Map Every Apache Druid Datasource on One Canvas
DbSchema gives Apache Druid teams a design-first workflow: import the existing schema as an interactive ER diagram, refine it visually, and ship every change as a reviewed SQL script.
Built for visual modeling, schema documentation, and deployment, with an offline model you can keep in Git, team collaboration, and documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Apache Druid Features Download Apache Druid JDBC Driver · All drivers
What happens after you download?
Get to your first Apache Druid schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Apache Druid or open a sample
Reverse engineer an existing Apache Druid database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Datasource and Segment Architecture
Apache Druid is a high-performance real-time OLAP database designed for sub-second queries on large event-driven datasets. Rather than traditional tables, Druid organizes data into datasources that are physically partitioned into time-based segments stored in deep storage such as Amazon S3 or HDFS. Each segment holds pre-aggregated rollup data and a columnar layout optimized for scan-heavy analytical workloads. DbSchema connects to Druid through the Apache Calcite Avatica JDBC protocol and introspects datasources as schema objects, rendering them in a visual schema diagram. You can annotate datasources, group them by subject area, and generate documentation that captures the column names, data types, and relationships modeled in your ingestion specs.
Download DbSchema Free See Apache Druid Features
Writing Analytical Druid SQL in the SQL Editor
Druid SQL is a full SQL dialect built on Apache Calcite that supports GROUP BY,
ORDER BY, time-floor functions like TIME_FLOOR(), and approximate aggregations
such as APPROX_COUNT_DISTINCT(). DbSchema's SQL editor connects over the Avatica protocol
and provides auto-completion for datasource and column names, making it straightforward to compose
time-partitioned aggregation queries without memorizing exact column spellings. Results are displayed in
a paginated grid with support for copying rows or exporting to CSV. You can organize saved queries by
datasource and share them across the team by committing the query files to version control alongside
your ingestion specs.
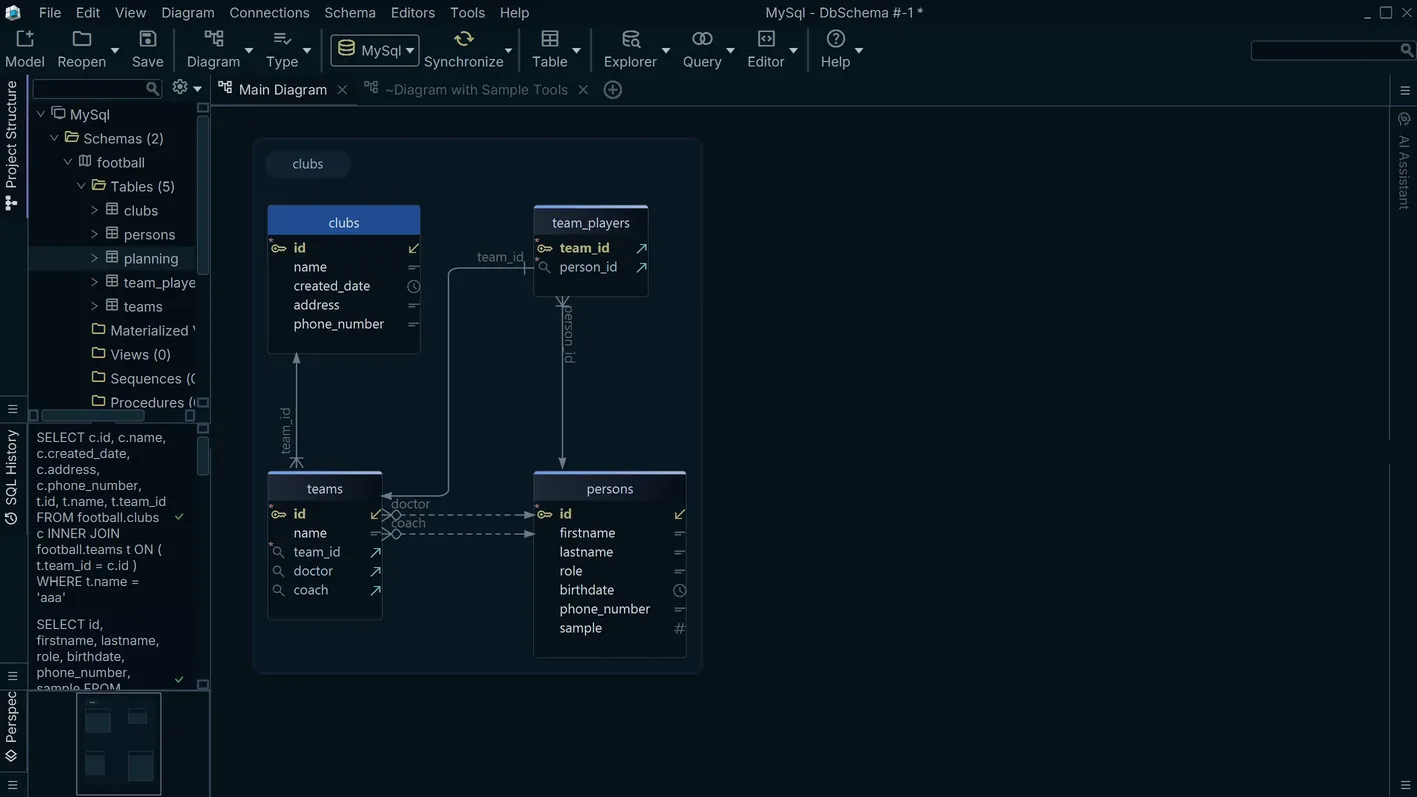
Exploring Ingested Datasets Visually
Once a Druid datasource has been ingested — whether via batch spec or Kafka-based streaming ingestion —
DbSchema's data explorer lets you sample rows, filter by time range or dimension value, and inspect the
exact column types that Druid has inferred during rollup. This is particularly useful for validating that
a new ingestion spec produced the expected schema: you can compare the column list in the data explorer
against the dimensionsSpec and metricsSpec in your ingestion JSON without
leaving DbSchema. The explorer also handles Druid's __time column natively, displaying
timestamps in a human-readable format.

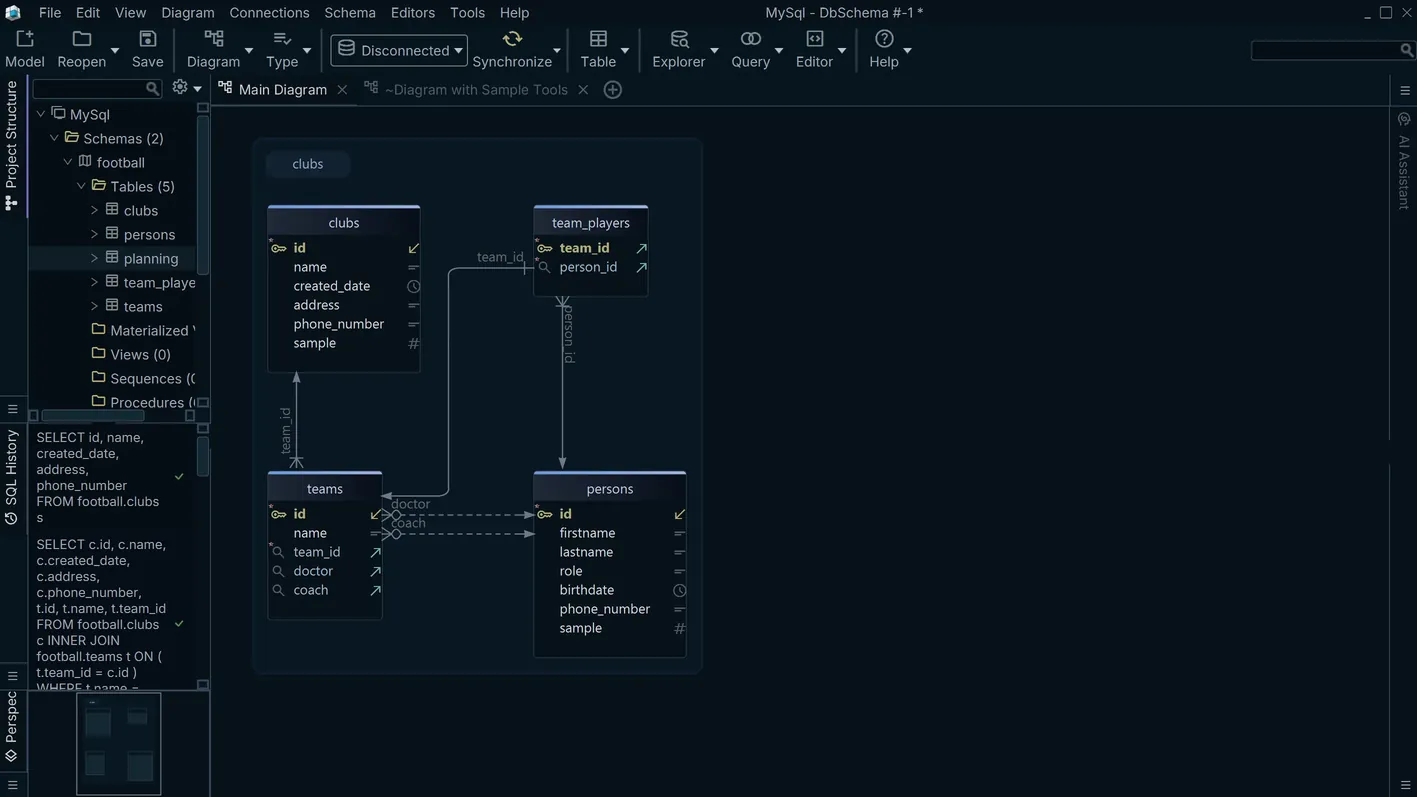
Set Up the Druid Broker Connection
- Install DbSchema — signing up is not required, and the same download unlocks Pro for 15 days.
- Grab the Avatica standalone JDBC JAR from the Apache Calcite Avatica releases page and load it into DbSchema's driver manager.
- Create a connection with the Apache Calcite Avatica remote JDBC driver
(
org.apache.calcite.avatica.remote.Driver), pointed at Druid's Broker node. - Use a URL following the pattern
jdbc:avatica:remote:url=http://broker:8082/druid/v2/sql/avatica/, wherebrokeris the Broker's hostname or IP and8082is the default Broker port. For secured clusters, replacehttpwithhttpsand supply credentials in the connection dialog. - Connect — DbSchema introspects the datasources and renders them as a schema diagram.
Where DbSchema Fits in a Druid Analytics Stack
- Render Druid datasources as visual schema diagrams to communicate the data model to analysts unfamiliar with ingestion specs.
- Draft and verify
TIME_FLOORand approximate aggregation SQL in the editor first, then hand the finished query to a BI tool connection. - Validate ingestion results by sampling datasource rows in the data explorer right after a batch job completes.
- Document multi-datasource analytics pipelines with annotated schema layouts exportable as HTML or PDF.
- Design new datasource schemas offline before configuring ingestion specs, reducing costly re-ingestion cycles.
Trying to keep a dozen datasources and their rollup columns straight in your head? Download DbSchema for free and turn your Druid Broker's catalog into a diagram the whole analytics team can read.
Related databases
Teams working with Apache Druid often use these engines too. Explore dedicated guides and JDBC setup for each.