Map Federated Starburst and Trino Catalogs Visually
Build a clearer workflow for Starburst / Trino: reverse engineer existing schemas into interactive ER diagrams, model changes visually, and generate reviewed SQL scripts before deployment.
DbSchema is built for visual modeling, schema documentation, and deployment. Keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Starburst / Trino Features Download Starburst / Trino JDBC Driver · All drivers
What happens after you download?
Get to your first Starburst / Trino schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Starburst / Trino or open a sample
Reverse engineer an existing Starburst / Trino database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Visualizing Federated Data Across Trino Catalogs
Starburst and Trino federate queries across disparate data sources — Hive metastore, Apache Iceberg tables, JDBC-connected relational databases, and object-store formats — through a unified catalog abstraction. Each catalog exposes its underlying source's schemas and tables through Trino's SQL engine. DbSchema connects to Trino via JDBC and renders catalog-level schemas as ER diagrams, making cross-catalog relationships visible on a single canvas. Data engineers can understand how tables from Hive, Iceberg, and JDBC catalogs relate to each other without manually tracing fully qualified table references in SQL queries.
The free Community edition covers reverse engineering and ER diagram browsing for every connected catalog. Pro adds the visual query builder and interactive HTML documentation export described below, plus the offline design model with Git-based versioning — all available as a 15-day trial bundled with the same installer.
Download DbSchema Free See Starburst / Trino Features
Build Federated Queries Without Writing SQL
DbSchema's visual query builder supports Trino SQL syntax and lets you join tables from different catalogs without writing fully qualified three-part identifiers. Construct cross-source queries interactively and run them against the Trino coordinator from a desktop client.
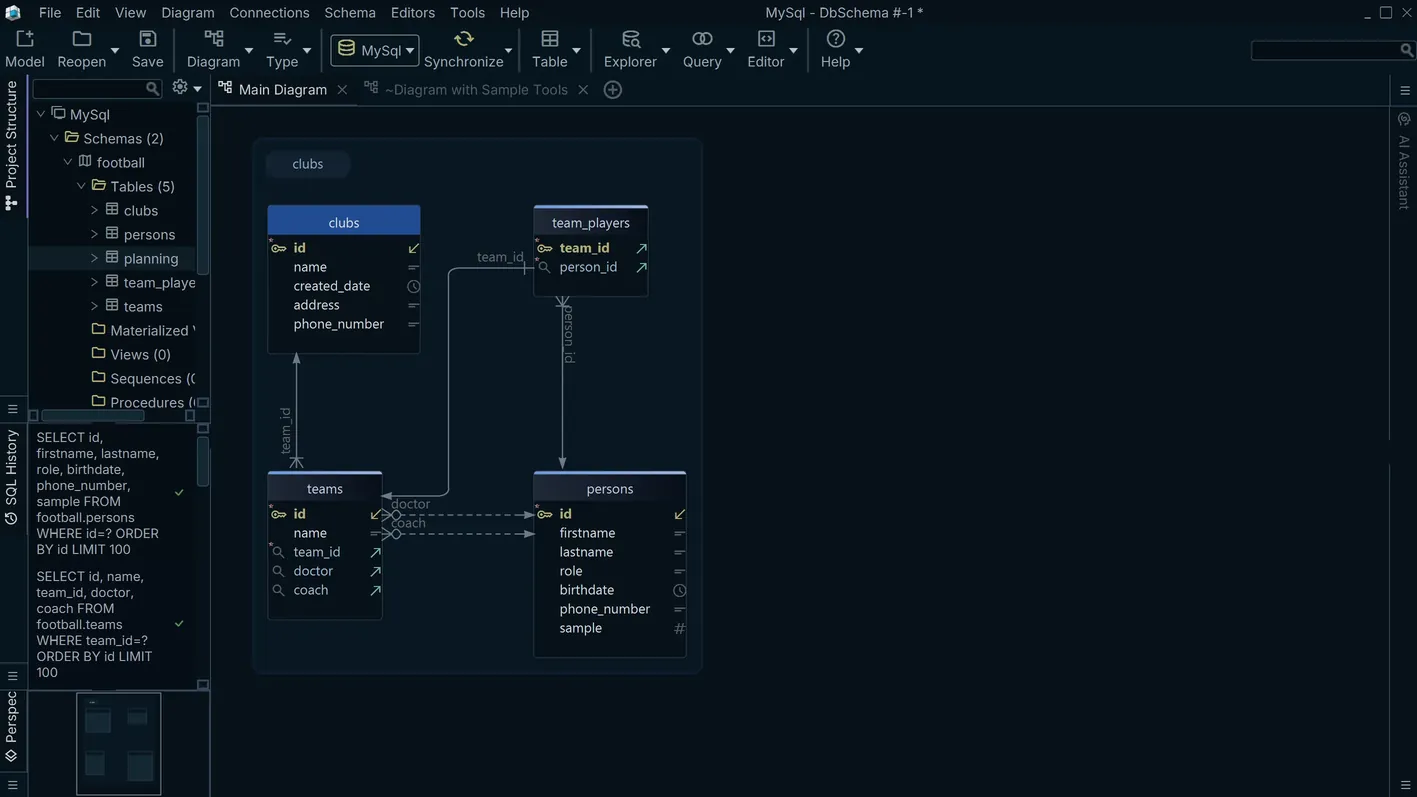
Explore Table Data Across Catalogs
The data explorer in DbSchema browses Trino table contents with column filtering and pagination. Engineers can validate catalog contents, inspect Iceberg snapshot data, or sample rows from object-store-backed tables without switching to the Trino CLI or a separate notebook environment.

Document the Federated Data Model
DbSchema auto-generates HTML schema documentation from your Trino catalog metadata, producing a shareable reference for the federated data model. Teams use this for data catalog documentation, new hire onboarding, and governance requirements across multi-source analytical environments.
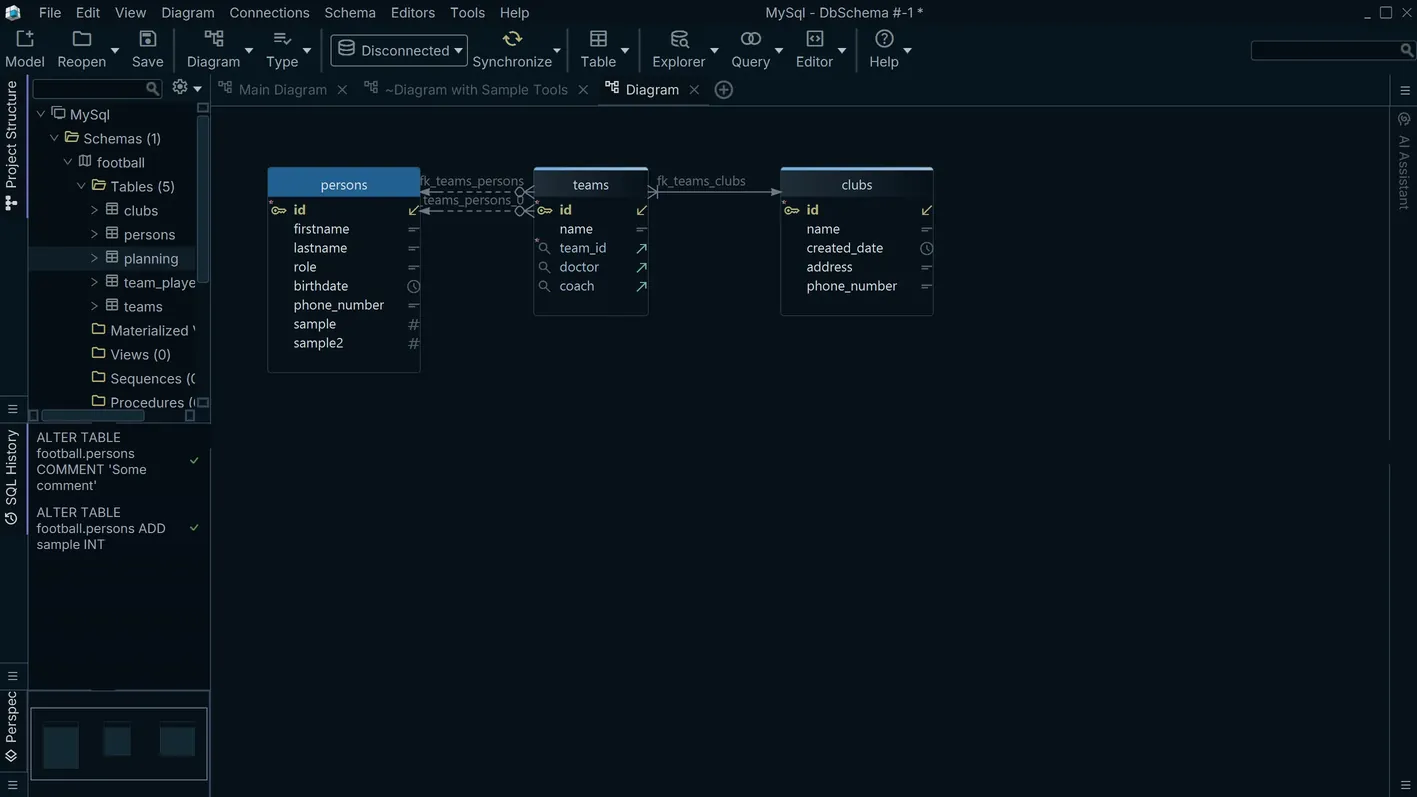
Explore and Document Starburst and Trino Catalogs from DbSchema
Getting from a Trino coordinator to a browsable catalog diagram takes a few steps:
- Install DbSchema — no signup required.
- Download the Trino JDBC driver as
trino-jdbc-*.jarfrom trino.io and register it in DbSchema's driver manager. - Enter the coordinator host and port; for open-source Trino the URL takes the form
jdbc:trino://host:8080/catalog/schema, while Starburst Enterprise usesjdbc:trino://host:8080with catalog and schema specified separately in DbSchema's connection UI. - If the deployment requires it, pass Kerberos or LDAP authentication properties in the advanced connection panel.
- Connect, and DbSchema renders the catalog-level schemas as an ER diagram.
The Payoff for Starburst and Trino Data Engineers
- Visualize multi-catalog schemas from Hive, Iceberg, and JDBC sources in a single diagram
- Build cross-catalog queries visually without writing fully qualified three-part table names
- Document the federated data model for governance and team onboarding
- Explore table contents across catalogs without switching to the Trino CLI
- Share schema documentation with consumers of the federated layer
Turn your Hive, Iceberg, and JDBC catalogs into one navigable diagram — download DbSchema for free and point it at your Starburst or Trino coordinator today.
Related databases
Teams working with Starburst / Trino often use these engines too. Explore dedicated guides and JDBC setup for each.