Diagram Any Neon Branch, Including pgvector Columns
Connect DbSchema to Neon and turn the live schema into an editable visual model: explore relationships in interactive ER diagrams, plan changes on the canvas, and generate reviewed SQL scripts for deployment.
The workflow is designed for relational modeling, migration planning, and SQL-first collaboration — keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Neon Features Download Neon JDBC Driver · All drivers
What happens after you download?
Get to your first Neon schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Neon or open a sample
Reverse engineer an existing Neon database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Neon's Serverless Architecture and Branch-Specific Schemas
Neon is a fully serverless PostgreSQL service built around a separation of compute and storage. Its most distinctive feature is database branching — you can fork your production database into an isolated branch in seconds, similar to creating a git branch, giving each developer or CI pipeline their own copy of the schema and data without duplicating storage. DbSchema connects to any Neon branch independently by using that branch's dedicated connection string, letting you reverse-engineer and visualize the schema that is specific to that branch.
Download DbSchema Free See Neon Features
Because branches can diverge over time as migrations are applied independently, DbSchema's visual diagrams become a practical tool for reviewing schema differences between branches before merging. The auto-suspend feature means that idle compute spins down automatically, which makes Neon cost-effective for development databases that are only used during business hours. DbSchema reconnects transparently when the branch wakes.
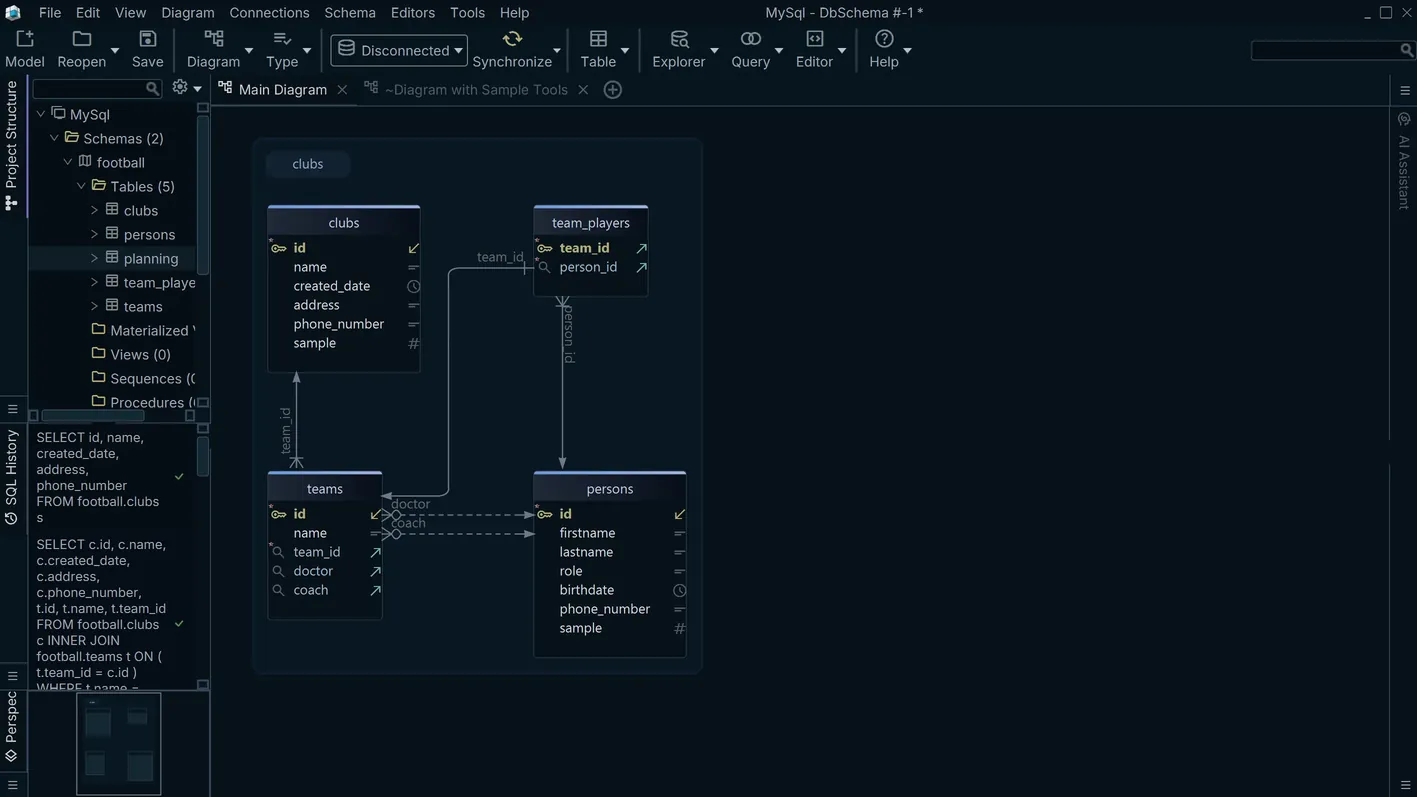
Writing PostgreSQL Queries Against Neon
Neon is wire-compatible with PostgreSQL, so every SQL feature you know — window functions, CTEs, lateral joins, full-text search — works without modification. DbSchema's SQL editor connects to Neon via the standard PostgreSQL JDBC driver and lets you author, execute, and iterate on queries directly against any branch. Results appear in the tabular results panel where you can sort, filter, and export them to CSV.
You can maintain separate query workspaces per branch by saving named connection profiles in DbSchema. This makes it easy to run the same query against both a feature branch and the main branch and compare results side by side, which is invaluable when validating that a schema migration does not change query output unexpectedly.
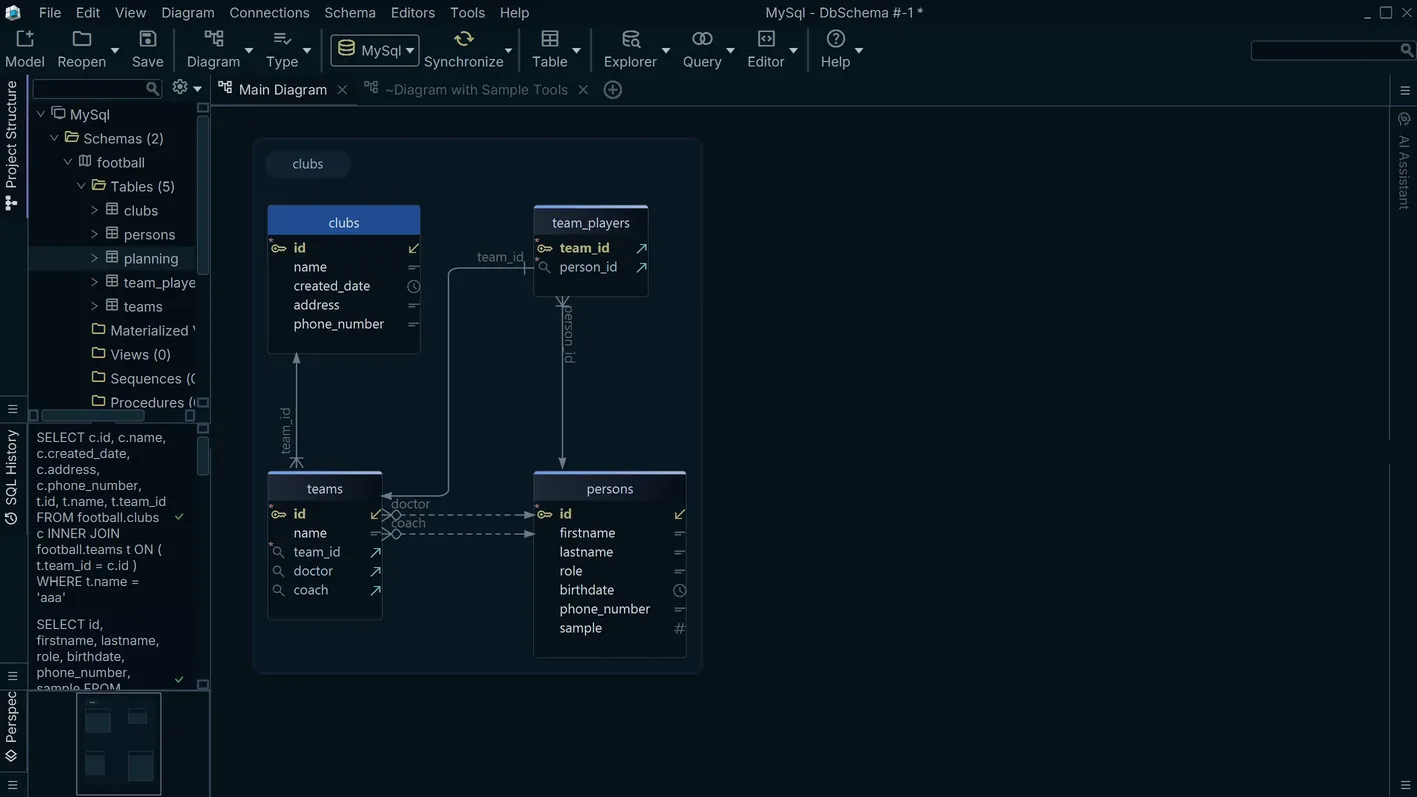
Exploring Neon Tables Including pgvector Data
Neon supports the pgvector PostgreSQL extension, which adds a vector column type for
storing ML embeddings. DbSchema's data explorer renders vector columns as array-like values so you
can visually confirm that your embedding pipeline is populating the right rows with the expected vector dimensions.
This is particularly useful when building RAG (retrieval-augmented generation) pipelines that depend on Neon as
their vector store.
Beyond vector data, the explorer lets you page through any table row by row, apply column-level filters, and inspect foreign-key relationships to understand how your application data is linked. Instant provisioning means you can spin up a fresh Neon branch for exploratory work and connect DbSchema within moments.

How to Connect DbSchema to a Neon Branch
Since Neon speaks the PostgreSQL wire protocol, connecting is mostly a matter of copying the right string from the Neon dashboard.
- Install DbSchema — the PostgreSQL JDBC driver (
org.postgresql.Driver) is included by default, so nothing extra to download. - Open the Neon dashboard and copy the connection string for the branch you want to inspect.
- In DbSchema, select PostgreSQL as the database type and paste the details in; the URL takes the
form
jdbc:postgresql://ep-xxx.us-east-2.aws.neon.tech/mydb?sslmode=require, where the hostname encodes the compute endpoint ID (ep-xxx), the AWS region, and the Neon domain. - Connect — DbSchema reverse-engineers the schema for that specific branch into an ER diagram.
For applications making many short-lived connections, Neon also provides a pooler endpoint whose
hostname ends in -pooler.us-east-2.aws.neon.tech; using that URL in DbSchema reduces
connection overhead and avoids exhausting the PostgreSQL connection limit on small compute tiers.
SSL (sslmode=require) is mandatory for every Neon connection and is already enforced in
the connection string Neon generates. Because each branch exposes its own endpoint, save a separate
DbSchema connection profile per branch to switch between them without re-entering credentials.
What DbSchema Brings to a Branched Neon Workflow
- Visualizes per-branch schemas to make migration reviews and schema diffing faster and more visual.
- Lets developers explore production-like data in ephemeral branches without connecting to the live database.
- Provides a GUI query editor for branches where no other SQL tooling is configured, which is common in CI environments.
- Surfaces pgvector embedding columns in the data explorer, simplifying AI/ML pipeline debugging.
- Manages multiple Neon connection profiles (main branch, dev branch, CI branch) in one place.
- Generates offline schema documentation for compliance and architectural review purposes.
Spinning up a new Neon branch for a migration review? Download DbSchema and diagram that branch's schema — pgvector columns included — before you open a pull request.
Frequently asked questions
Related databases
Teams working with Neon often use these engines too. Explore dedicated guides and JDBC setup for each.