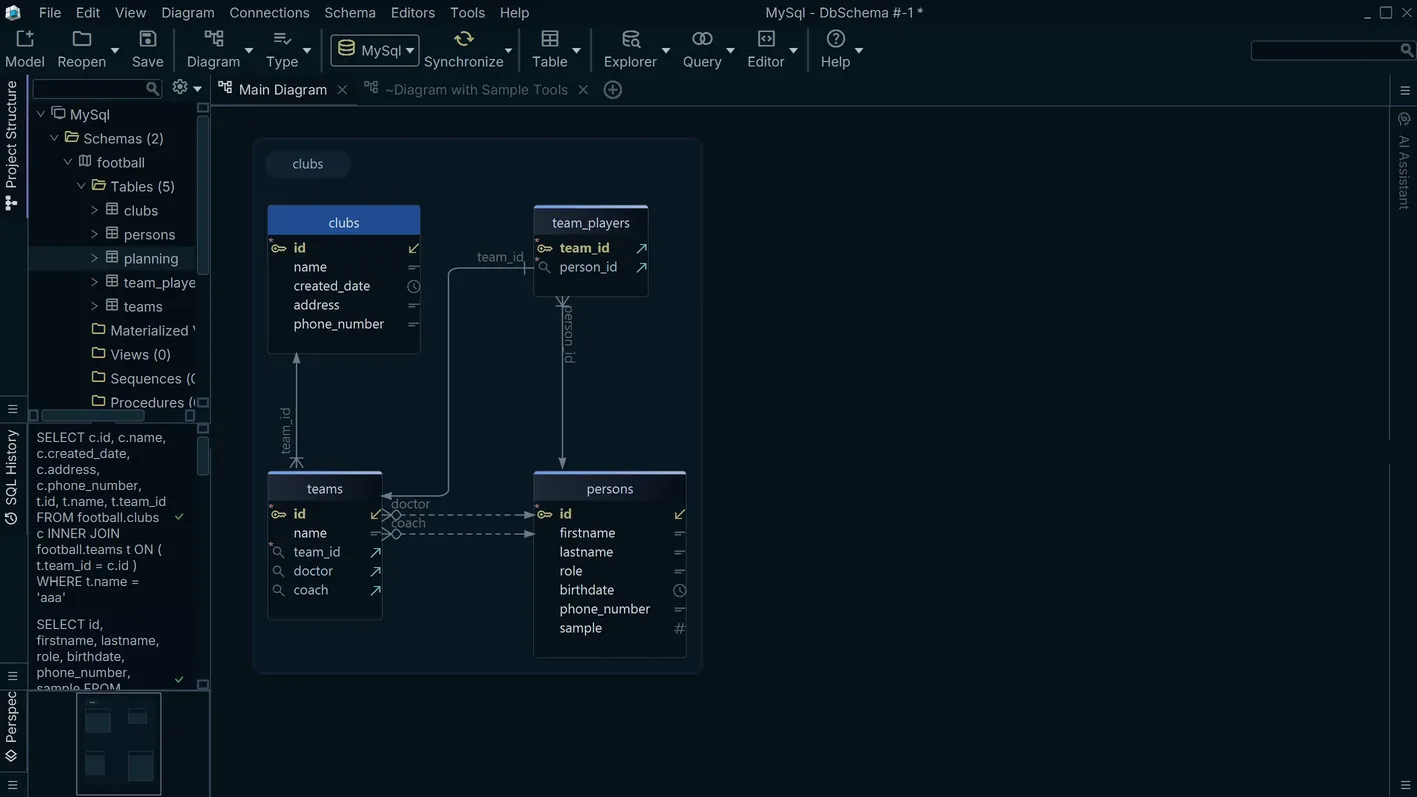
Exploring Pinot Table Data with the Data Explorer
The DbSchema data explorer lets you browse Pinot table contents interactively without writing SQL. You can filter rows by any column value, restrict to a specific time range using the primary time column, and page through results to spot anomalies in real-time ingested data. For Pinot's real-time tables this is especially useful: you can confirm that a newly started Kafka consumer is writing records with the correct schema before exposing the table to downstream BI tools. The explorer also shows column data types as inferred by the JDBC driver, which can be cross-referenced against the Pinot schema JSON to detect mismatches.

Get Connected to Apache Pinot in DbSchema
- Download DbSchema at no cost, with no account to create, and try Pro features free for 15 days.
- Download the Pinot JDBC driver JAR (
org.apache.pinot.client.PinotDriver) from the Apache Pinot releases and register it in DbSchema's driver manager. - Create a connection using
jdbc:pinot://localhost:9000, where9000is Pinot's default broker port; for clustered deployments, replacelocalhostwith the hostname or load-balancer address of your Pinot Broker. - For TLS-enabled clusters, switch to the
httpsscheme and supply the required certificate configuration; other authentication options depend on your specific Pinot deployment. - Connect — DbSchema automatically lists all Pinot tables available to the authenticated user.
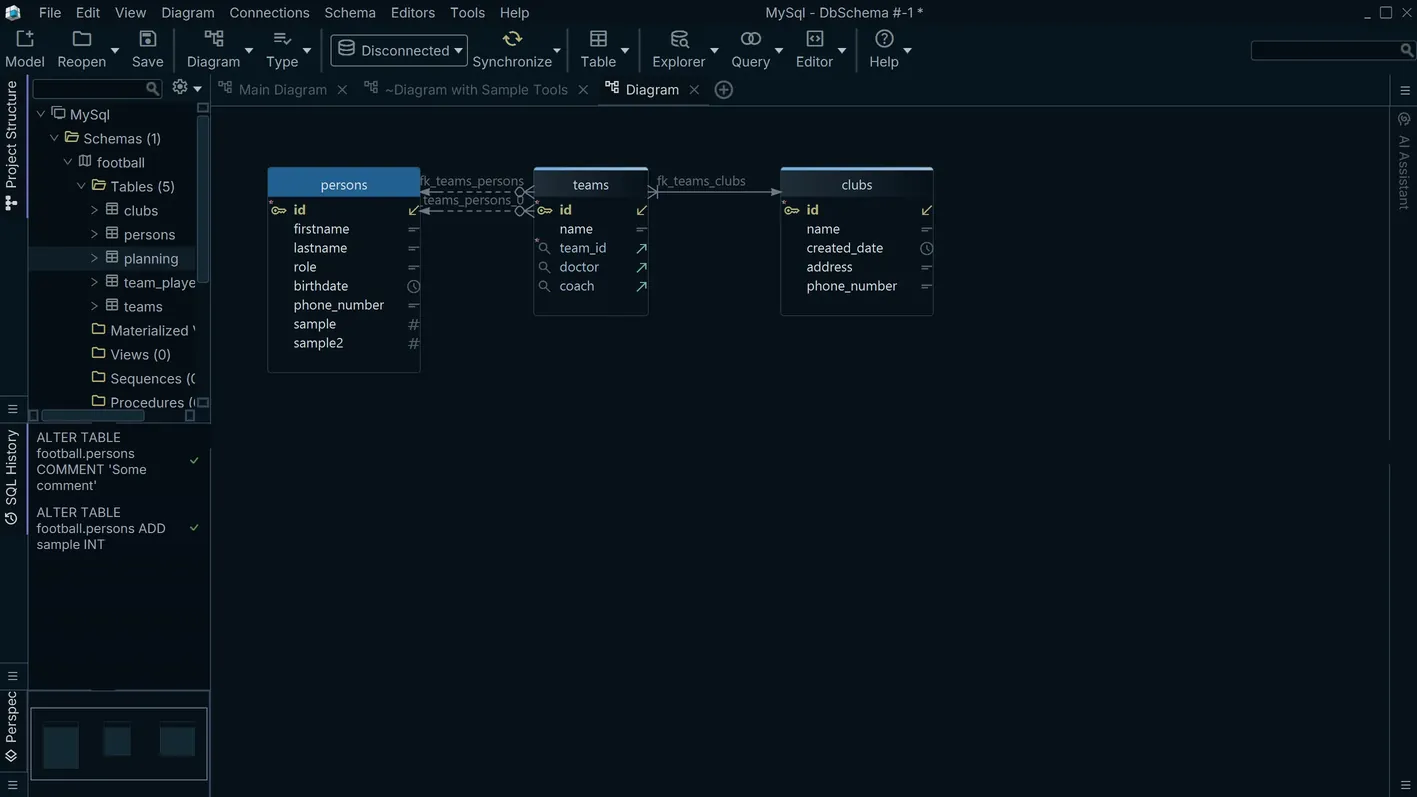
Reasons Analytics Teams Pair DbSchema with Pinot
- Visualize Pinot table schemas alongside their index configurations without reading raw schema JSON files.
- Validate sub-second aggregation logic in the SQL editor prior to wiring it into a user-facing dashboard query.
- Confirm real-time ingestion correctness by sampling live records from real-time tables in the data explorer.
- Generate HTML or PDF schema documentation for Pinot tables to onboard new data engineers quickly.
- Compare offline and real-time table schemas side by side in the layout canvas to ensure consistency.
Need to check whether your real-time and offline Pinot tables actually agree on structure? Download DbSchema for free and put both schemas side by side on the same canvas.
Related databases
Teams working with Apache Pinot often use these engines too. Explore dedicated guides and JDBC setup for each.