Turn Your Amazon Athena Catalog Into an ER Diagram
Build a clearer workflow for Amazon Athena: reverse engineer existing schemas into interactive ER diagrams, model changes visually, and generate reviewed SQL scripts before deployment.
DbSchema is built for visual modeling, schema documentation, and deployment. Keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Amazon Athena Features Download Amazon Athena JDBC Driver · All drivers
What happens after you download?
Get to your first Amazon Athena schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Amazon Athena or open a sample
Reverse engineer an existing Amazon Athena database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Visualizing the AWS Glue Data Catalog with DbSchema
Amazon Athena is a serverless query engine that reads data directly from S3, using the AWS Glue Data Catalog as its metadata store. Unlike traditional databases, there is no persistent cluster — Athena's schema is the set of Glue databases and tables that point to S3 paths and file formats such as Parquet, ORC, and CSV. DbSchema connects via the Simba Athena JDBC driver and renders these Glue-cataloged tables as an interactive ER diagram, providing a visual representation of the data lake schema that is otherwise only accessible through the Athena console or the Glue API.
Download DbSchema Free See Amazon Athena Features
Build and Run SQL Queries on S3-Backed Data
DbSchema's visual query builder generates Presto-compatible SQL for Athena, letting analysts join Glue catalog tables and set filter conditions without writing SQL. Queries execute asynchronously via the Athena API and results are retrieved from the configured S3 output location and displayed in the data grid.
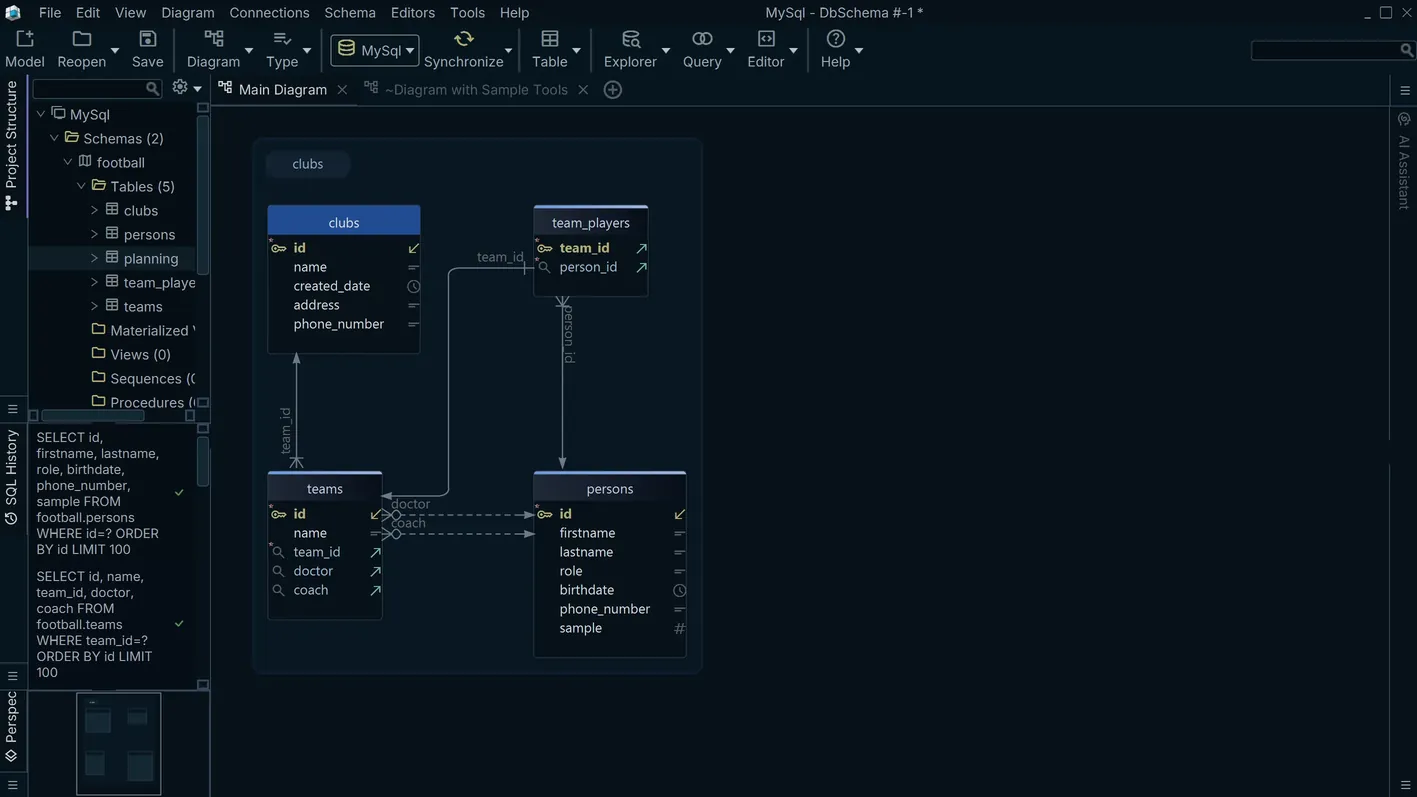
Browse Data Lake Table Contents
The data explorer fetches rows from Athena tables by issuing SELECT queries through the JDBC driver. Use it to inspect file-backed table contents, verify partition data, or sample rows from Parquet and ORC datasets stored in S3 — without returning to the Athena console for each lookup.

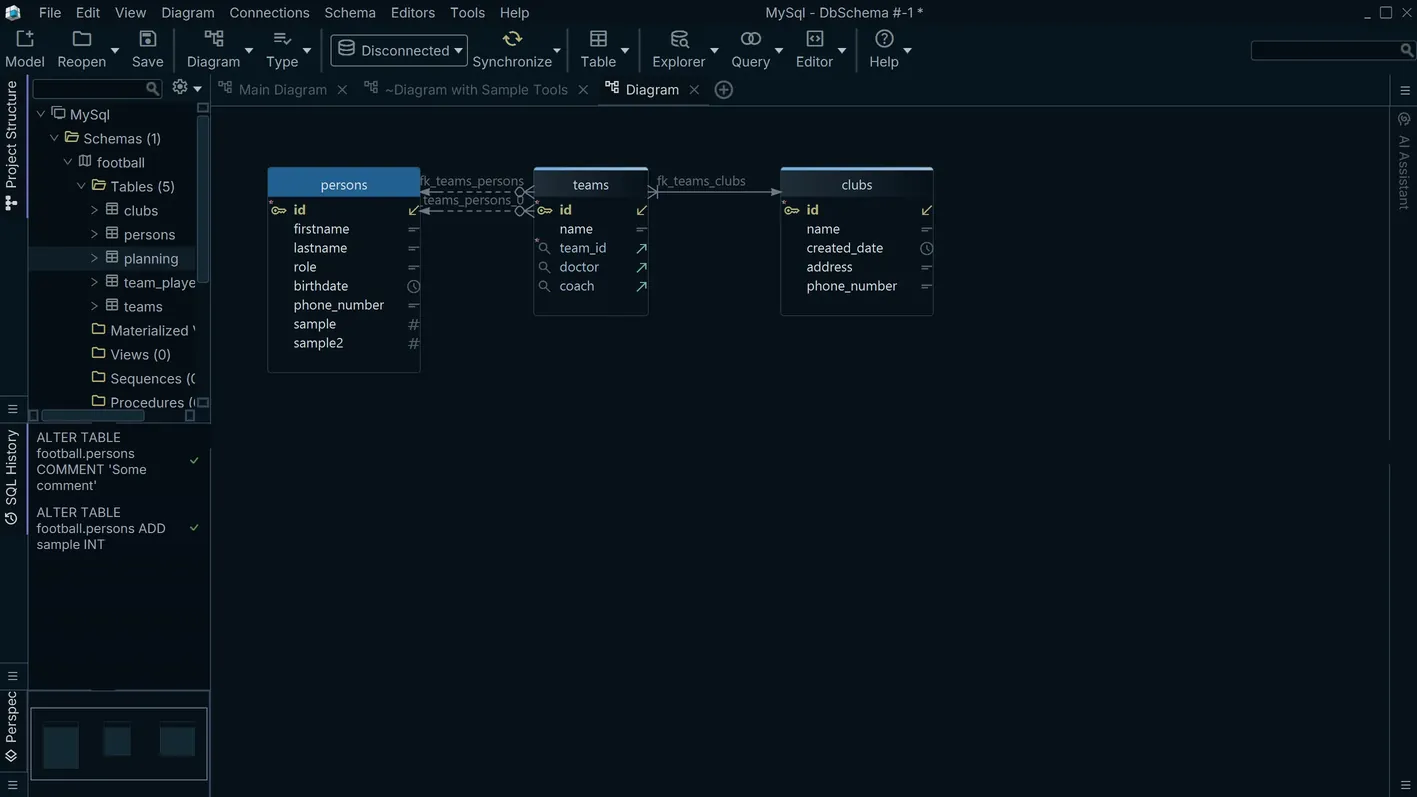
Document the Data Lake Schema
DbSchema generates HTML schema documentation from Athena's Glue catalog metadata, embedding ER diagrams and table definitions for every database in the catalog. This makes the data lake schema shareable and accessible to data consumers and stakeholders who do not have Athena console access.
How to Connect DbSchema to Amazon Athena
- Grab the DbSchema installer for your OS — the free download asks for no account.
- Grab the Simba Athena JDBC driver from the AWS documentation page and add it through DbSchema's driver manager screen.
- Create a new connection using the JDBC URL
jdbc:awsathena://AwsRegion=us-east-1;S3OutputLocation=s3://bucket/prefix/, adjusting the region and output bucket to your account. - Authenticate with an IAM user's Access Key ID and Secret Key entered in the connection dialog, or rely on the AWS default credentials chain configured on the host machine for a credential-free setup.
- Connect — DbSchema queries the Glue Data Catalog and lays out the discovered tables as an ER diagram.
The IAM principal used for the connection must have athena:StartQueryExecution and
s3:PutObject permissions on the S3 output bucket; without write access to that output
location, every query fails at execution time regardless of how the connection itself is configured.
What DbSchema Adds to an Amazon Athena Workflow
- Visualize Glue Data Catalog databases and tables as a navigable ER diagram
- Run Presto-SQL queries on S3-backed data through a visual query builder
- Inspect partitioned table data without opening the Athena console
- Generate schema documentation for the data lake catalog
- Share the Glue catalog schema with stakeholders who lack AWS console access
Tired of jumping into the Athena console just to check what a Glue table looks like? Download DbSchema for free and get every cataloged S3 table laid out as an ER diagram you can browse offline.
Related databases
Teams working with Amazon Athena often use these engines too. Explore dedicated guides and JDBC setup for each.