Databricks Lakehouse Schema Design and SQL Workspace
Connect DbSchema to Databricks and turn the live schema into an editable visual model: explore relationships in interactive ER diagrams, plan changes on the canvas, and generate reviewed SQL scripts for deployment.
The workflow is designed for visual modeling, schema documentation, and deployment — keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Databricks Features Download Databricks JDBC Driver · All drivers
What happens after you download?
Get to your first Databricks schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Databricks or open a sample
Reverse engineer an existing Databricks database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Visualizing the Databricks Unity Catalog Hierarchy
Databricks Unity Catalog organizes objects in a three-level namespace: catalog, schema, and table. As Delta Lake deployments mature, this hierarchy can encompass dozens of catalogs and hundreds of schemas across a single workspace. DbSchema connects to a Databricks SQL Warehouse and renders the catalog-schema-table structure as an ER diagram, providing a navigable view that is difficult to obtain from the Databricks UI alone. Data architects use this to understand cross-schema dependencies, trace data lineage at the schema level, and plan restructuring work across the lakehouse.
Download DbSchema Free See Databricks Features
Run Spark SQL Queries from a Desktop Client
DbSchema's visual query builder generates Spark SQL statements from your table and column selections, running them against a Databricks SQL Warehouse. Analysts get a point-and-click query interface without needing a notebook or knowledge of Spark SQL syntax.
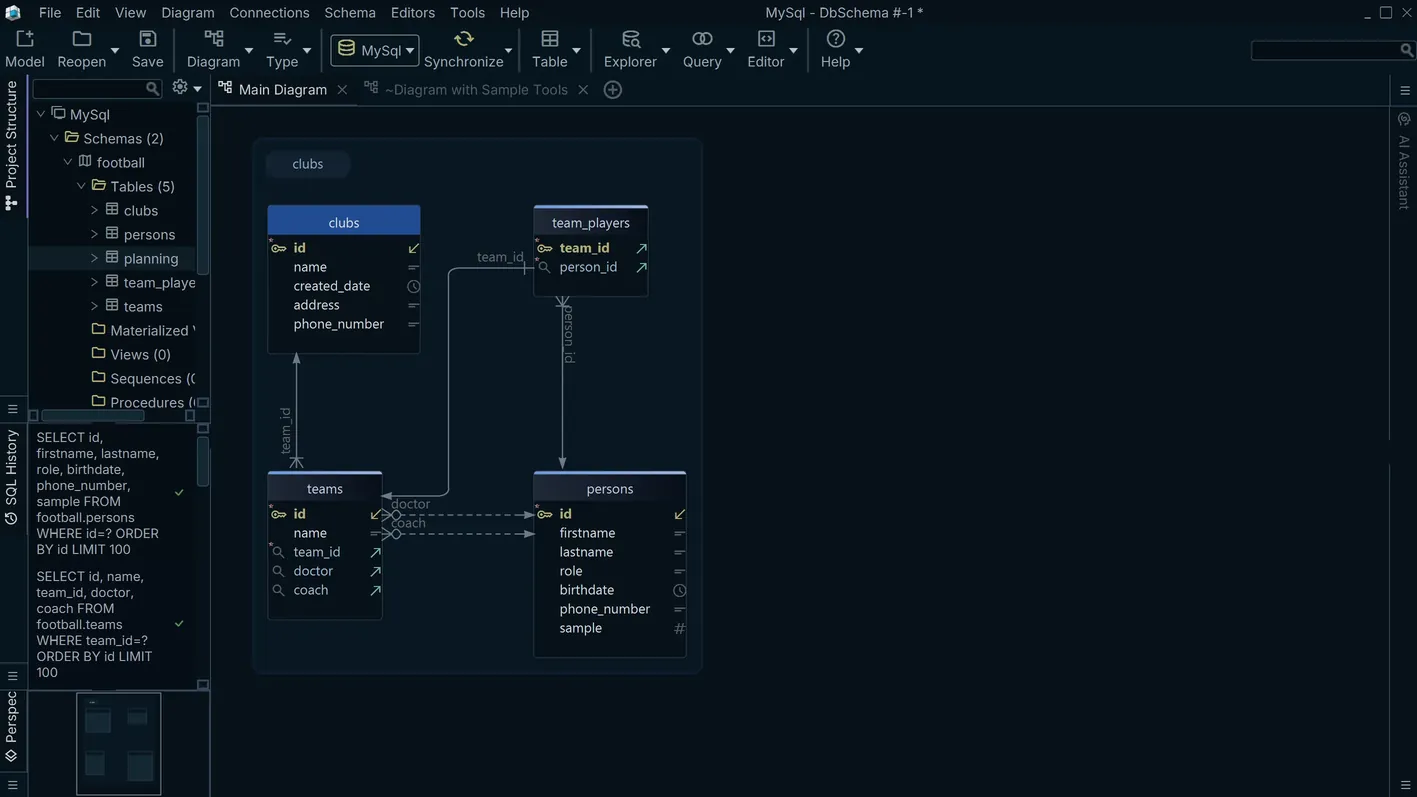
Explore Delta Table Data Interactively
The data explorer in DbSchema lets you browse rows in any Delta table, filter by column values, and page through results without opening a Databricks notebook. This is useful for verifying ingestion jobs, auditing data quality after pipeline runs, or sampling table contents during schema investigation.

Document the Delta Lake Schema
DbSchema generates HTML schema documentation from your Databricks Unity Catalog metadata, embedding ER diagrams, table definitions, and column descriptions into a shareable export. Share a single build with team members who need schema context without direct Databricks access.
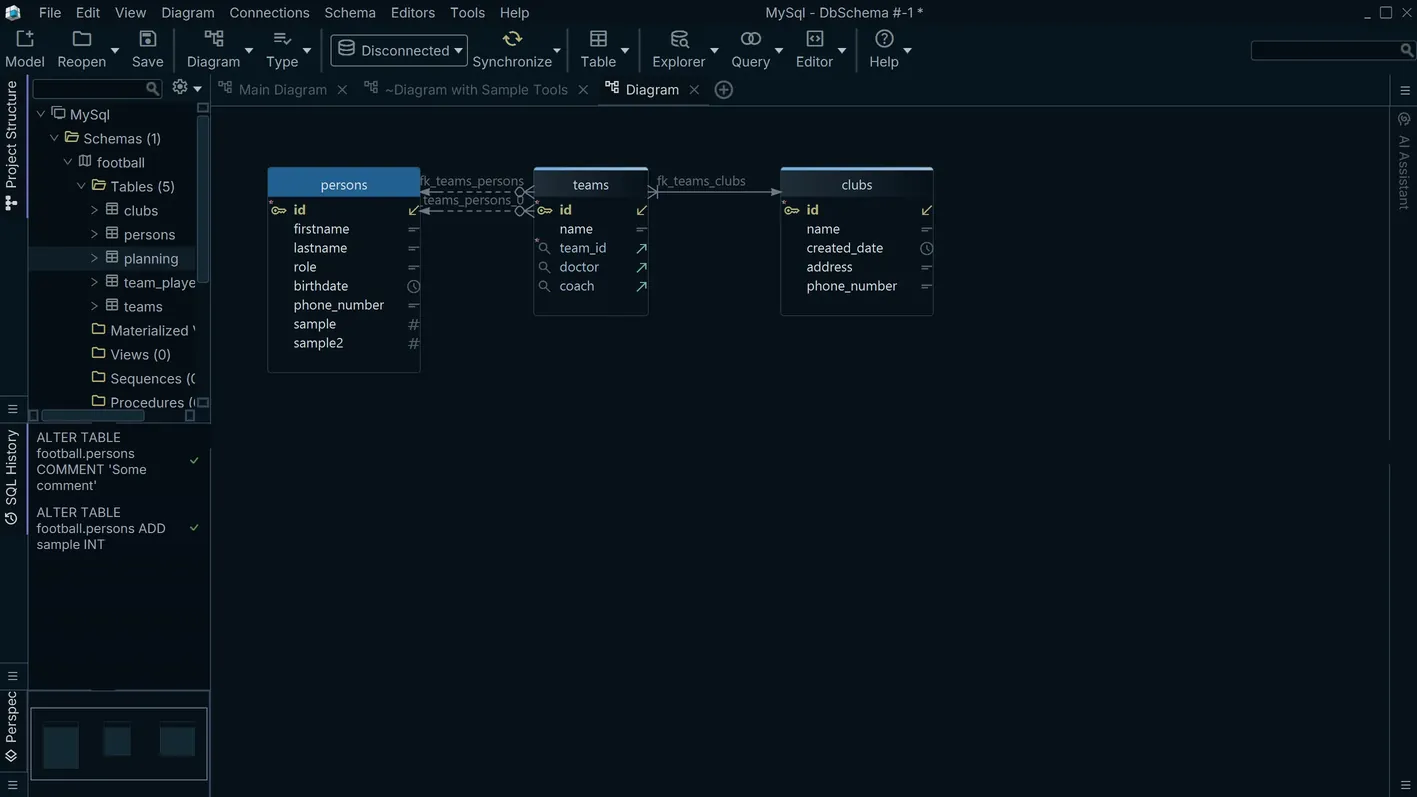
How to Connect a Databricks SQL Warehouse
- Install DbSchema via the download page.
- Download the Databricks JDBC driver from the Databricks driver download page and register it in DbSchema's driver manager.
- Build the JDBC URL:
jdbc:databricks://workspace.azuredatabricks.net:443/default;httpPath=/sql/1.0/warehouses/warehouse_id, wherehttpPathpoints to your SQL Warehouse. - Authenticate using a Personal Access Token as the JDBC password field, then connect.
To target a specific Unity Catalog namespace, set the catalog and schema
properties in DbSchema's advanced connection parameters panel.
Why Teams Use DbSchema with Databricks
- Navigate Unity Catalog's three-level namespace as a visual ER diagram
- Query Delta tables from a desktop client without opening a Databricks notebook
- Explore and validate table data interactively after pipeline runs
- Generate schema documentation for the Delta Lake layer across catalogs
- Design schema changes to Unity Catalog objects and preview DDL before execution
Bring lakehouse schemas into view: download DbSchema free and diagram your Unity Catalog structure from the first connection.
Tutorials and guides
Frequently asked questions
Related databases
Teams working with Databricks often use these engines too. Explore dedicated guides and JDBC setup for each.