One Diagram for Every Trino Catalog
DbSchema gives Trino teams a design-first workflow: import the existing schema as an interactive ER diagram, refine it visually, and ship every change as a reviewed SQL script.
Built for visual modeling, schema documentation, and deployment, with an offline model you can keep in Git, team collaboration, and documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Trino Features Download Trino JDBC Driver · All drivers
What happens after you download?
Get to your first Trino schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Trino or open a sample
Reverse engineer an existing Trino database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Trino's Connector-Based Architecture and Multi-Catalog Schema Visualization
Trino (formerly PrestoSQL) is a distributed MPP SQL query engine that does not store any data itself. Instead, it federates queries across external data sources through a connector system. Each connector is registered as a catalog, which exposes one or more schemas, each containing tables. Common connectors include Hive (for files on HDFS or S3), Apache Iceberg, Delta Lake, MySQL, PostgreSQL, Kafka, and MongoDB, meaning a single Trino cluster can query data from all of these sources simultaneously.
Download DbSchema Free See Trino Features
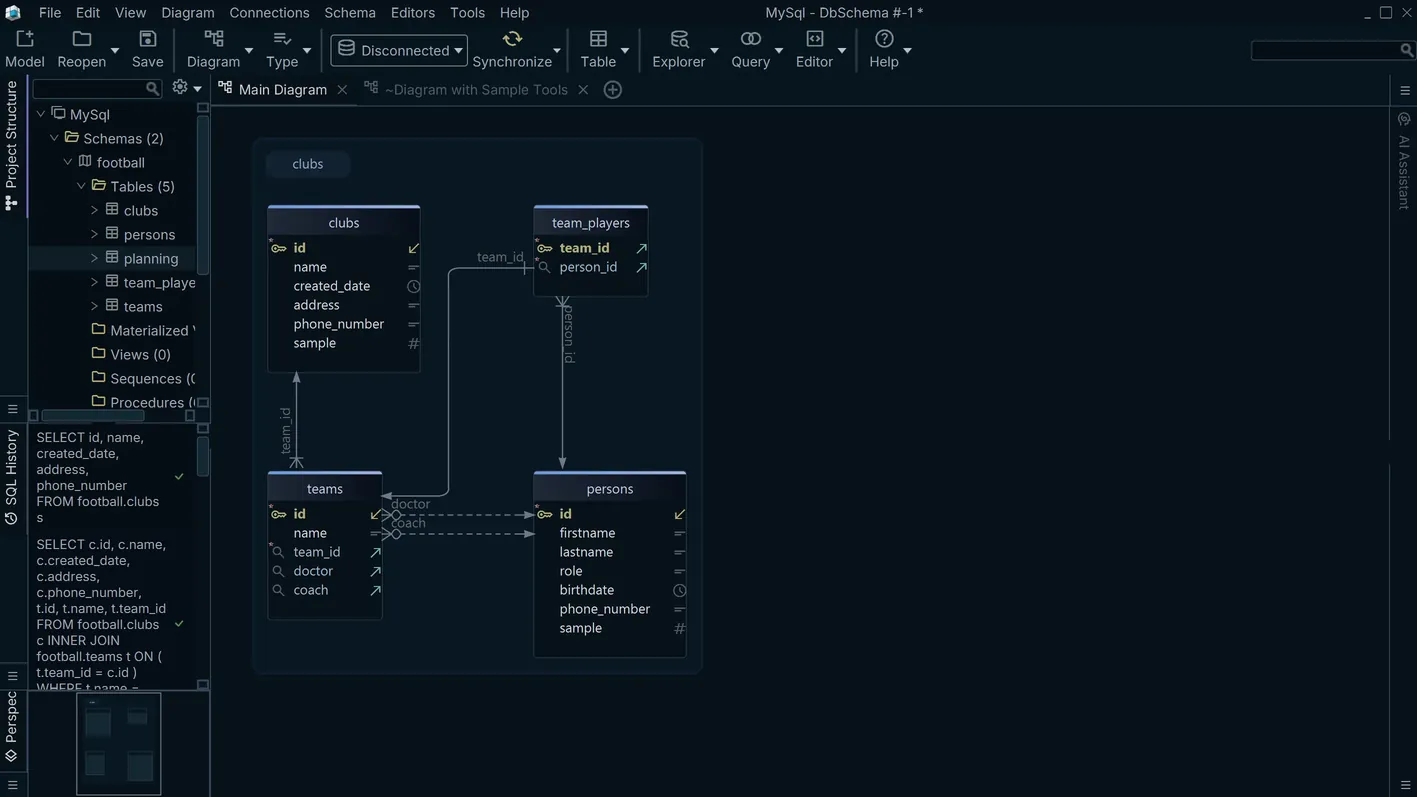
DbSchema connects to Trino via the official Trino JDBC driver and discovers all configured catalogs and their
schemas. Each catalog appears as a separate top-level node in the schema tree, and DbSchema renders the tables
and views within each catalog schema as entities in the visual diagram. This gives data engineering teams a
unified visual map of every data source that Trino federates — an overview that is otherwise only available by
querying information_schema across multiple catalogs manually.
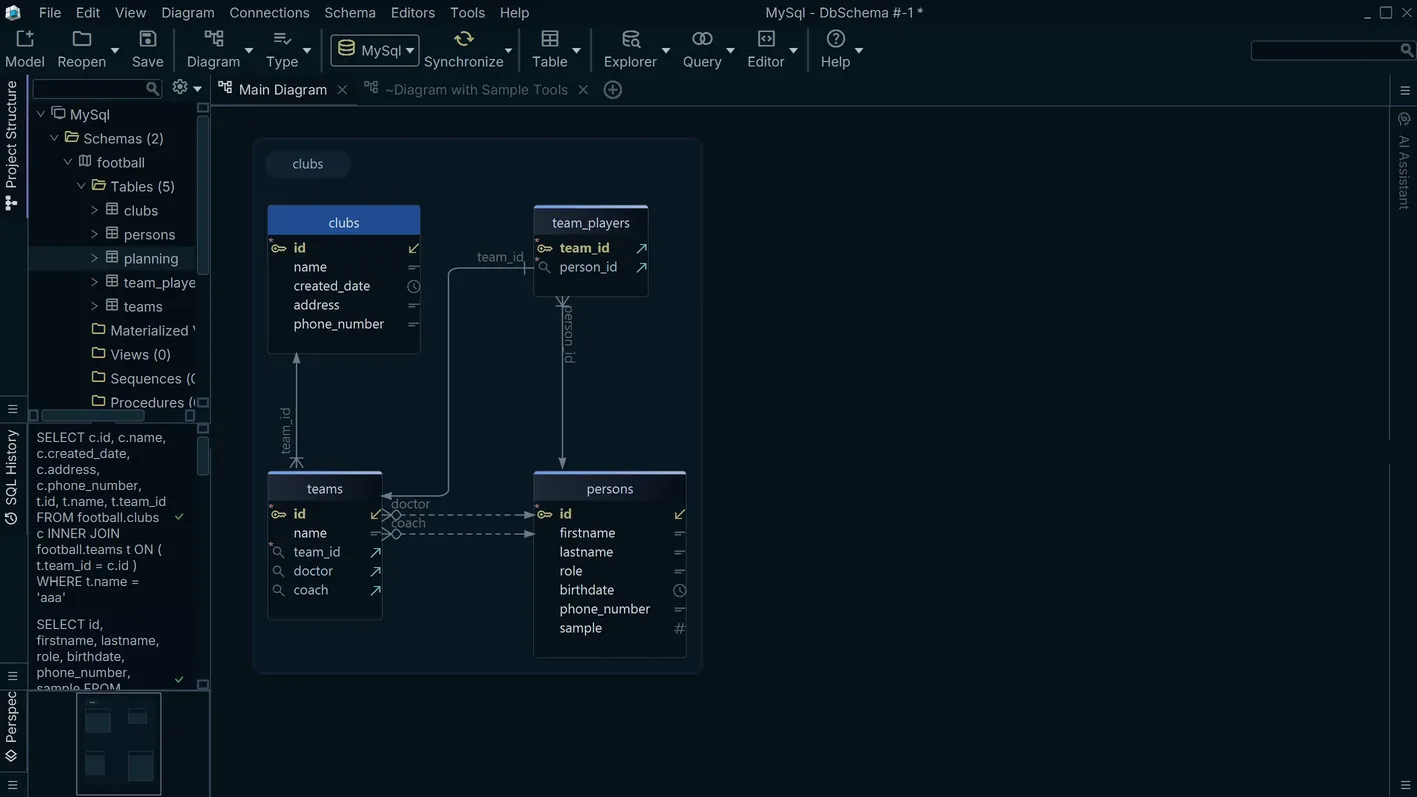
Writing Federated SQL Queries That Span Multiple Catalogs
One of Trino's defining capabilities is the ability to join tables from different data sources in a single SQL
statement. A query can join a Hive table on S3 with a PostgreSQL dimension table and a Kafka topic, all in one
SELECT. DbSchema's SQL editor submits these queries via the Trino JDBC driver and returns results
in the built-in results grid, making it a practical authoring environment for complex cross-source analytics that
would otherwise require multiple separate tool connections.
Three-part catalog.schema.table naming is required in Trino SQL when referencing tables outside the
currently selected catalog. DbSchema's schema tree lets you browse the catalog hierarchy and drag table names into
the editor to avoid typos in fully-qualified names. The SQL editor also supports EXPLAIN output to
review Trino's distributed query plan and identify expensive broadcast joins or full table scans.
Exploring Data from Hive, Iceberg, and Other Trino-Connected Sources
The DbSchema data explorer works with any table visible through Trino, regardless of the underlying storage system. You can browse rows from an Iceberg table stored in S3, a Delta Lake table in ADLS, or a MySQL table through the MySQL connector, all using the same explorer interface. This unified access is particularly useful for data engineers who need to spot-check data quality across multiple source systems during pipeline development or incident investigation.
Because Trino pushes down predicates to connectors wherever possible, the data explorer's column filters will be executed efficiently even against large-scale data sources. Trino's access control layer (file-based or Open Policy Agent) governs what the JDBC user can see, so the explorer respects the same permissions that apply to any other Trino client.

DbSchema and Trino: Connecting in Four Steps
A Trino cluster connection is set up the same way regardless of which catalogs it federates:
- Download and install DbSchema.
- Select Trino from the database list and provide the Trino JDBC driver (
trino-jdbc-*.jar), available from the Trino release page — driver classio.trino.jdbc.TrinoDriver. - Enter the coordinator host and its default port
8080, giving a JDBC URL such asjdbc:trino://coordinator:8080/hive/default. The path segment specifies the default catalog (hive) and schema (default) for the session; you can omit the schema and use fully-qualified three-part names in your queries instead. - Authenticate with password (via LDAP or a file-based realm), Kerberos, OAuth2/JWT, or certificate-based auth depending on your cluster configuration.
- Connect. DbSchema discovers every configured catalog and its schemas as a node in the schema tree.
For clusters with HTTPS and password auth, the URL should use jdbc:trino://coordinator:443/
and you must enable TLS in the connection properties. Pass additional Trino session properties such as
query_max_execution_time via JDBC connection properties in the DbSchema advanced settings dialog.
What Trino Users Gain from DbSchema
- Provides a visual map of all Trino catalogs and their schemas in one diagram, replacing manual
SHOW SCHEMASqueries. - Enables federated SQL authoring with a GUI editor, lowering the barrier for analysts less comfortable with the Trino CLI.
- Lets data engineers explore tables from Hive, Iceberg, Delta Lake, and RDBMS sources through a single interface.
- Makes cross-catalog join queries easier to build by allowing table names to be browsed and inserted from the schema tree.
- Generates offline documentation of multi-source data architectures that would otherwise require stitching together documentation from each connector's source system.
- Supports access-controlled exploration — the JDBC user's Trino permissions determine what data and schemas are visible in DbSchema.
Stop stitching together information_schema queries across catalogs by hand.
Download DbSchema for free and map every Trino-federated
source your cluster touches onto one diagram.
Related databases
Teams working with Trino often use these engines too. Explore dedicated guides and JDBC setup for each.