Visualize Apache HBase Schemas via Phoenix in DbSchema
DbSchema gives Apache HBase teams a design-first workflow: import the existing schema as an interactive ER diagram, refine it visually, and ship every change as a reviewed SQL script.
Built for visual modeling, schema documentation, and deployment, with an offline model you can keep in Git, team collaboration, and documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Apache HBase Features Download Apache HBase JDBC Driver · All drivers
What happens after you download?
Get to your first Apache HBase schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Apache HBase or open a sample
Reverse engineer an existing Apache HBase database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Apache HBase is a wide-column, NoSQL data store built on top of HDFS that provides random, real-time read and write access to large datasets. Its schema model organizes data into tables with column families — groups of columns stored together on disk — and rows identified by row keys. Apache Phoenix layers a SQL interface on top of HBase, enabling standard SQL DDL and DML operations while translating queries into native HBase scans. DbSchema connects through the Phoenix JDBC driver, reads the Phoenix-managed schema, and exposes HBase table structures for visual exploration and data browsing.
Browsing HBase Column Family and Data Type Structures
Phoenix exposes HBase column families and their column definitions as a typed SQL schema. DbSchema
reads this schema and displays the full data type catalog for each column — including Phoenix-specific
types like UNSIGNED_INT, ARRAY, and VARBINARY — giving
engineers visibility into the physical column family structure without using the HBase shell.
Download DbSchema Free See Apache HBase Features
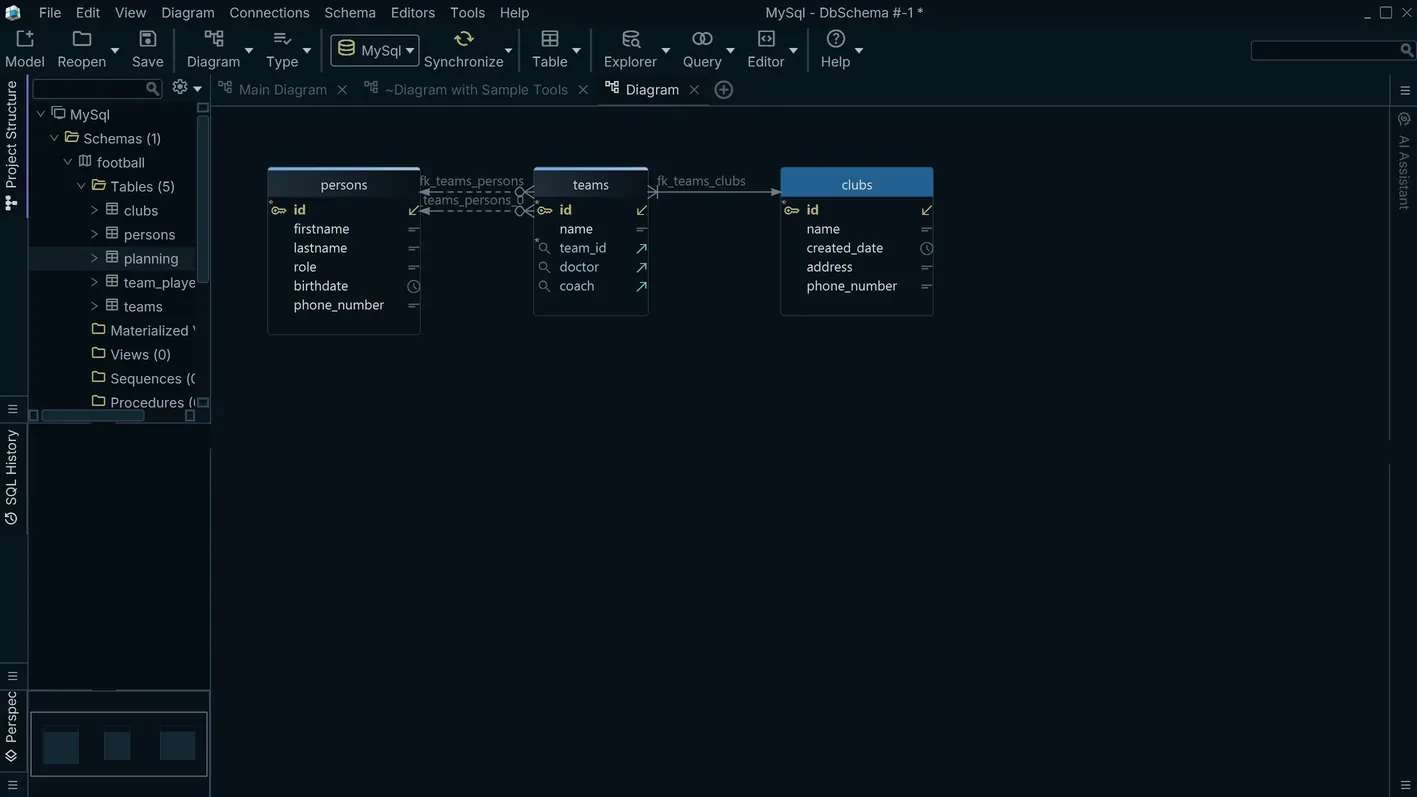
Phoenix SQL Query Builder for HBase Tables
DbSchema's query builder constructs Phoenix SQL SELECT statements visually, handling the row key prefix conditions that Phoenix uses to translate SQL predicates into efficient HBase row key scans. This allows engineers to build performant queries against HBase without deep knowledge of the underlying scan mechanics.
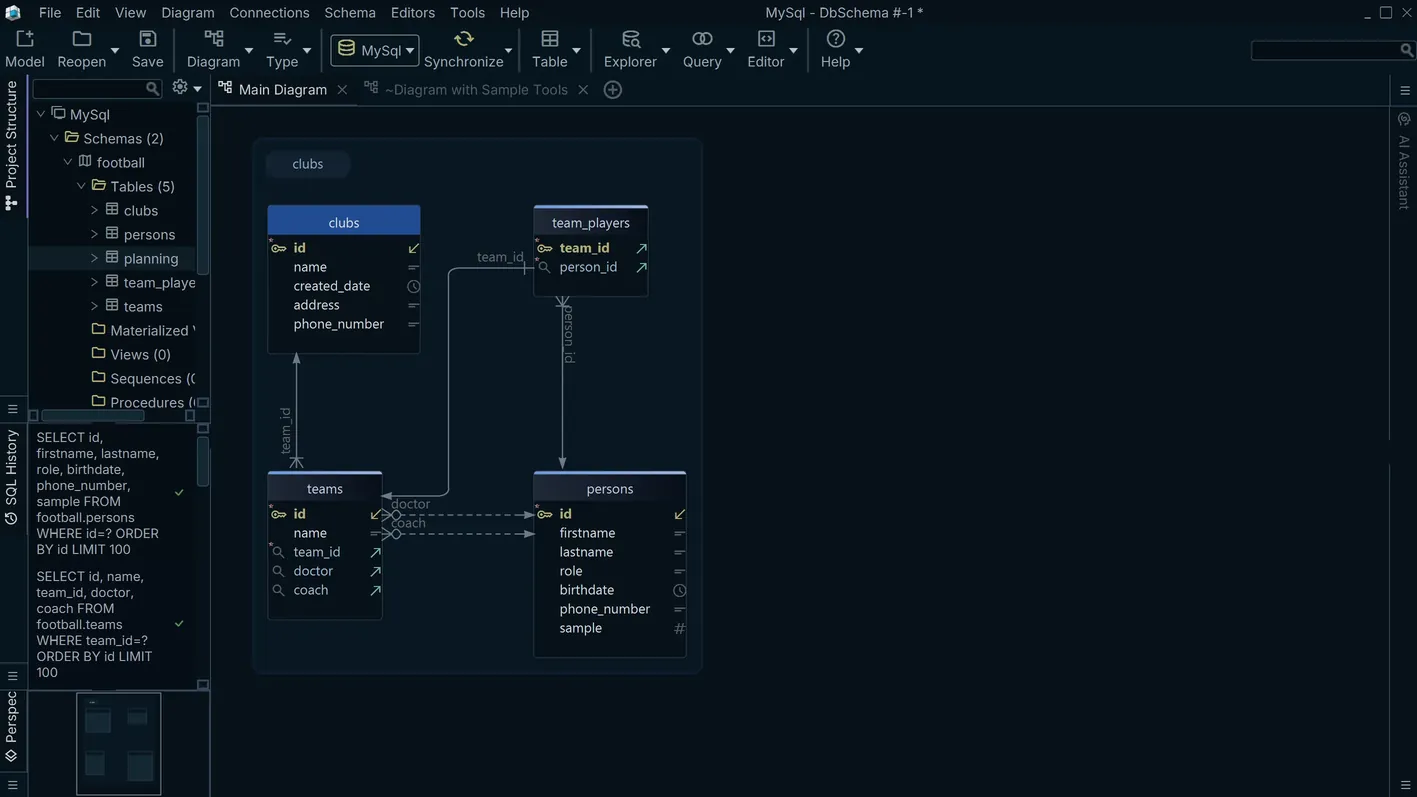
Data Explorer for Wide-Column HBase Tables
The DbSchema data explorer fetches rows from Phoenix-managed HBase tables and renders them in a
paginated tabular view. You can apply column filters and inspect individual cell values across
wide tables with many column families, without constructing HBase scan operations
manually.

Connect DbSchema to HBase via Apache Phoenix
HBase itself has no JDBC endpoint, so DbSchema goes through the Apache Phoenix SQL layer instead:
- Install DbSchema and open the connection dialog.
- Select the Phoenix/HBase driver type, then download the Phoenix thin client JDBC driver from the Phoenix release page and register it via Settings > Drivers — DbSchema does not bundle this driver.
- For the thin client, enter a JDBC URL of the form
jdbc:phoenix:zookeeper_host:2181:/hbase; the Phoenix query server must be running for the thin client to connect. Alternatively, use the Phoenix thick driver by supplying the full ZooKeeper quorum address directly. - On Amazon EMR, copy the ZooKeeper address from the EMR cluster summary page and confirm the security group permits inbound traffic on port 2181 before connecting.
- Connect — DbSchema reads the Phoenix-managed schema and displays column families and column definitions in the diagram.
Why Teams Use DbSchema with Apache HBase
- Column family visualization — see which columns belong to which column families in a structured schema view.
- Phoenix SQL access — build and execute Phoenix SQL queries visually without writing HBase scan operations.
- Row data inspection — browse wide-column table contents row by row from the data explorer with filter support.
- Schema documentation — document the Phoenix-managed HBase schema for teams that lack direct cluster access.
- EMR integration — connect to HBase on Amazon EMR using the cluster ZooKeeper endpoint and Phoenix thin client.
Ready to see your column families as a real schema instead of a ZooKeeper quorum string? Get DbSchema free and browse your HBase tables through Phoenix in minutes.
Related databases
Teams working with Apache HBase often use these engines too. Explore dedicated guides and JDBC setup for each.