A Visual Workbench for Apache Hive Metastore Schemas
Connect DbSchema to Apache Hive and turn the live schema into an editable visual model: explore relationships in interactive ER diagrams, plan changes on the canvas, and generate reviewed SQL scripts for deployment.
The workflow is designed for visual modeling, schema documentation, and deployment — keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Apache Hive Features Download Apache Hive JDBC Driver · All drivers
What happens after you download?
Get to your first Apache Hive schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Apache Hive or open a sample
Reverse engineer an existing Apache Hive database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Desktop GUI for Apache Hive Data Warehouse Schemas
Apache Hive organizes Hadoop HDFS data into databases, tables, and partitions stored in the Hive
metastore. While Hive supports a SQL-like query language (HiveQL), navigating the metastore and
understanding the full schema structure typically requires beeline or a Hue web interface.
DbSchema connects to Hive via HiveServer2 and provides a desktop GUI for visualizing the metastore
schema, running HiveQL queries, and generating documentation for the whole data warehouse team.
Because partitioned tables backed by ORC or Parquet files can grow to include many partitions and
columns over time, having a single diagram of the metastore structure helps teams keep track of how
the warehouse schema has evolved.
Download DbSchema Free See Apache Hive Features
Visual Schema Explorer for the Hive Metastore
DbSchema reads the Hive metastore through the HiveServer2 JDBC interface and presents databases, tables,
partitions, and column definitions as an interactive schema diagram. Data engineers and analysts can
quickly explore the Hive schema structure without using the beeline CLI or Hue.
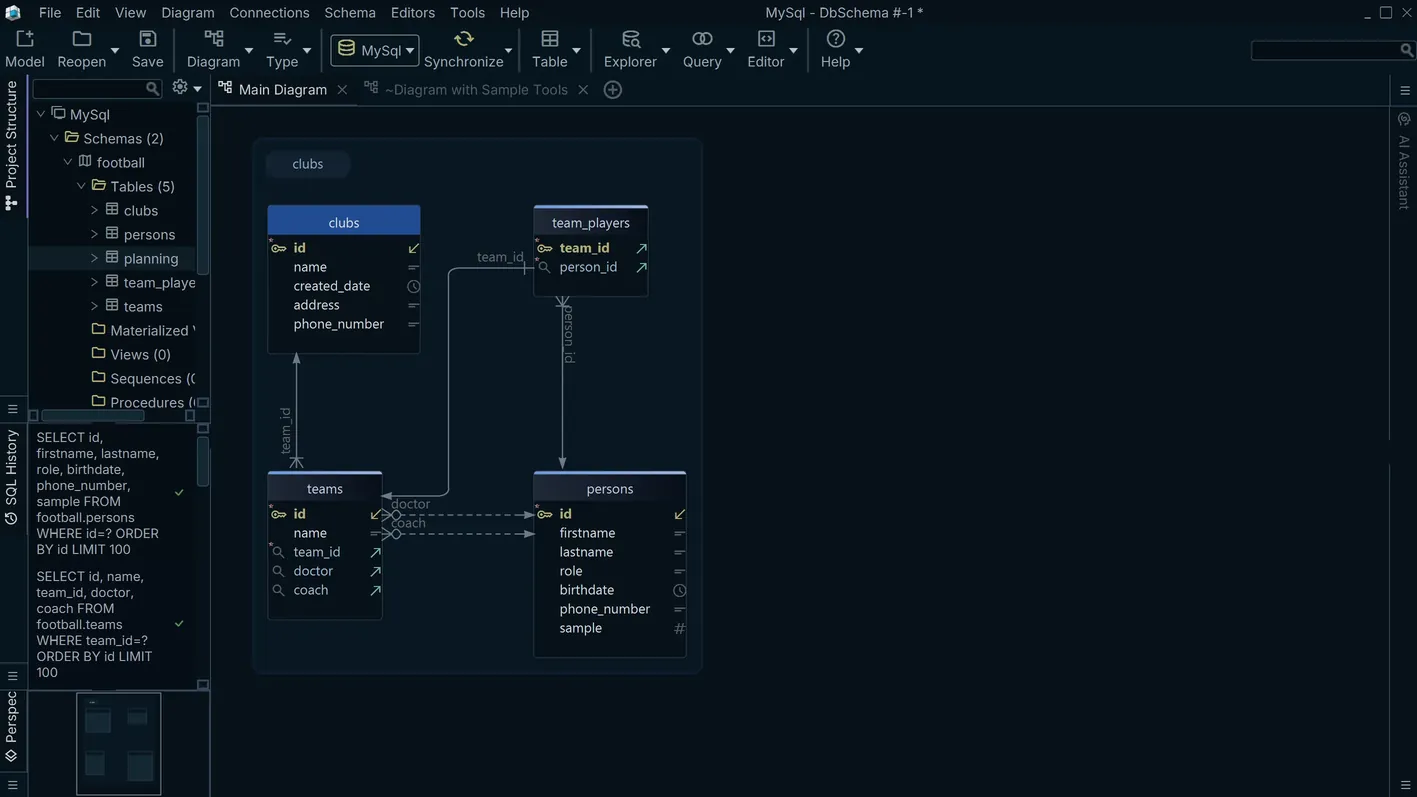
Browse Hive Table Data Interactively
DbSchema's data explorer connects to HiveServer2 and lets you browse table contents, apply column filters, and paginate through results from any Hive table. This gives analysts a quick way to inspect data without writing full HiveQL SELECT statements for every table inspection task.

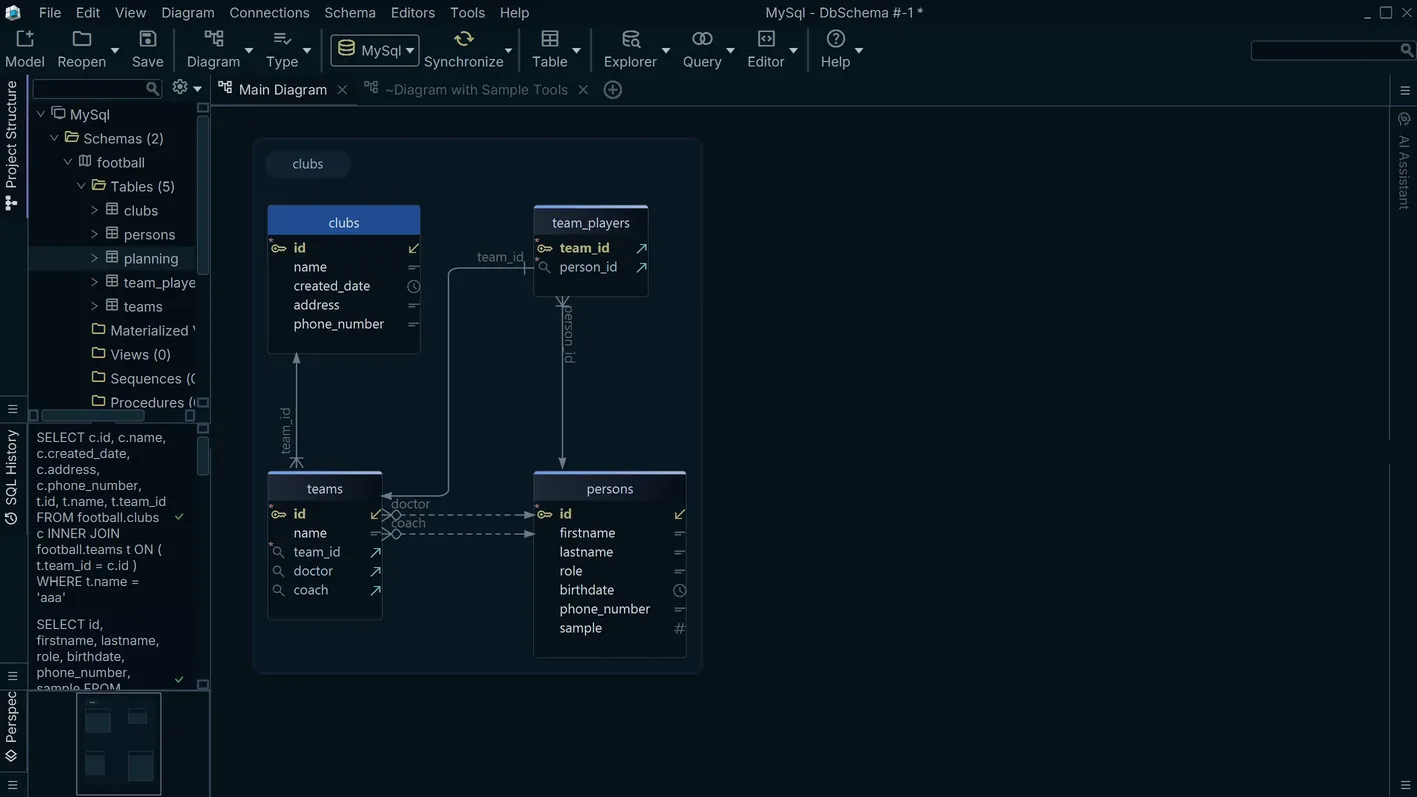
HiveQL Editor for Data Warehouse Queries
The DbSchema SQL editor supports HiveQL syntax, including partitioned table queries, ORC/Parquet format hints, and Hive-specific functions. Run HiveQL queries against your cluster and inspect result sets from a desktop client — no need to maintain a Hue or Zeppelin notebook for every ad-hoc query.
Connect DbSchema to HiveServer2
- Download and install DbSchema for your platform.
- Get the Hive JDBC driver bundle (
hive-jdbc-*.jarplus its dependencies) from the Hive distribution or Maven Central and add it via DbSchema's driver manager — for CDH or HDP deployments, use the vendor-provided driver from Cloudera or Hortonworks instead for best compatibility. - Enter the HiveServer2 host and port; it listens on 10000 by default. A standard
connection uses
jdbc:hive2://host:10000/default. - For a Kerberized cluster, add the principal to the URL instead:
jdbc:hive2://host:10000/default;principal=hive/host@REALM. - Connect — DbSchema reads the metastore through HiveServer2 and builds the schema diagram covering databases, tables, and partitions.
Why DbSchema for Apache Hive
- Explore the Hive metastore schema visually without beeline or Hue
- Run HiveQL queries from a desktop client with result set browsing
- Document Hive data warehouse schemas for BI and analytics teams
- Page through Hive table contents and narrow results down with column filters
- Connect to both Kerberized and standard HiveServer2 instances
Tired of piecing the metastore together through beeline output? Download DbSchema for free and get a browsable diagram of your Hive warehouse the same day.
Related databases
Teams working with Apache Hive often use these engines too. Explore dedicated guides and JDBC setup for each.