See What PostgREST Exposes From Your Supabase Schema
DbSchema gives Supabase teams a design-first workflow: import the existing schema as an interactive ER diagram, refine it visually, and ship every change as a reviewed SQL script.
Built for relational modeling, migration planning, and SQL-first collaboration, with an offline model you can keep in Git, team collaboration, and documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Supabase Features Download Supabase JDBC Driver · All drivers
What happens after you download?
Get to your first Supabase schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Supabase or open a sample
Reverse engineer an existing Supabase database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Supabase's PostgreSQL Foundation and RLS-Aware Schema Visualization
Supabase is an open-source Firebase alternative built entirely on top of PostgreSQL. It layers a rich set of services — PostgREST for automatic REST API generation, Realtime for WebSocket-based change subscriptions, Auth for user management, Storage for file uploads, and Edge Functions for server-side logic — all driven by the same underlying PostgreSQL database. Row Level Security (RLS) policies define which rows each authenticated user can read or modify, turning access control into a first-class database concern.
Download DbSchema Free See Supabase Features
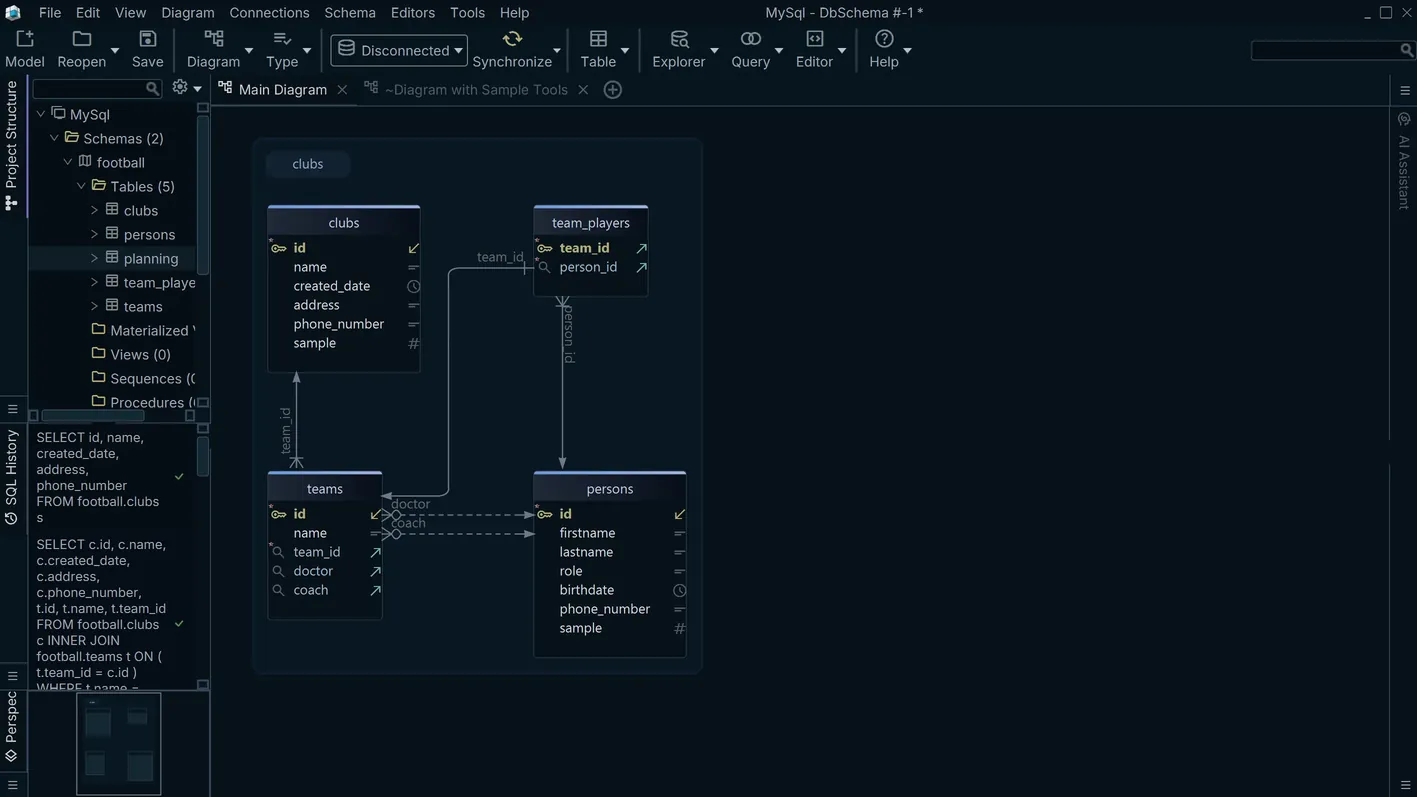
DbSchema connects to the Supabase PostgreSQL instance directly and reverse-engineers the full schema, including
tables in the public schema, PostgREST views, RLS policy definitions visible via
pg_policies, and all foreign key relationships. The visual diagram gives your team a single-pane
view of the data model that PostgREST exposes as a REST API, making it straightforward to reason about the
relationship between your tables and the API endpoints your frontend consumes.
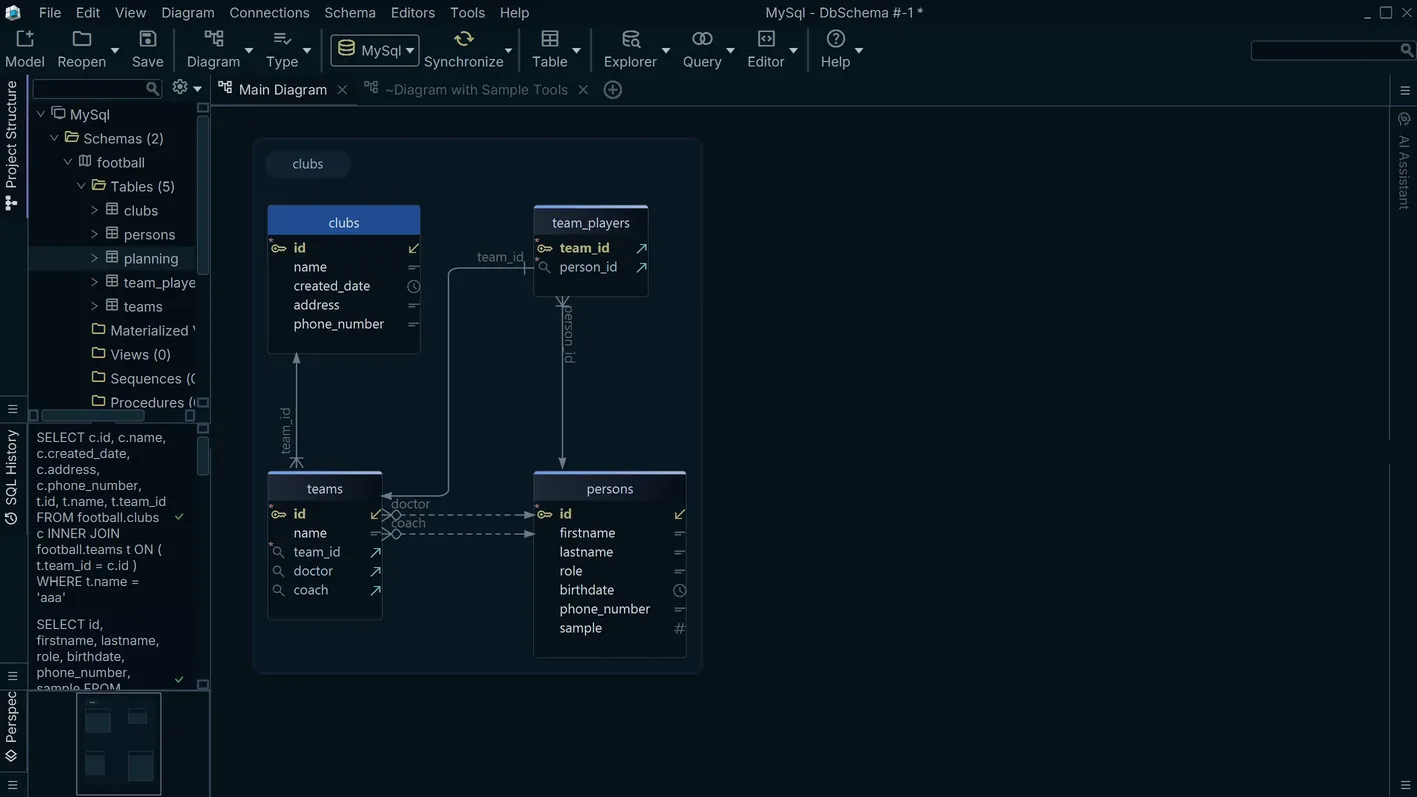
Writing PostgreSQL Queries Against Supabase
Supabase is standard PostgreSQL under the hood, so every PostgreSQL SQL feature is available — triggers, stored
procedures, DO blocks, CTEs, window functions, and more. DbSchema's SQL editor connects via the
standard PostgreSQL JDBC driver and gives you a full-featured query environment. You can run EXPLAIN
ANALYZE to profile slow queries, test RLS policies by temporarily setting
SET ROLE authenticated, or script bulk data migrations using DO $$...$$ anonymous
blocks.
The editor supports multiple simultaneous query tabs, which is useful when you need to cross-reference data from several related tables or compare query plans before and after adding an index. Results can be exported directly to CSV for reporting or handed off to your data team for further analysis.
Exploring Supabase Tables Including pgvector Embeddings
Supabase supports the pgvector extension for storing and querying machine learning embeddings,
making it a popular backend for AI-powered features. DbSchema's data explorer renders vector column
values so you can spot-check that embedding rows are populated correctly. You can filter the table by any other
column to retrieve a specific record and inspect its embedding alongside its metadata, which is useful for
debugging nearest-neighbour search mismatches.
The explorer also makes it easy to navigate the auth.users, storage.objects, and other
Supabase system schemas that sit alongside the public schema. This is helpful when investigating
permission issues or understanding the relationship between user IDs in auth.users and rows protected
by RLS policies in your application tables.

Set Up DbSchema for a Supabase Project
Since Supabase exposes a standard PostgreSQL endpoint, the connection setup is familiar to anyone who has connected to Postgres before:
- Install DbSchema and select PostgreSQL as the database type — Supabase does not need a dedicated driver.
- Open the Supabase dashboard under Settings → Database and copy the connection string.
- Paste the host, port 5432, and project reference into DbSchema, forming a URL like
jdbc:postgresql://db.xxxxx.supabase.co:5432/postgres?sslmode=require, wherexxxxxis unique to your project. - Keep the
sslmode=requireparameter in place — Supabase enforces SSL on this endpoint. - Connect, and DbSchema reverse-engineers the
publicschema, RLS policies, and foreign keys into a diagram.
For applications or tools that open many short-lived connections, Supabase also provides a connection pooler
(PgBouncer) endpoint whose hostname contains pooler.supabase.com. Use the pooler URL in DbSchema
if you are on a free-tier project with a limited connection count, or if you notice connection timeouts during
intensive query sessions. The database password is the one set in the Supabase dashboard; it is separate from
any API keys used by the PostgREST layer.
What Supabase Teams Gain by Adding DbSchema
- Renders the complete schema including RLS policies, giving backend and frontend teams a shared visual reference.
- Simplifies debugging of PostgREST API issues by showing the exact tables and views exposed to the REST layer.
- Provides a SQL query environment for tasks that are too complex for the Supabase Studio table editor.
- Makes pgvector embedding data inspectable without writing custom queries, speeding up AI feature development.
- Generates offline schema documentation that can be included in technical design documents and security audits.
- Supports both direct connection and pooler connection profiles, giving flexibility for different workload types.
See exactly what PostgREST exposes to your frontend — download DbSchema for free, then point it at your Supabase project's Postgres database today.
Frequently asked questions
Related databases
Teams working with Supabase often use these engines too. Explore dedicated guides and JDBC setup for each.