View SnappyData Row and Column Tables Together
Connect DbSchema to SnappyData and turn the live schema into an editable visual model: explore relationships in interactive ER diagrams, plan changes on the canvas, and generate reviewed SQL scripts for deployment.
The workflow is designed for visual modeling, schema documentation, and deployment — keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See SnappyData Features Download SnappyData JDBC Driver · All drivers
What happens after you download?
Get to your first SnappyData schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to SnappyData or open a sample
Reverse engineer an existing SnappyData database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Visual Schema Tools for Apache Spark-Integrated In-Memory Databases
SnappyData extends Apache Spark with an integrated column store, enabling mixed OLTP and OLAP workloads on the same cluster without moving data between systems. It supports row tables for transactional updates and column tables optimized for analytical scans. DbSchema connects to SnappyData via JDBC, displays both table types in the diagram canvas, and provides an SQL editor for running Spark SQL queries without requiring a notebook environment or a dedicated Spark application to be deployed.
The Community edition is free and covers the workflow above in full: reading the cluster schema, browsing it on the diagram, and querying it with Spark SQL. Teams that need a versioned record of how the schema changed between cluster upgrades can step up to Pro, which stores the design as an offline file with Git support.
Download DbSchema Free See SnappyData Features
Connect to SnappyData and Explore Table Schemas
After connecting, DbSchema reads the SnappyData catalog and displays row-store and column-store table definitions in the diagram canvas. The visual layout gives a clear view of the cluster's data architecture before writing queries or planning schema changes.
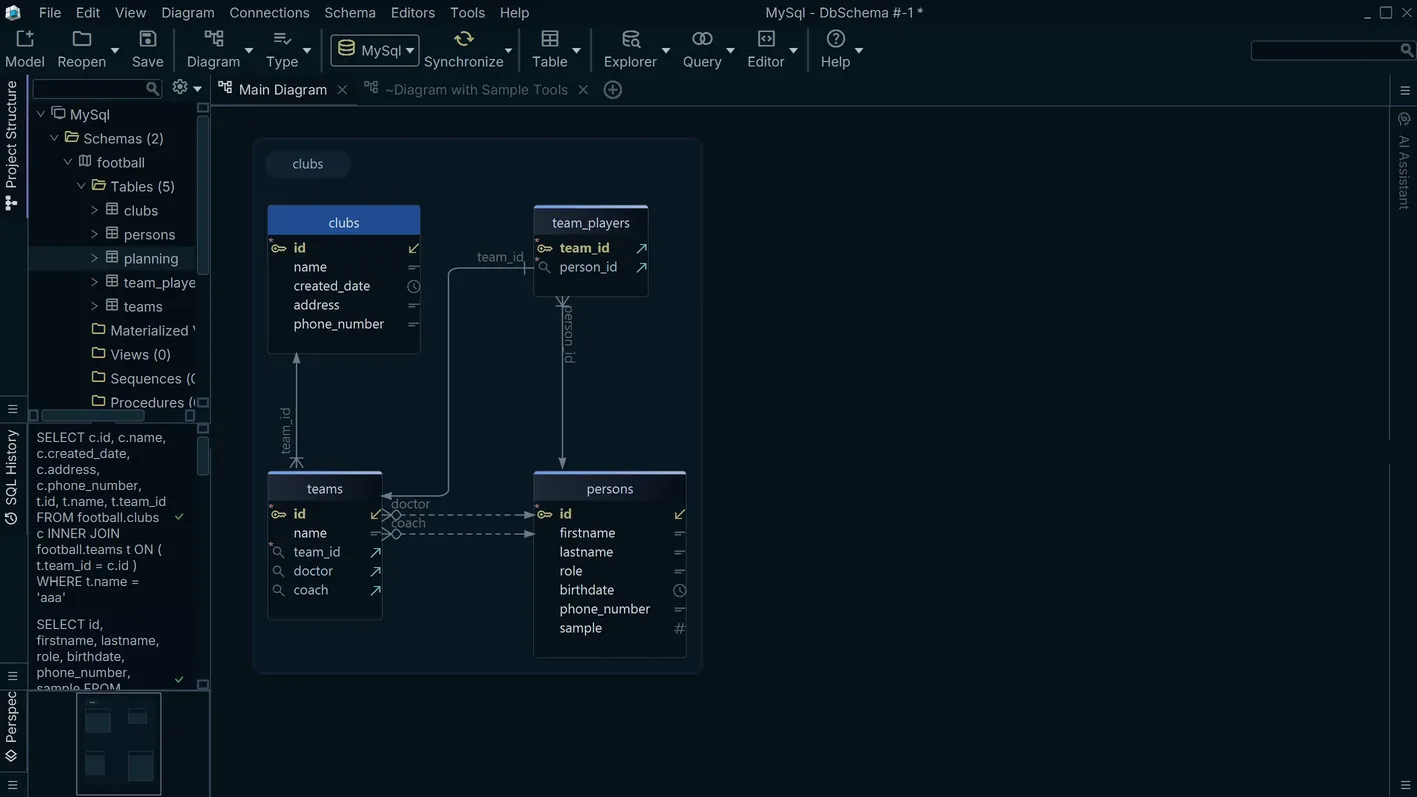
Spark SQL Without a Notebook
SnappyData's JDBC interface accepts Spark SQL — including window functions, aggregations, and joins across row and column tables. DbSchema's SQL editor executes these queries against the cluster and presents results inline, providing an interactive alternative to Spark notebooks for ad-hoc analysis and query development.
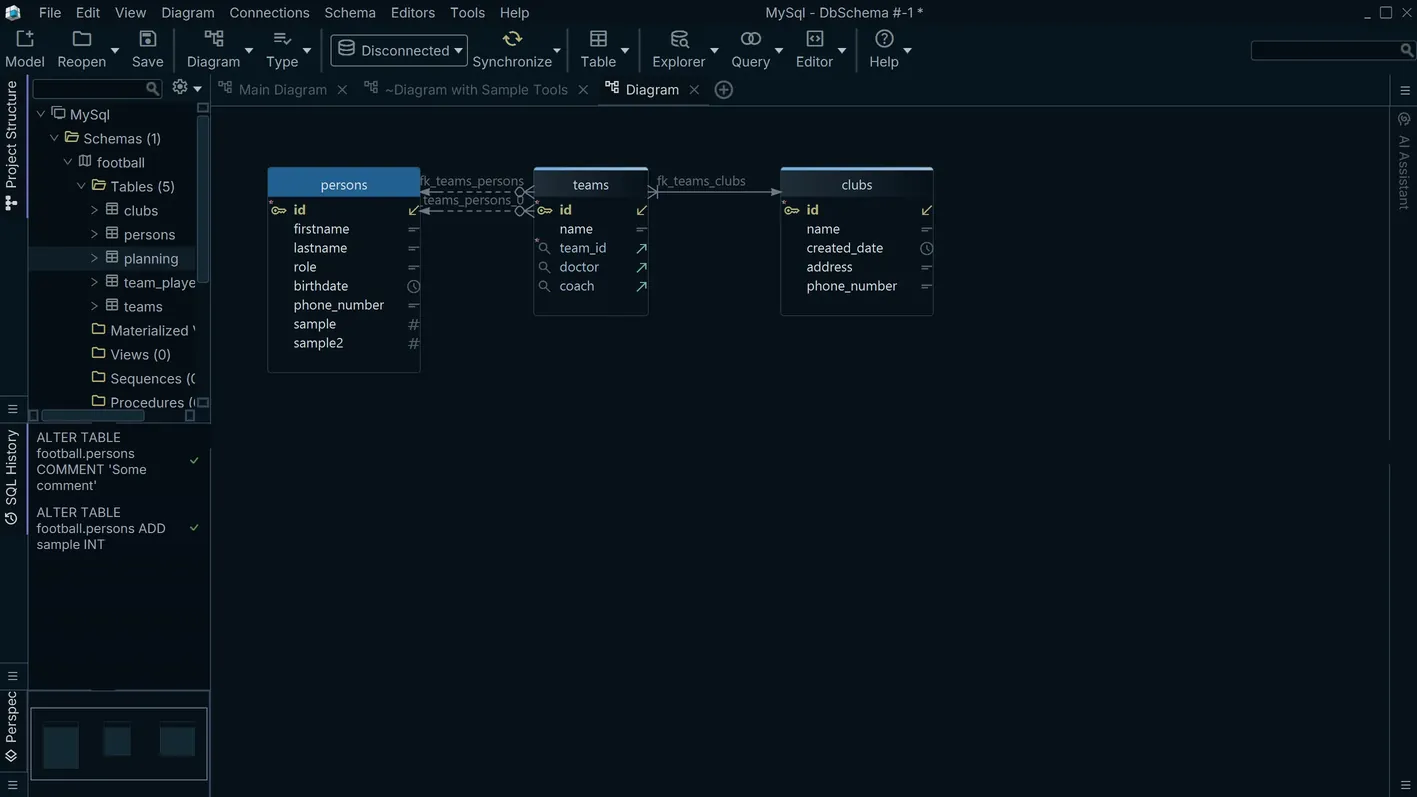
Document the SnappyData Cluster Schema
SnappyData cluster schemas often evolve rapidly as data engineering teams add tables for different workload types. DbSchema's documentation generator produces a point-in-time HTML report of all tables, column definitions, and storage types — a snapshot that can be reviewed and shared outside the cluster environment.
Connect DbSchema to a SnappyData Cluster
A working connection needs the driver JAR registered before the cluster details are entered:
- Install DbSchema.
- Download the SnappyData JDBC driver JAR from the SnappyData GitHub release page matching the server version you are running.
- Register the JAR in DbSchema's driver manager; the driver class is
io.snappydata.jdbc.ClientDriver. - Create a new connection using the cluster host and port 1527, which is the JDBC server's default, giving a URL of
jdbc:snappydata://host:1527/. - Connect, and DbSchema loads row-store and column-store table definitions into the diagram canvas.
Before connecting, ensure the SnappyData cluster lead node is running and the JDBC server component has been started.
Advantages of Pairing DbSchema With SnappyData
- Visualize row and column store table schemas together in a single diagram canvas.
- Run Spark SQL queries interactively without deploying a notebook or Spark application.
- Document SnappyData cluster schemas as point-in-time HTML reports for team reviews.
- Track schema evolution across cluster versions using DbSchema's Git integration.
- Design new tables and preview DDL before executing against the live cluster.
Get a clear picture of your row and column store tables before the next Spark job runs — download DbSchema for free, then pull the schema straight off your SnappyData cluster.
Related databases
Teams working with SnappyData often use these engines too. Explore dedicated guides and JDBC setup for each.