Yellowbrick Distribution Keys, Mapped Visually
DbSchema gives Yellowbrick teams a design-first workflow: import the existing schema as an interactive ER diagram, refine it visually, and ship every change as a reviewed SQL script.
Built for visual modeling, schema documentation, and deployment, with an offline model you can keep in Git, team collaboration, and documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Yellowbrick Features Download Yellowbrick JDBC Driver · All drivers
What happens after you download?
Get to your first Yellowbrick schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Yellowbrick or open a sample
Reverse engineer an existing Yellowbrick database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Yellowbrick's MPP Columnar Architecture and Schema Visualization
Yellowbrick is a cloud and hybrid data warehouse designed for high-performance analytical workloads. Its MPP (Massively Parallel Processing) architecture distributes query execution across many nodes, with each node storing columnar data on NVMe flash storage. Adaptive compression reduces storage footprint while keeping frequently accessed data in memory for scan-heavy analytical queries. Yellowbrick supports hybrid deployments — the same software runs on-premises in your data center and in public cloud, giving enterprises the flexibility to keep sensitive data on-site while scaling burst workloads to the cloud.
Download DbSchema Free See Yellowbrick Features
Yellowbrick uses a PostgreSQL-compatible wire protocol, which means standard JDBC clients and tools work without modification. DbSchema connects via the Yellowbrick JDBC driver and reverse-engineers the warehouse schema — tables, views, distribution keys, sort keys, and workload management resource groups — into a visual diagram. Distribution key information is particularly valuable in the diagram because it shows which column drives data placement across nodes, informing join strategies and identifying potential skew.
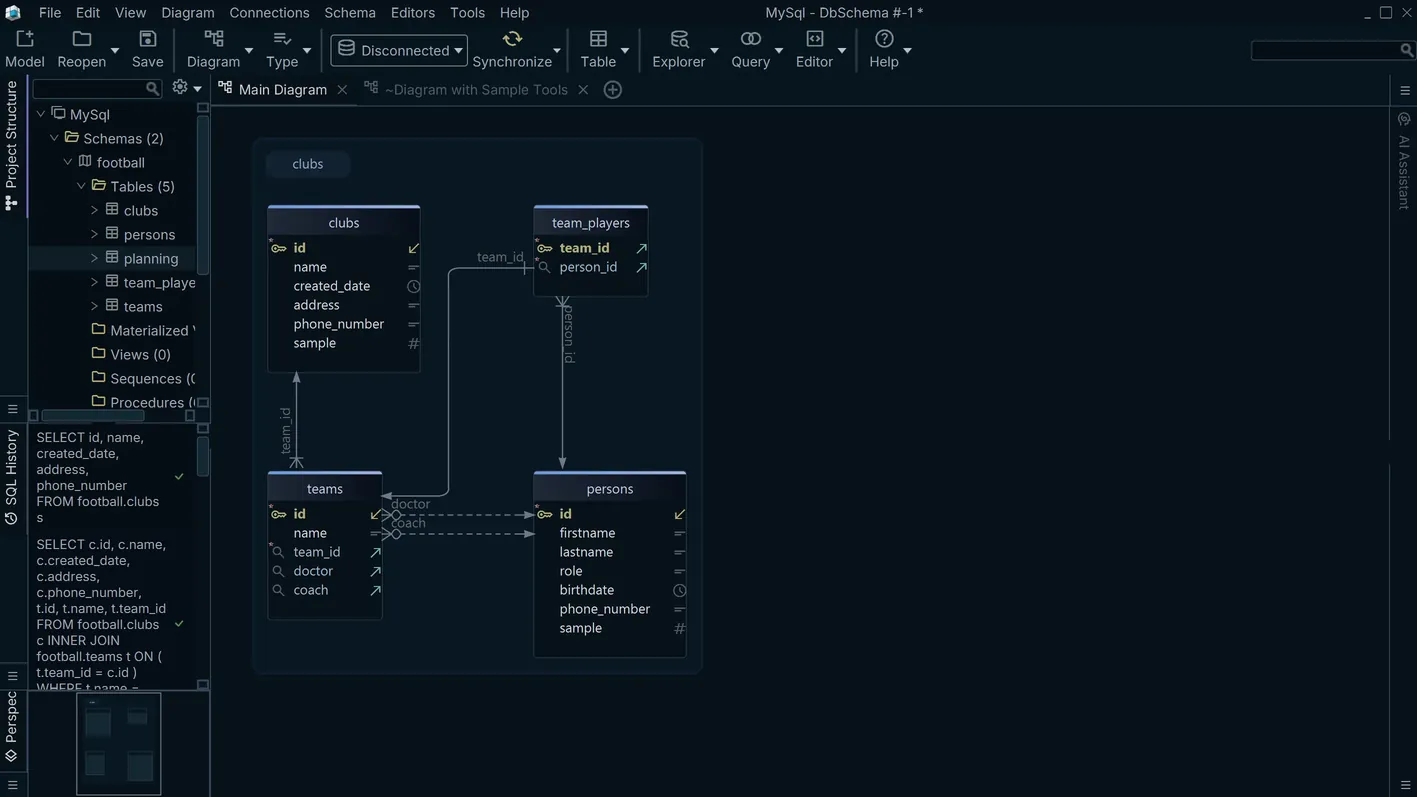
Writing Complex Analytical SQL Against Yellowbrick
Yellowbrick supports the full spectrum of analytical SQL — multi-table joins, complex aggregations, window
functions, CTEs, and ANSI SQL set operations. Its PostgreSQL-compatible dialect also supports
COPY for bulk loading and advanced data type handling. DbSchema's SQL editor connects via the
Yellowbrick JDBC driver and provides a full query environment where you can iterate on analytical SQL and
review results in the built-in results grid.
Yellowbrick's workload management (WLM) system assigns queries to resource pools based on user, query type,
or explicit routing hints. When authoring queries in DbSchema's editor, you can add WLM routing hints as SQL
comments (e.g., /* ybworkload:adhoc */) to control resource allocation during interactive
development. EXPLAIN output shows the distributed query plan including redistribution operations
and node-level sort/aggregate steps, helping you identify expensive data movement across nodes.
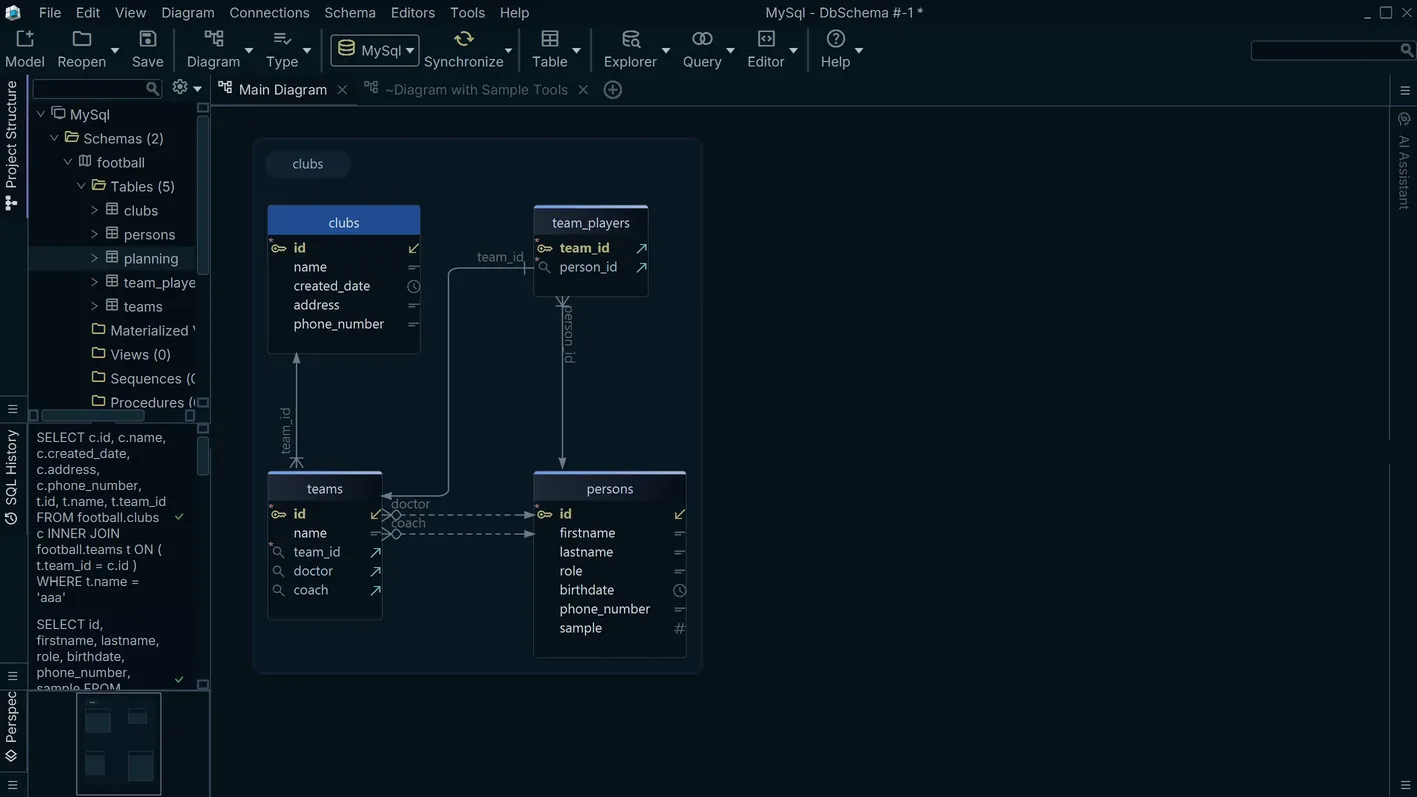
Exploring Large-Scale Yellowbrick Datasets
The DbSchema data explorer lets you browse Yellowbrick table data row by row without writing SQL. Column-level filtering is pushed down to Yellowbrick where possible, leveraging its columnar storage and zone maps to avoid full scans. This makes the explorer practical even on very large tables — filtering by date or ID range returns results quickly because Yellowbrick's storage engine skips non-matching column segments based on min/max zone map statistics.
The explorer also helps with schema-level investigations: you can inspect distribution key columns to verify that data is distributed evenly across nodes, or check sort key columns to confirm that insert order aligns with the declared sort. Bulk load connectors for Amazon S3 and Azure Data Lake Storage (ADLS) bring external data into Yellowbrick; the explorer lets you verify that loaded tables have the expected row structure and column values before running production reports against them.

Yellowbrick Connection Setup in DbSchema
Yellowbrick's PostgreSQL-compatible protocol still needs its own driver — here is the full sequence:
- Download and install DbSchema.
- Select Yellowbrick from the database list and provide the Yellowbrick JDBC driver
(
yellowbrick-jdbc-*.jar) from the Yellowbrick support portal — driver classcom.yellowbrick.jdbc.Driver. Although Yellowbrick uses port5432(the same as PostgreSQL), it is not interchangeable with the standard PostgreSQL JDBC driver. - Enter the host and port
5432, giving the JDBC URLjdbc:yellowbrick://yellowbrick-host:5432/mydb. - Supply your Yellowbrick username and password. SSL is strongly recommended and can be enforced by
adding
?sslmode=requireto the JDBC URL. - Connect — DbSchema reverse-engineers tables, views, distribution keys, sort keys, and workload management resource groups into the diagram.
For hybrid deployments where Yellowbrick runs on-premises behind a firewall, ensure that the DbSchema
client host can reach port 5432 on the Yellowbrick manager node. Yellowbrick Cloud
deployments include a public hostname and require SSL by default, with credentials managed through the
Yellowbrick Cloud console.
Yellowbrick Warehouses Run Better with DbSchema
- Visualizes distribution and sort key definitions alongside table structures, enabling faster query optimization and skew analysis.
- Provides a PostgreSQL-familiar SQL editor for an MPP warehouse, reducing the learning curve for analysts experienced with PostgreSQL.
- Makes large dataset exploration practical through column-level pushdown filtering backed by Yellowbrick's zone maps.
- Supports hybrid cloud/on-premises connection profiles in one tool, useful for enterprises with data in both environments.
- Generates offline warehouse schema documentation for governance, compliance, and architecture review purposes.
- Works with Yellowbrick's WLM resource pools, enabling controlled resource usage during interactive analytical sessions.
Distribution keys and sort keys are hard to reason about from catalog queries alone. Download DbSchema for free and see your Yellowbrick warehouse's data placement decisions laid out on a diagram.
Related databases
Teams working with Yellowbrick often use these engines too. Explore dedicated guides and JDBC setup for each.