Model Google Cloud Spanner Schemas in DbSchema
Build a clearer workflow for Google Cloud Spanner: reverse engineer existing schemas into interactive ER diagrams, model changes visually, and generate reviewed SQL scripts before deployment.
DbSchema is built for visual modeling, schema documentation, and deployment. Keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Google Cloud Spanner Features Download Google Cloud Spanner JDBC Driver · All drivers
What happens after you download?
Get to your first Google Cloud Spanner schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Google Cloud Spanner or open a sample
Reverse engineer an existing Google Cloud Spanner database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Google Cloud Spanner is a globally distributed, horizontally scalable relational database with external consistency and up to 99.999% availability. Its schema model includes interleaved tables — a parent-child structure that co-locates related rows for locality — alongside secondary indexes and foreign keys. Understanding this hierarchy is essential when designing for Spanner's distributed storage, and DbSchema renders the entire structure visually so architects can reason about table relationships without reading raw DDL.
Visualizing Spanner's Interleaved Table Hierarchy
Spanner's interleaved tables create physical co-location between a parent table and its children. DbSchema reads the information schema and renders parent-child relationships as explicit diagram edges, making it straightforward to audit whether interleaving is applied correctly and to document the intended data model for distributed system architects.
Download DbSchema Free See Google Cloud Spanner Features
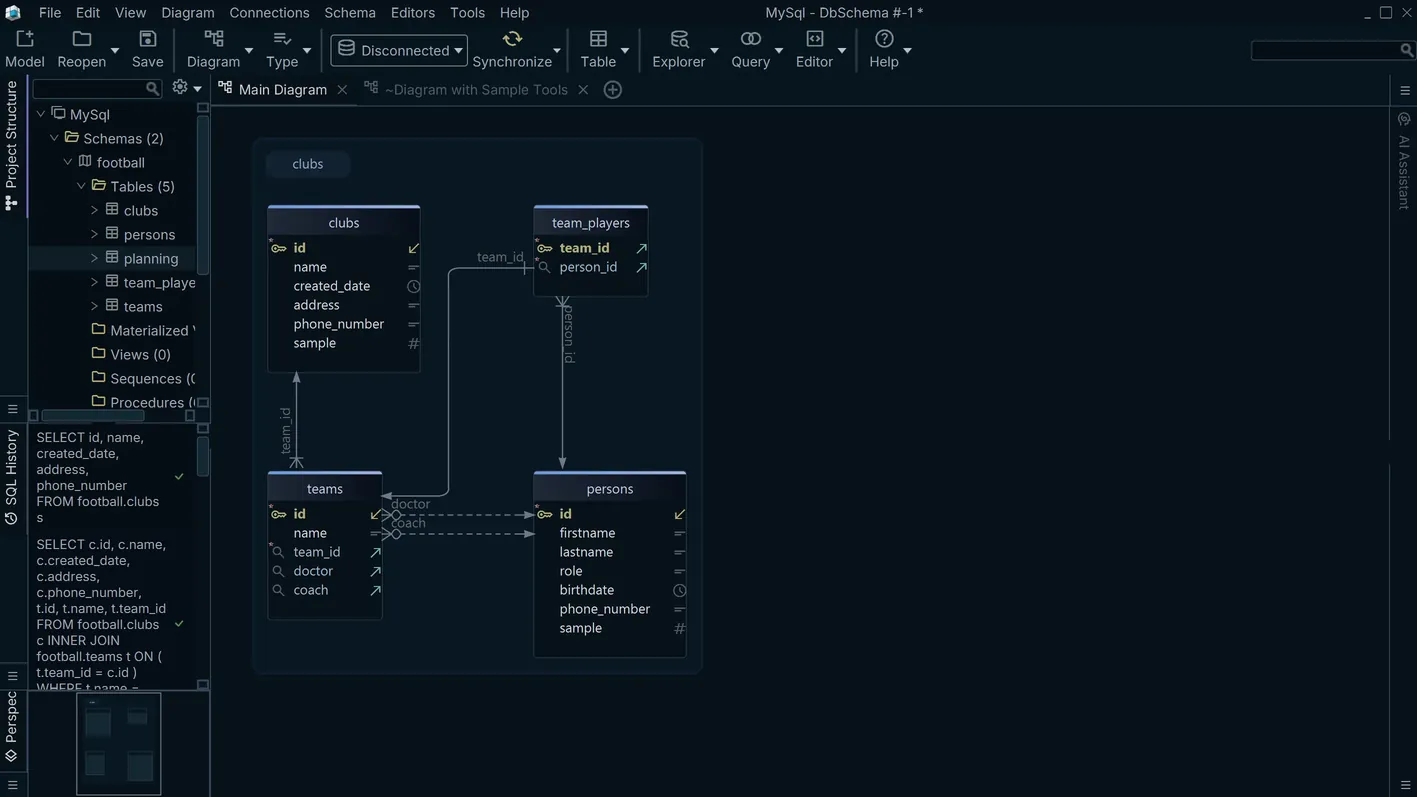
Query Builder for Spanner SQL
Cloud Spanner supports a SQL dialect closely aligned with ANSI SQL. DbSchema's query builder constructs SELECT statements visually — selecting columns, defining join conditions, and applying filters — then executes them directly against your Spanner instance. This is particularly useful for exploring large distributed datasets without writing raw SQL.
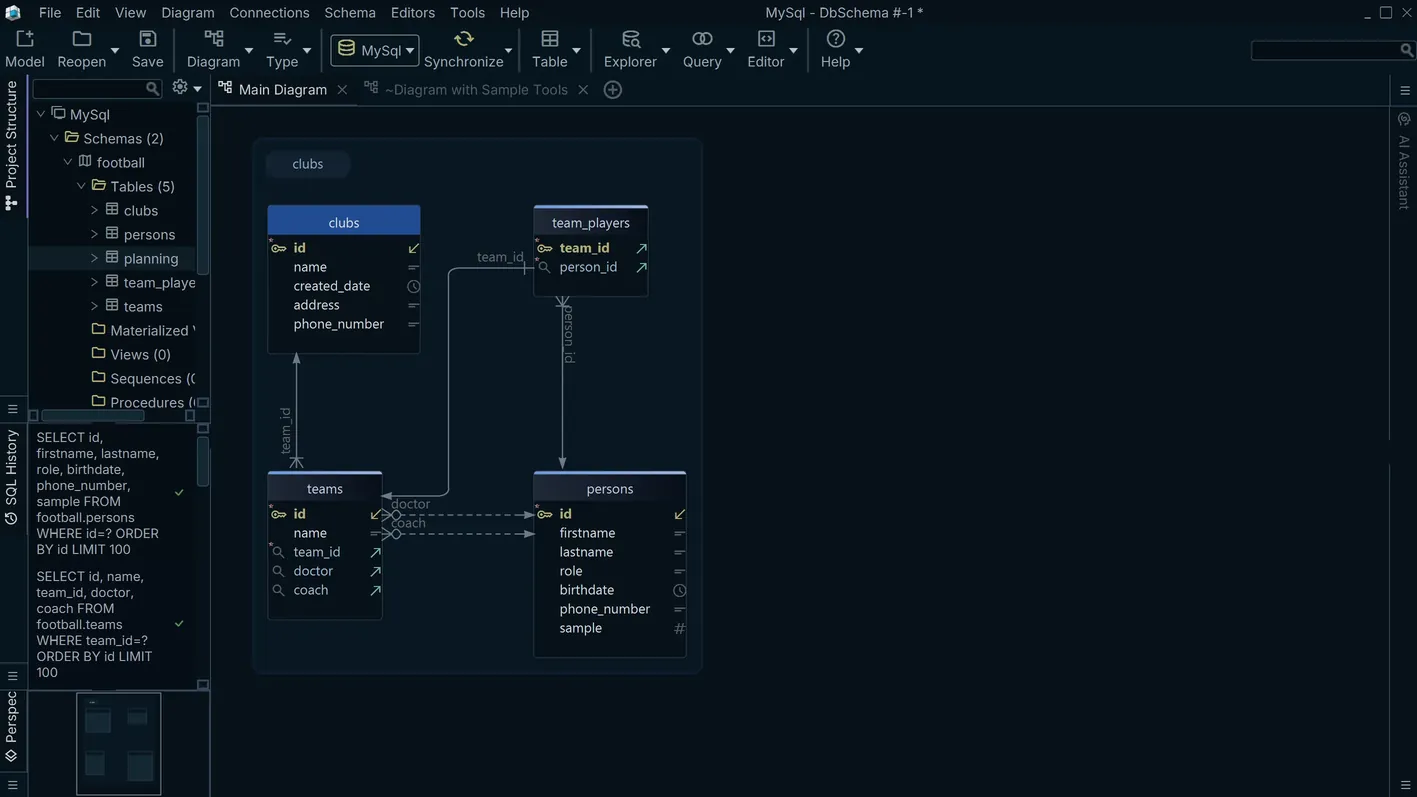
Spanner Schema Docs from the Live Information Schema
DbSchema generates HTML schema documentation from the live Spanner information schema, including ER diagrams, table descriptions, column types, and index definitions. For globally distributed databases shared across multiple engineering teams, this documentation becomes a reliable reference for understanding the data model without direct database access.
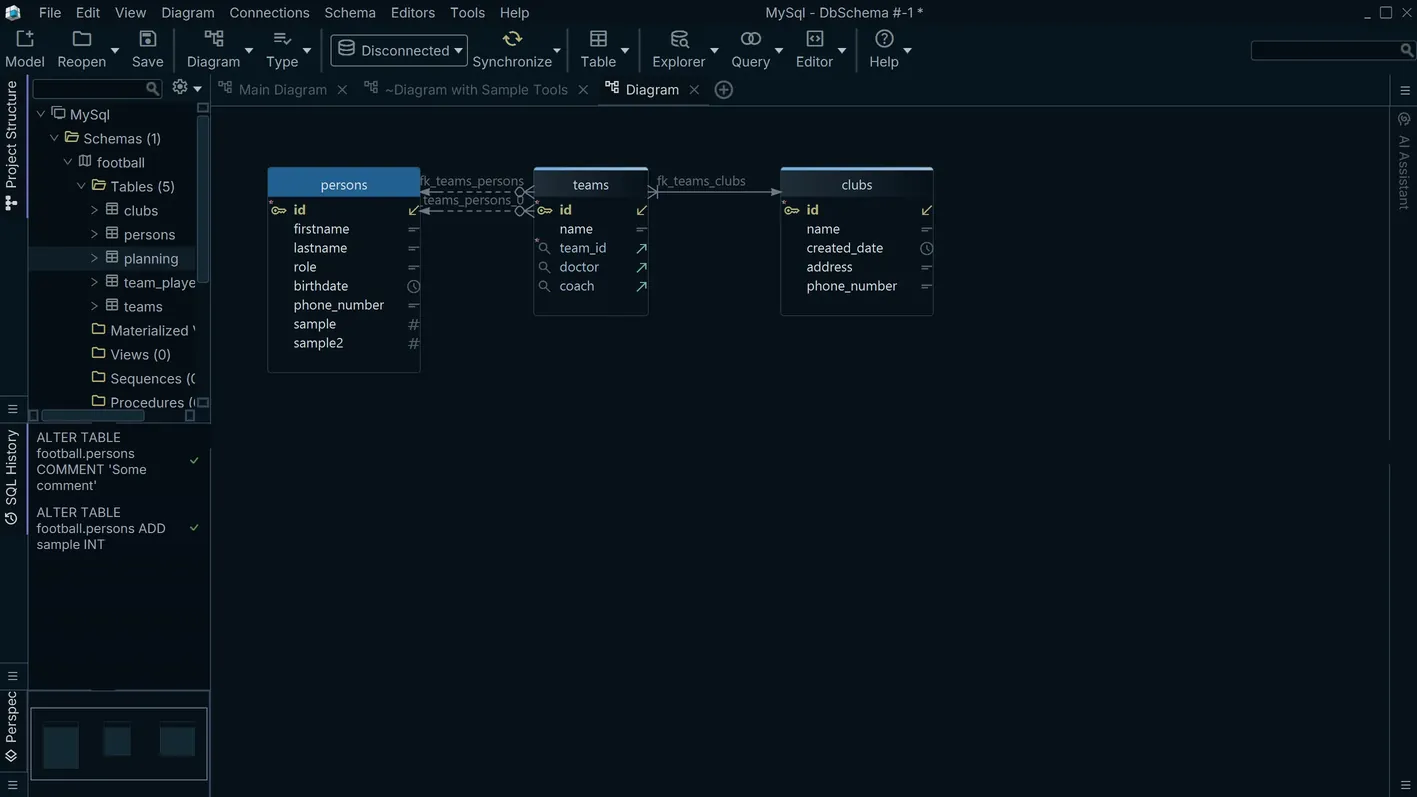
Set Up the Cloud Spanner Connection in DbSchema
Getting from a running Spanner instance to a browsable diagram takes a few steps:
- Install DbSchema on Windows, macOS, or Linux and launch it.
- Start a new connection and pick Google Cloud Spanner; DbSchema loads the Cloud Spanner JDBC driver
(
google-cloud-spanner-jdbc) through its driver manager. - Authenticate with Application Default Credentials — set
GOOGLE_APPLICATION_CREDENTIALSto a service account JSON key file, or rungcloud auth application-default loginto reuse your user credentials. - Supply the project, instance, and database names; DbSchema assembles the JDBC URL
jdbc:cloudspanner:/projects/project/instances/instance/databases/databasefor you. Spanner has no traditional port — traffic goes through the Cloud Spanner gRPC API on port 443. - Connect to reverse-engineer the schema, including interleaved table relationships, into the diagram.
Why Teams Use DbSchema with Cloud Spanner
- Interleaved table visualization — see parent-child co-location relationships as explicit diagram edges, not just raw DDL.
- Schema documentation — generate HTML docs with ER diagrams for distributed teams who need schema visibility without database access.
- Offline schema design — model new tables and interleaving strategies in DbSchema before applying them to a running Spanner instance.
- Visual query exploration — build and run Spanner SQL queries visually against your production or staging instance.
- Schema comparison — diff Spanner schemas between development and production instances and review proposed DDL changes.
Ready to map your Spanner instance? Download DbSchema for free and turn interleaved parent-child tables into an ER diagram you can hand to the whole team.
Related databases
Teams working with Google Cloud Spanner often use these engines too. Explore dedicated guides and JDBC setup for each.