Diagram and Query Google AlloyDB's HTAP Architecture
Connect DbSchema to Google AlloyDB and turn the live schema into an editable visual model: explore relationships in interactive ER diagrams, plan changes on the canvas, and generate reviewed SQL scripts for deployment.
The workflow is designed for relational modeling, migration planning, and SQL-first collaboration — keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See Google AlloyDB Features Download Google AlloyDB JDBC Driver · All drivers
What happens after you download?
Get to your first Google AlloyDB schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to Google AlloyDB or open a sample
Reverse engineer an existing Google AlloyDB database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
PostgreSQL-Compatible Architecture with Google's Columnar Engine
Google AlloyDB is a fully managed PostgreSQL-compatible database service on Google Cloud designed for demanding OLTP workloads while simultaneously supporting fast analytical queries through an integrated columnar engine. The columnar engine automatically selects hot columns based on query patterns and maintains an in-memory columnar store in parallel with the row-based primary storage, enabling hybrid transactional and analytical processing (HTAP) without separate ETL pipelines. Additional features such as ML-based query optimizer tuning, pgvector support for AI embeddings, AlloyDB AI integration, and AlloyDB Omni for on-premises deployments distinguish it from standard Cloud SQL PostgreSQL. DbSchema relies on the same standard PostgreSQL JDBC driver to introspect AlloyDB schemas — including extensions, foreign tables, and partitioned tables — and renders them as interactive schema diagrams.
Download DbSchema Free See Google AlloyDB Features
Writing HTAP Queries in the SQL Editor
Because AlloyDB exposes a fully PostgreSQL-compatible SQL interface, DbSchema's SQL editor connects
seamlessly and provides the same auto-completion, syntax highlighting, and result grid features as
with any PostgreSQL database. You can write OLTP queries with row-level locking alongside analytical
aggregations that benefit from the columnar engine, all within the same connection. AlloyDB's
automatic columnar acceleration is transparent to the query author; DbSchema's editor shows actual
execution time so you can observe the performance difference between queries routed to row storage and
those accelerated by the columnar engine. The editor also supports pgvector operators
for similarity search queries used in AI and machine learning workflows.
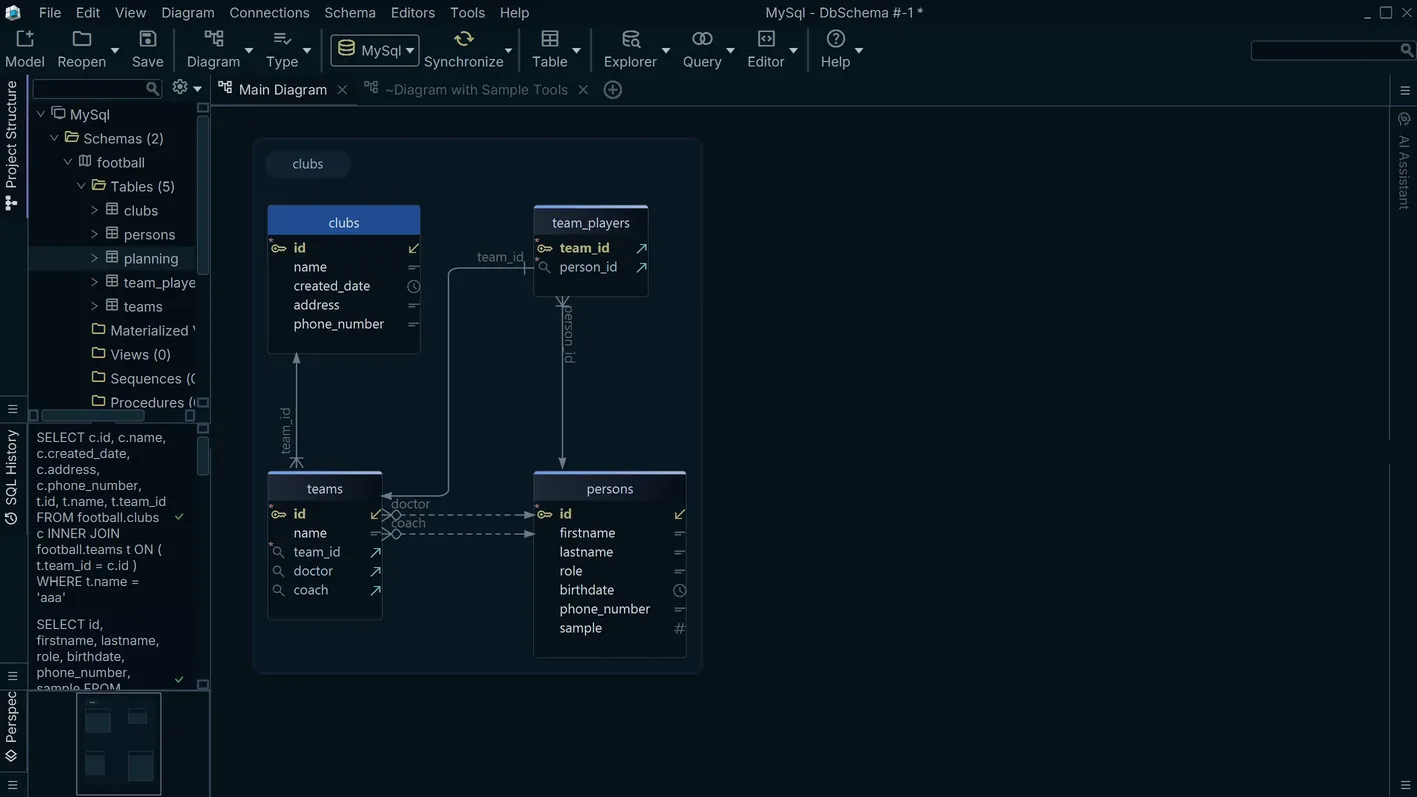
Exploring AlloyDB Tables and Columnar Data
The DbSchema data explorer lets you browse AlloyDB table contents row by row with full filter and sort
support for all PostgreSQL data types including arrays, JSONB, and vector columns. For
AlloyDB read replicas — which are extremely fast because they serve reads directly from the columnar
cache — the data explorer delivers near-instantaneous pagination even on very large tables. You can
connect DbSchema to both the primary instance and read replicas simultaneously, switching between them
in the connection panel to compare data consistency or test replica lag scenarios.

Connecting DbSchema to Google AlloyDB
- Install DbSchema — free for Windows, macOS, and Linux, with no account required.
- Create a new connection using the standard PostgreSQL JDBC driver
(
org.postgresql.Driver) that DbSchema already includes. - Since AlloyDB does not have a public IP by default, start the AlloyDB Auth Proxy or configure Private Service Connect so JDBC traffic can reach it from outside Google Cloud.
- Enter the JDBC URL
jdbc:postgresql://alloydb-instance:5432/mydb, wherealloydb-instanceis the private IP of your AlloyDB primary instance or the address exposed by the Auth Proxy, along with a PostgreSQL-compatible username and password (or IAM database authentication using a Cloud SQL Auth Proxy token). - Connect — DbSchema introspects schemas, extensions, foreign tables, and partitioned tables into an interactive diagram. For high-availability deployments, point DbSchema at the AlloyDB cluster endpoint, which automatically routes to the current primary.
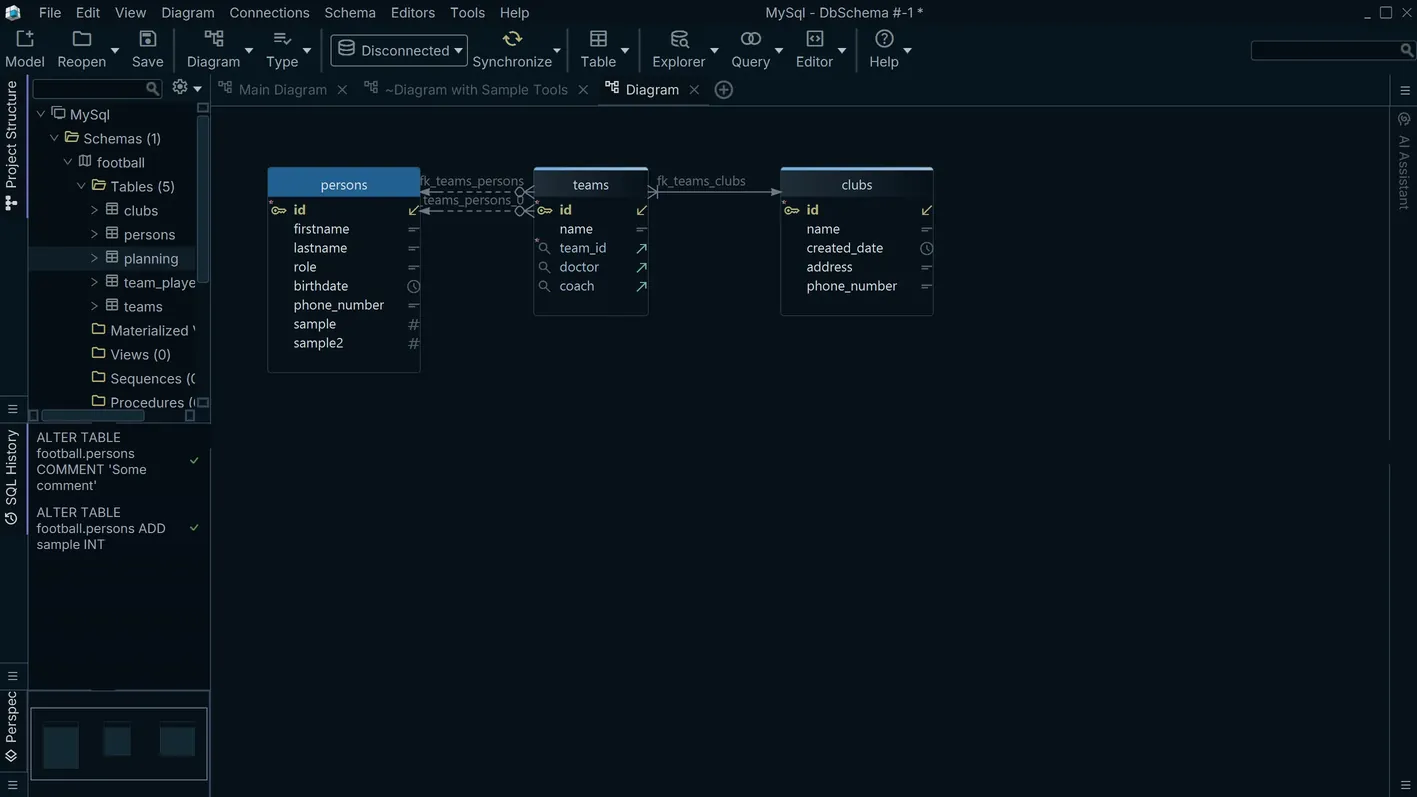
Why Google AlloyDB Users Add DbSchema
- Visualize AlloyDB PostgreSQL-compatible schemas — including partitioned tables, foreign tables, and pgvector columns — in a clear schema diagram for developer documentation.
- Write HTAP queries that mix OLTP row reads with analytical aggregations in DbSchema's SQL editor and observe columnar engine acceleration in real time.
- Explore table data via fast AlloyDB read replicas in the data explorer for near-instant row browsing on analytical workloads.
- Connect DbSchema to AlloyDB Omni for on-premises environments using the same PostgreSQL JDBC driver configuration as cloud AlloyDB.
- Generate schema documentation that captures AlloyDB-specific extensions (pgvector, pg_bigm) alongside standard PostgreSQL object definitions.
- Use DbSchema's existing PostgreSQL driver support to connect to AlloyDB with zero additional driver configuration, leveraging full protocol compatibility.
Partitioned tables, pgvector columns, and HTAP query plans are easier to reason about once they share one diagram. Download DbSchema free and connect to your AlloyDB instance with the PostgreSQL driver you already trust.
Related databases
Teams working with Google AlloyDB often use these engines too. Explore dedicated guides and JDBC setup for each.