Antijoins, semijoins, and some generalized quantifiers in SQL | DbSchema
Finding rows in one table that don't match any rows in another table is a common task, corresponding to questions like:
- Which customers haven't placed any orders?
- Which orders have no shipments?
The SQL standard does not offer a built-in shortcut to write queries like these, which are usually called antijoins. A few database systems (such as Spark) support that term as a keyword in their SQL dialect.
In this article, we shall take a closer look at antijoins and some related problems, using both standard SQL and the visual query builder of DbSchema.
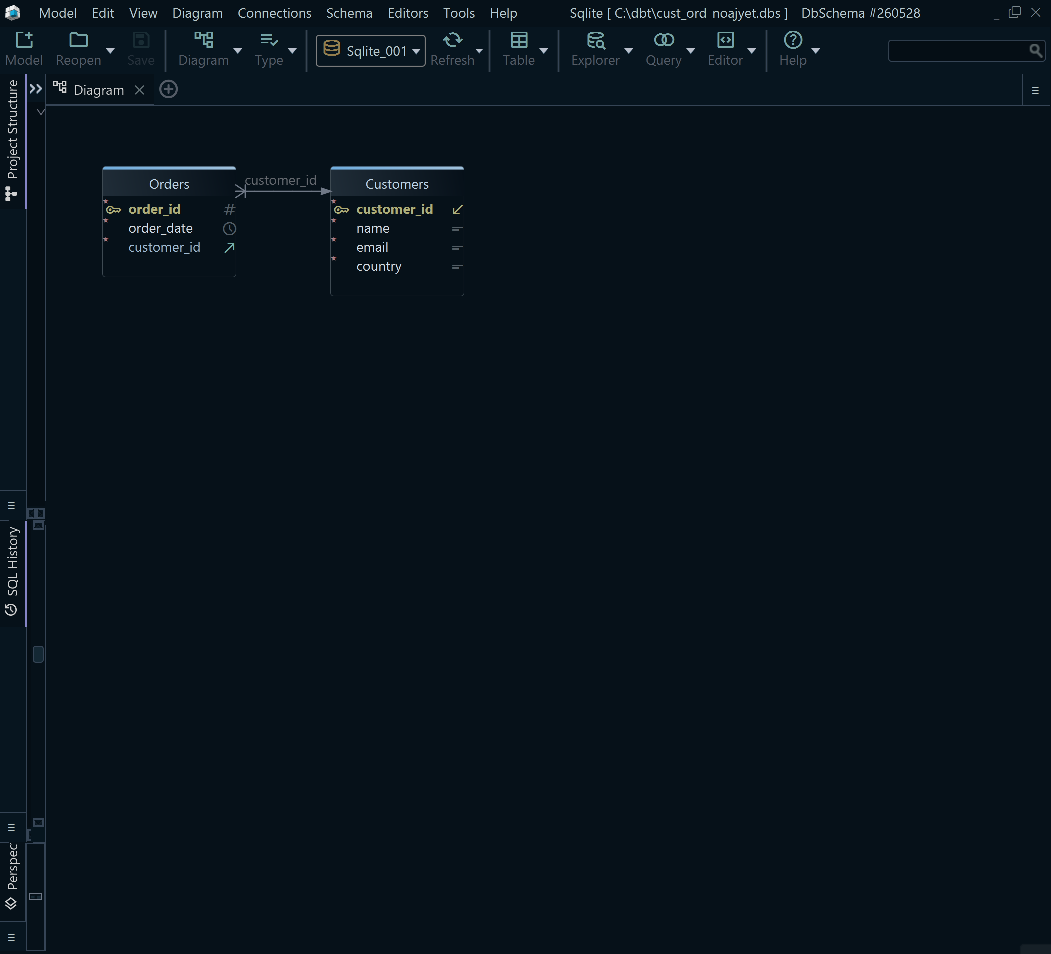
We shall use as running example a database with two tables: customers and
orders. The relationship between these two entities is enforced by a foreign key constraint on customer_id in the Orders table.

If you'd like to review the foreign key concept, including how you can visually draw such diagrams in DbSchema, please refer to our prior tutorial on foreign keys.
'Not exists' using the DbSchema Query Builder
The DbSchema Query Builder allows you to easily construct an antijoin by picking 'not exists' on the connective arrow that links two tables.
In the SQL generated by DbSchema query builder, namely
SELECT c.customer_id, c.name, c.email, c.country
FROM Customers c
WHERE NOT EXISTS (
SELECT 1
FROM Orders o
WHERE o.customer_id = c.customer_id )
the inner SELECT 1 query refers to the outer table Customers alias c. This
is called a correlated subquery, which produces fairly intuitive SQL that
spells out what should be returned for every customer. SELECT 1 here merely
returns the value 1 if there are any matching customer_id values in the
Orders table for every customer in the outer query.
Brief diversion to set operators
A correlated subquery is not the only approach to the problem. If you are
familiar with basic set theory, the SQL set operator EXCEPT (only available
as MINUS in older Oracle versions, 19 and before) looks like a quicker
solution to write down, especially if you're only interested in the IDs of the
customers.
SELECT customer_id FROM Customers
EXCEPT
SELECT customer_id FROM Orders;
There is a downside to this approach if you need more than the customer_id
value from Customers though. The SQL set operators only work on tables with
the exact same number of columns. And these columns must be of compatible
types. Since the Customer and Orders tables don't really have other columns in
common besides customer_id, to get other information about the customers
with no orders, we need another outer query, such as
SELECT * FROM Customers WHERE customer_id IN (
SELECT customer_id FROM Customers
EXCEPT
SELECT customer_id FROM Orders
);
Antijoins using outer joins
There is a third way to write antijoins using left (or right) outer joins and selecting only the rows corresponding to the null values found in the referencing table (Orders in our example) in the so joined tables.
This type of query can also be built visually with the DbSchema query builder.

The resulting SQL is slightly shorter, but requires a good recall of outer joins in order to comprehend.
SELECT c.customer_id, c.name, c.email, c.country
FROM Customers c
LEFT OUTER JOIN Orders o ON ( o.customer_id = c.customer_id )
WHERE o.order_id IS NULL
Semijoins, briefly
You may have noticed already in our DbSchema demos that Exists may also be
selected instead of Not exists on the arrows connecting tables in the
DbSchema query builder. The resulting queries are obvious counterparts to the
antijoins. And they are usually called semijoins. In fact, some authors insist
on calling antijoins anti-semijoins to emphasize that the antijoins are not the
counterparts of some other kind of join.
The 'semi' prefix in the name of semijoin (and anti-semijoin, if you prefer to call them that) is meant to emphasize that only columns from one of the tables are included in the result of semijoin.
To recap, here is how semijoins and antijoins relate to other kinds of joins, as well as to set operators, in the form of a diagram.
| Output | SQL set operators (match on all attributes ) | SQL join operators (match on some attributes) |
|---|---|---|
| A | R EXCEPT S | R left anti-semijoin S |
| B (roughly) | R INTERSECT S | R INNER JOIN S or semijoins(depends on attributes projected) |
| C | S EXCEPT R | R right anti-semijoin S |
| A, B | R | R LEFT OUTER JOIN S |
| B, C | S | R RIGHT OUTER JOIN S |
| A, B, C | R UNION S | R FULL OUTER JOIN S |
In the summarizing table above, inner joins and semijoins occupy the same
cell. This happens because there are in fact two dimensions of the output
when it comes to joins: which rows are we interested in and which attributes.
For antijoins, it is natural to keep (project on) just the attributes of the table we are
subtracting from, since the subtracted table will have null attributes in the
matched column. For inner joins and semijoins there are however at least three
interesting choices: keep attributes from R, keep attributes from S, or from both.
| Output rows | Output attributes | SQL join operators |
|---|---|---|
| B | A, B | R left semijoin S |
| B | B, C | R right semijoin S |
| B | A, B, C | R INNER JOIN S |
Threshold counts (generalized quantifiers)
Instead of considering only the existence or non-existence of customers with orders, we may be interested in more nuanced categories, such as customers with few orders, where "few" is defined by a specified numeric threshold. To tackle such a problem, we can easily change the previous query we built in DbSchema query builder to something like the following.

Resulting in generated SQL like:
SELECT c.customer_id, c.name, c.email, c.country, count(DISTINCT o.order_id)
FROM Customers c
LEFT OUTER JOIN Orders o ON ( o.customer_id = c.customer_id )
GROUP BY c.customer_id, c.name, c.email, c.country
HAVING count(DISTINCT order_id) < 2;
In logic, 'there exists' (at least one) is called a quantifier. More general constraints like "there exist fewer than three" that we're dealing with in this section are called generalized quantifiers.
Finally, it is possible to write a correlated query equivalent of the above.
SELECT c.customer_id, c.name, c.email, c.country,
(SELECT COUNT(DISTINCT o.order_id) FROM Orders o
WHERE o.customer_id = c.customer_id) AS order_count
FROM Customers c
WHERE order_count < 2;
Such correlated subqueries are more difficult to represent graphically because they allow arbitrarily long SQL expressions to appear in column positions.
There is one additional syntactic gotcha for this last query. While it runs fine on SQLite,
it is rejected by a good number of popular database systems, including Oracle, Postgres, SQL Server etc.
The latter apply
a stricter scoping rule to the order_count alias, making it unavailable in the WHERE clause.
A fix for this issue is to wrap the previous query, minus its where clause, in another query which applies just the
WHERE filter. But this is a bit of an eye sore.
SELECT * FROM (
SELECT c.customer_id, c.name, c.email, c.country,
(SELECT COUNT(DISTINCT o.order_id) FROM Orders o
WHERE o.customer_id = c.customer_id) AS order_count
FROM Customers c
)
WHERE order_count < 2;
Conclusion
In this article, we explored antijoins, a common SQL pattern used to find rows
in one table that have no matching rows in another. Using the Customers and
Orders example, we demonstrated several equivalent approaches, including
correlated NOT EXISTS subqueries, set operators such as EXCEPT, and
selections on left outer joins. We also showed how several of these techniques can
be constructed visually using the DbSchema Query Builder.
Along the way, we briefly introduced the related concept of semijoins and extended the discussion beyond simple existence tests to count-based conditions, such as finding customers with fewer than a specified number of orders. These generalized-quantifier queries illustrate how SQL and the DbSchema Query Builder can express a wide range of relationship-based constraints between tables.
While different database systems and their query optimizers may favor one formulation over another, understanding these alternative representations helps you choose the style that is most readable and maintainable for your use case. Whether you prefer writing SQL by hand or building queries visually in DbSchema, antijoins, semijoins and their count-based generalizations are essential tools for querying relational data effectively.







