DbSchema for Firebolt: Tables, Indexes, and SQL Together
DbSchema gives Firebolt teams a design-first workflow: import the existing schema as an interactive ER diagram, refine it visually, and ship every change as a reviewed SQL script.
Built for visual modeling, schema documentation, and deployment, with an offline model you can keep in Git, team collaboration, and documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Firebolt Features Download Firebolt JDBC Driver · All drivers
What happens after you download?
Get to your first Firebolt schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Firebolt or open a sample
Reverse engineer an existing Firebolt database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Engine and Database Architecture
Firebolt is a cloud OLAP database purpose-built for sub-second analytics on large datasets, running on AWS and GCP. A key architectural differentiator is the separation of compute engines from databases: each Firebolt database can be associated with one or more named engines that are independently started, stopped, and sized, allowing teams to run isolated workloads (for example, ingestion vs. interactive queries) on dedicated compute without contention. Firebolt stores data in a proprietary compressed columnar format and builds sparse indexes, aggregating indexes, and join indexes automatically or on demand to accelerate common query patterns. DbSchema connects via the Firebolt JDBC driver and introspects table schemas and index definitions, rendering them as schema diagrams that show column types and index configurations together.
Download DbSchema Free See Firebolt Features
Writing Firebolt Analytical SQL in the SQL Editor
Firebolt's SQL dialect extends ANSI SQL with functions for approximate aggregations, array operations, and semi-structured data manipulation. DbSchema's SQL editor connects over the Firebolt JDBC driver and provides table and column name auto-completion, syntax highlighting, and a results grid that handles the wide, flat result sets typical of OLAP queries. You can write window functions, lateral joins, and Firebolt-specific array unnesting expressions, then save the queries to a shared library for reuse across the team. The editor also shows query execution time, allowing you to measure the impact of adding or modifying aggregating indexes on query performance.
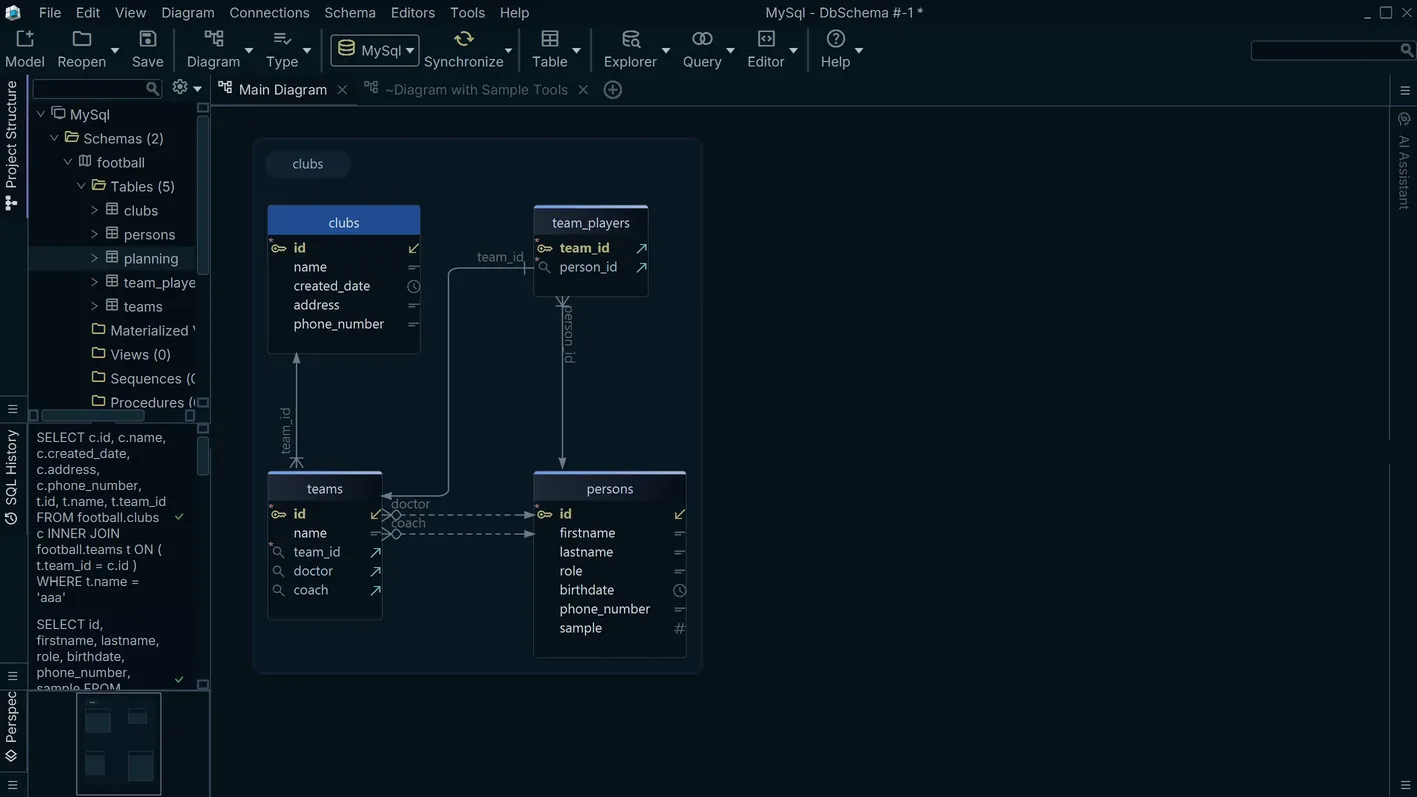
Exploring Large Analytical Datasets
The DbSchema data explorer lets you sample and browse Firebolt table contents without writing SQL, applying column filters and sort orders through a point-and-click interface. Because Firebolt's engines return results at sub-second latency even for large tables, the data explorer pages through results rapidly. This makes it practical to spot-check newly loaded data, verify that a dimension table join key is populated correctly, or inspect the output of a materialized aggregating index before referencing it in a production dashboard. You can export sampled rows to CSV directly from the explorer for use in external validation scripts.

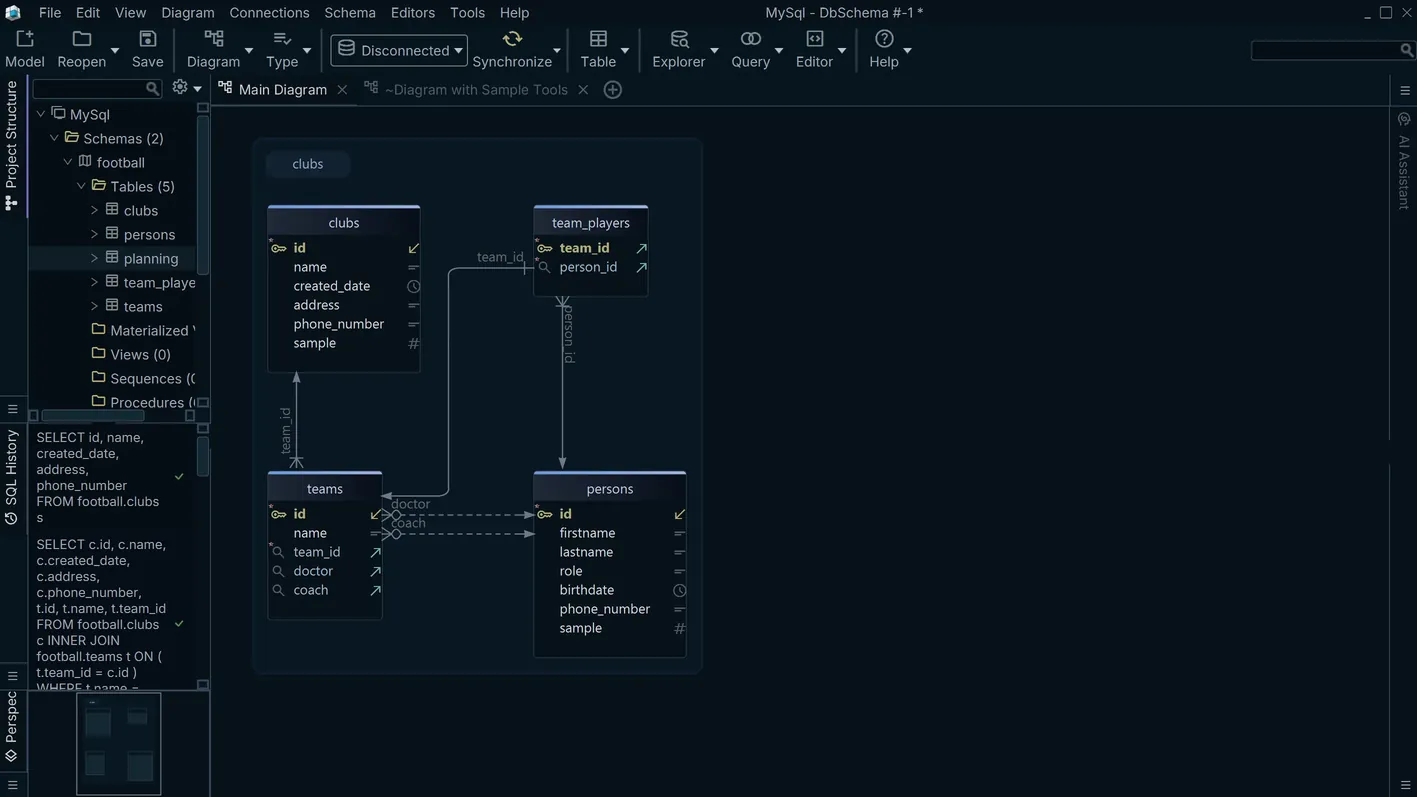
Connecting DbSchema to a Firebolt Engine
- Grab the DbSchema installer for Windows, macOS, or Linux — no account required.
- Fetch the Firebolt JDBC driver JAR (
com.firebolt.FireboltDriver) from the Firebolt documentation and add it via DbSchema's driver manager. - Start a connection with the JDBC URL
jdbc:firebolt://api.app.firebolt.io/mydb, wheremydbis your Firebolt database name, and supply your Firebolt service account credentials (client ID and client secret) or user email and password. Firebolt uses HTTPS on port 443 for all JDBC traffic. - If multiple engines are associated with the database, add
?engine=my_engineto the JDBC URL to direct queries to a particular compute engine. - Connect — DbSchema introspects table schemas and index definitions into a diagram. For GCP-hosted databases, the URL host changes to the GCP endpoint.
What Firebolt Teams Get From DbSchema
- Visualize Firebolt table schemas alongside their sparse, aggregating, and join index configurations in a single diagram to plan query optimization strategies.
- Write and benchmark analytical SQL in DbSchema's SQL editor, measuring the performance gain of each new index type without switching tools.
- Explore large dataset samples in the data explorer at sub-second speed to validate data loads and dimension table integrity before connecting BI tools.
- Generate schema documentation for Firebolt databases to maintain an up-to-date data catalog for analytics teams.
- Manage connections to multiple Firebolt engines (ingestion, interactive analytics) from a single DbSchema project.
- Use DbSchema's offline model to design new Firebolt table schemas with index annotations before creating them on the cluster.
Seeing aggregating and join indexes next to the tables they accelerate makes optimization a visual task, not a guessing game. Download DbSchema and connect it to your Firebolt engine today.
Related databases
Teams working with Firebolt often use these engines too. Explore dedicated guides and JDBC setup for each.