DbSchema for Dremio: Visualize the Lakehouse Data Model
Build a clearer workflow for Dremio: reverse engineer existing schemas into interactive ER diagrams, model changes visually, and generate reviewed SQL scripts before deployment.
DbSchema is built for visual modeling, schema documentation, and deployment. Keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Dremio Features Download Dremio JDBC Driver · All drivers
What happens after you download?
Get to your first Dremio schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Dremio or open a sample
Reverse engineer an existing Dremio database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Lakehouse Architecture and Schema Visualization
Dremio is a SQL lakehouse engine that lets you query data directly from cloud object stores such as Amazon S3, Azure Data Lake Storage, and Google Cloud Storage without moving or copying data into a separate database. The platform organizes objects into sources (connections to external storage systems), spaces (personal and shared virtual workspaces), and virtual datasets (saved SQL views over source data). DbSchema connects to Dremio using the Dremio JDBC driver over the Arrow Flight SQL protocol and introspects spaces and virtual datasets as schema objects, rendering them in a visual diagram. This gives your team a unified view of the virtual data model regardless of how many underlying storage sources it spans.
Download DbSchema Free See Dremio Features
Writing SQL Against Dremio Data Sources
Dremio exposes a full ANSI SQL interface that supports joins across sources, window functions,
FLATTEN for nested arrays, and CONVERT_FROM for parsing JSON and Parquet
fields. DbSchema's SQL editor connects over the Dremio JDBC driver and provides auto-completion for
space, virtual dataset, and column names, making it straightforward to compose queries that join an
S3 Parquet file with an Azure SQL table without writing raw Dremio SQL from scratch. Query results
appear in a paginated grid with support for exporting to CSV. Saved queries can be organized by source
or project space and committed to version control alongside your data pipeline definitions.
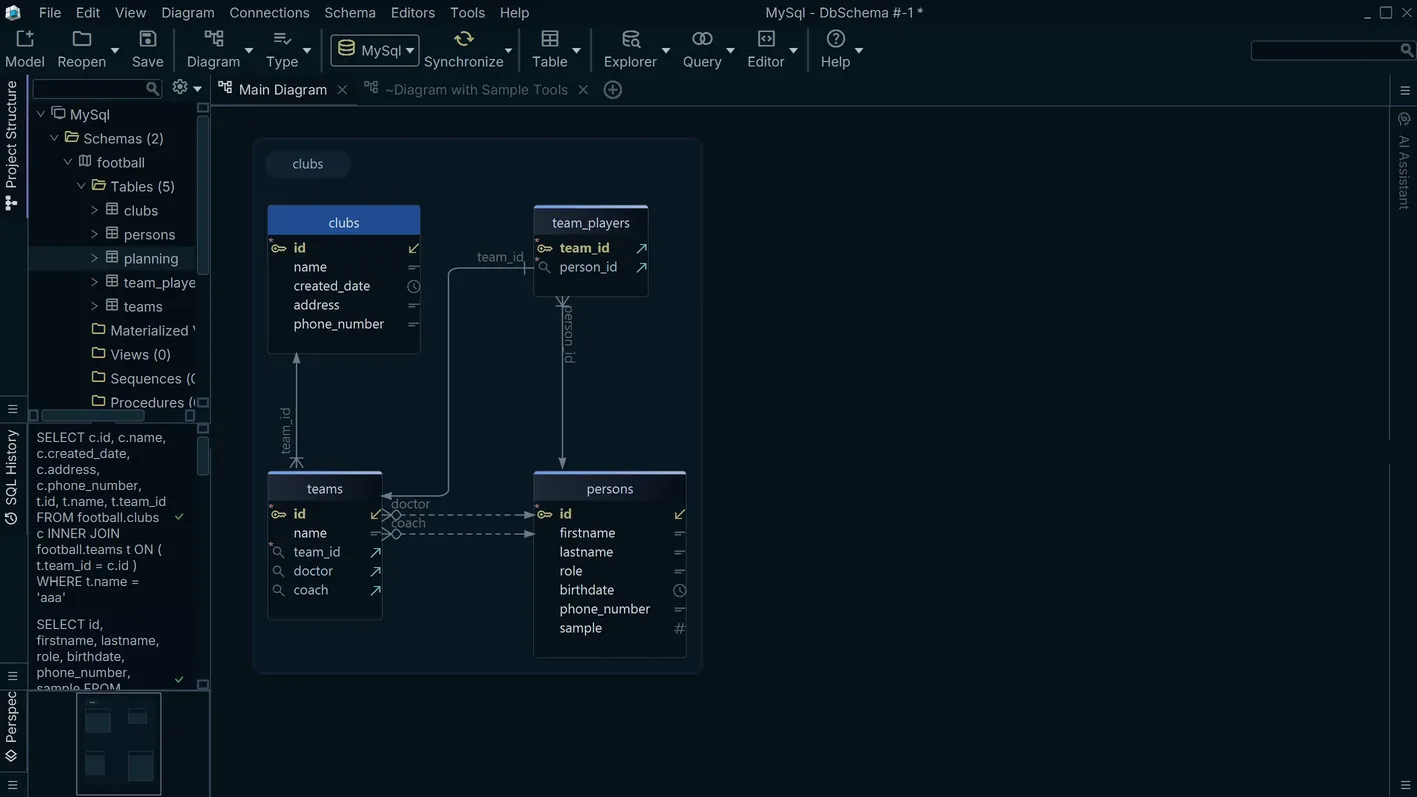
Exploring Dremio Virtual Datasets with the Data Explorer
The DbSchema data explorer lets you browse the contents of any Dremio virtual dataset or raw source table interactively. You can filter rows by column value, sort by any field, and page through results without writing SQL, which is particularly useful when validating that a new virtual dataset returns the correct data after a reflection rebuild or source schema change. Dremio's reflection acceleration means that data explorer queries against pre-reflected datasets return results in milliseconds even over large Parquet file collections, giving a smooth browsing experience directly from DbSchema.

Set Up the Dremio JDBC Connection
Getting from a fresh DbSchema install to a browsable Dremio lakehouse diagram takes a handful of steps:
- Install DbSchema on Windows, macOS, or Linux — the download requires no account.
- Open the connection dialog, pick Dremio, and register the Dremio JDBC driver JAR
(
com.dremio.jdbc.Driver) downloaded from the Dremio download center. - Enter the direct Arrow Flight host and port 31010, matching the JDBC URL
jdbc:dremio:direct=localhost:31010, along with your Dremio username and password (or a personal access token for Dremio Cloud). - For Dremio Cloud, swap in the Dremio Cloud endpoint and switch to token-based authentication.
- Connect — DbSchema introspects spaces and virtual datasets and lays out the first diagram.
Reflections and query acceleration operate transparently through the JDBC connection, so DbSchema automatically benefits from pre-built reflections on queried datasets without any extra configuration.
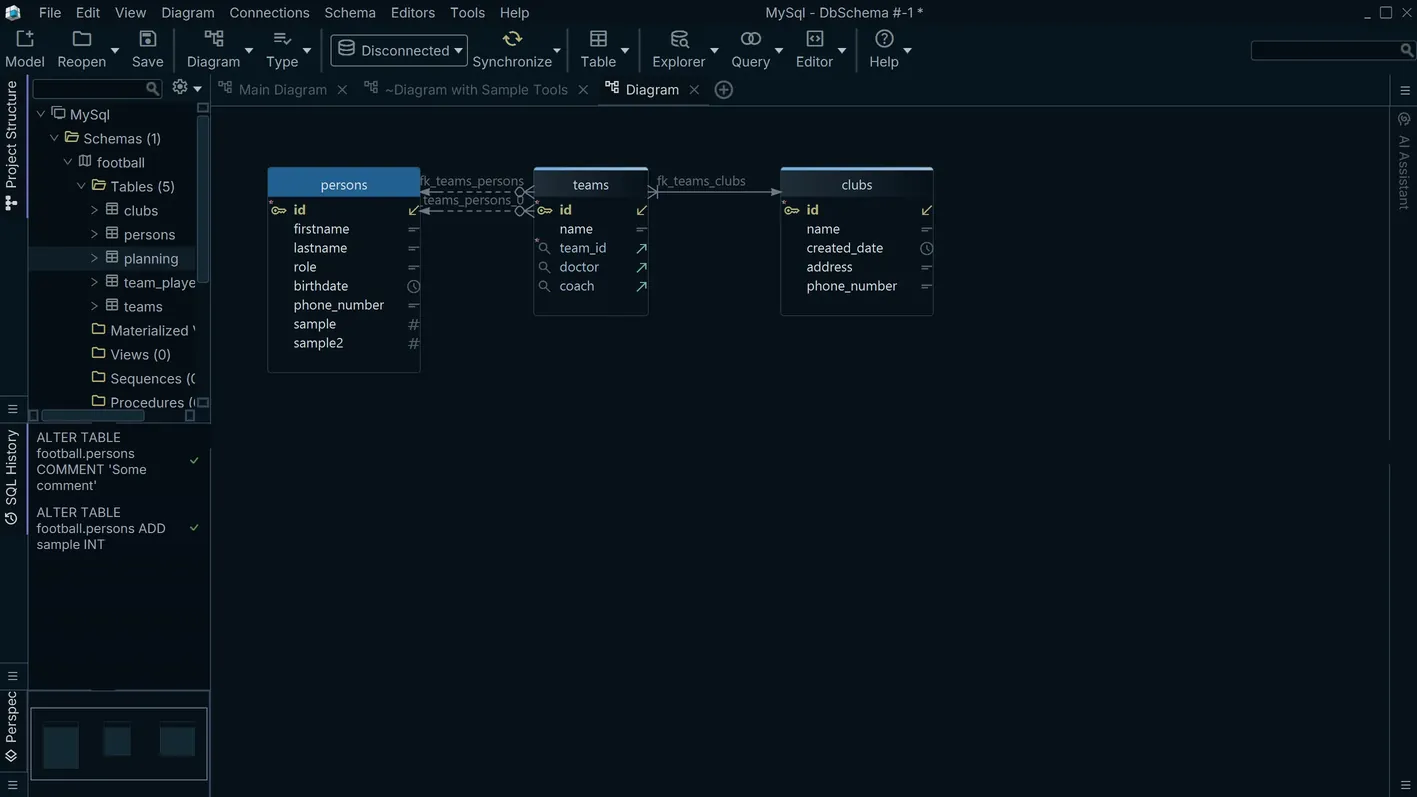
What Dremio Teams Gain From DbSchema
- Visualize Dremio's space and virtual dataset hierarchy as a schema diagram to communicate the lakehouse data model to BI teams.
- Write and test SQL that joins datasets across S3, ADLS, and relational sources in DbSchema's SQL editor before publishing virtual datasets.
- Browse virtual dataset contents in the data explorer to validate reflection accuracy after schema changes in underlying sources.
- Generate HTML or PDF documentation for Dremio virtual datasets to serve as a data catalog supplement for governed lakehouse environments.
- Design new virtual dataset schemas in DbSchema's offline model and share them for team review before deploying to Dremio.
- Connect to both Dremio Software (on-premises) and Dremio Cloud from a single DbSchema project, switching environments in the connection manager.
Once your spaces and virtual datasets are mapped to a single diagram, tracing a join across S3 and ADLS sources stops being guesswork. Download DbSchema and turn your Dremio lakehouse into a browsable schema in a few minutes.
Related databases
Teams working with Dremio often use these engines too. Explore dedicated guides and JDBC setup for each.