Understand CUBRID's Object-Relational Schemas at a Glance
Build a clearer workflow for CUBRID: reverse engineer existing schemas into interactive ER diagrams, model changes visually, and generate reviewed SQL scripts before deployment.
DbSchema is built for visual modeling, schema documentation, and deployment. Keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See CUBRID Features Download CUBRID JDBC Driver · All drivers
What happens after you download?
Get to your first CUBRID schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to CUBRID or open a sample
Reverse engineer an existing CUBRID database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Object-Relational Model and Schema Visualization
CUBRID is a Korean open-source relational database management system that extends standard relational concepts with object-oriented features, making it an object-relational database. In CUBRID, tables are referred to as classes, rows as instances, and stored procedures can be attached directly to classes as methods — a distinction that gives CUBRID strong object-oriented database (OODBMS) characteristics. DbSchema connects via the CUBRID JDBC driver and introspects classes, their attributes (columns), inheritance hierarchies, and method signatures, rendering the full object-relational model as an interactive schema diagram. This is especially helpful for understanding legacy CUBRID schemas that make heavy use of class inheritance and method delegation.
Download DbSchema Free See CUBRID Features
Writing SQL with Collection Types in the SQL Editor
CUBRID supports three collection data types — SET, MULTISET, and
SEQUENCE — that allow a single column to store multiple values of a declared element type,
a feature rarely found in mainstream relational databases. DbSchema's SQL editor connects over the
CUBRID JDBC driver and provides auto-completion for class and attribute names, supporting queries that
use CUBRID's collection operators such as CONTAINS, SUBSET, and element
subscript access. The results grid handles collection-type column values by rendering them as
comma-separated lists, making the contents of SET and SEQUENCE attributes readable without additional
post-processing.
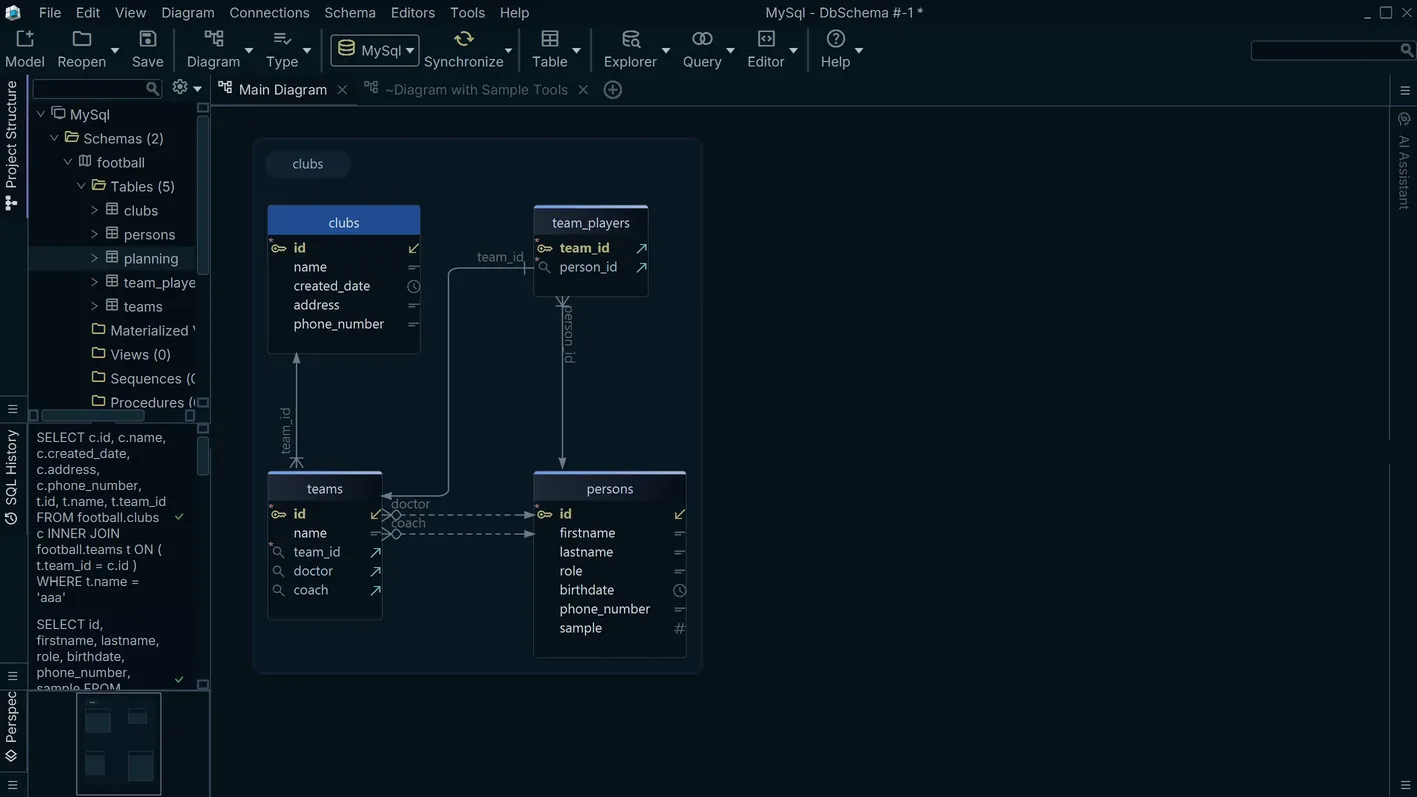
Browsing CUBRID Tables and Rows with the Data Explorer
The DbSchema data explorer lets you navigate CUBRID class contents row by row with filter and sort controls that work across all standard attribute types including CUBRID's collection columns. For databases that use class inheritance, the explorer lists both the direct class instances and optionally instances of subclasses, giving a complete view of the inheritance hierarchy in a single result set. You can inspect collection-type attribute values inline, copy individual rows to the clipboard, and export page contents to CSV for use in spreadsheet analysis or migration validation.

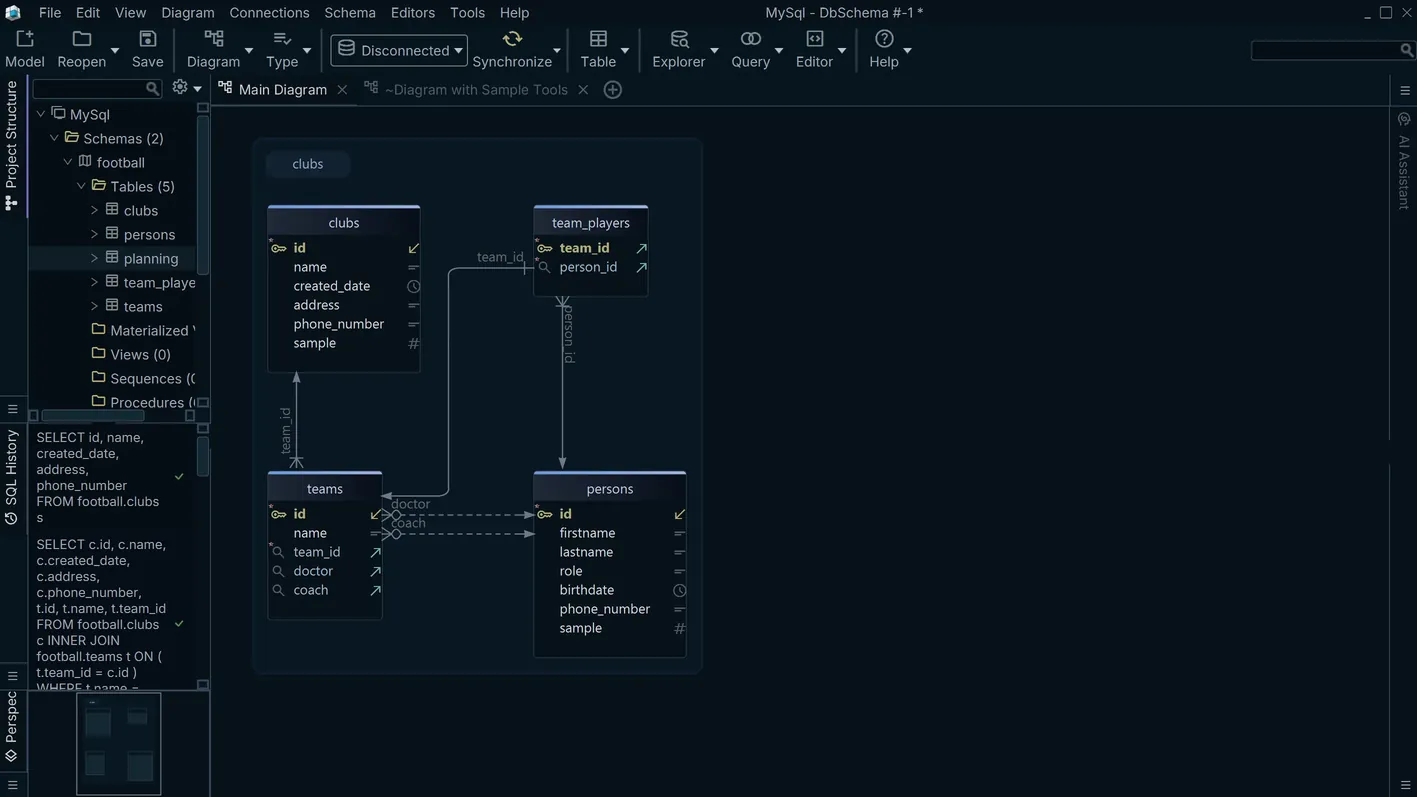
Connecting DbSchema to a CUBRID Database
Reaching a live CUBRID diagram from a fresh DbSchema install takes five steps:
- Grab the free installer — DbSchema runs the same way on Windows, macOS, and Linux, with no account needed.
- Download the CUBRID JDBC driver JAR (
cubrid.jdbc.driver.CUBRIDDriver) from the CUBRID downloads page and register it in DbSchema's driver manager. - Enter the CUBRID server hostname, the default broker port 33000, and the target database name so the connection matches the URL form
jdbc:cubrid:localhost:33000:mydb:::(the trailing colons are placeholders for optional username, password, and charset parameters). - Supply a username and password with the required class-level privileges in the connection dialog.
- Connect — DbSchema loads classes, attributes, and inheritance hierarchies into the ER diagram.
For HA-enabled CUBRID clusters, use the HA URL format that lists multiple host:port pairs separated by commas instead of a single hostname.
Why Teams Use DbSchema with CUBRID
- Visualize CUBRID's class hierarchy and method associations as a schema diagram, making the object-relational model easy to communicate to new team members.
- Write and test SQL that uses CUBRID collection types (
SET,MULTISET,SEQUENCE) in the SQL editor with column name auto-completion. - Browse class instances including collection column values in the data explorer without writing manual pagination queries.
- Generate schema documentation for CUBRID databases to serve as a reference during migration or refactoring projects.
- Design new CUBRID schemas with class relationships and collection attributes in DbSchema's offline model before deploying changes.
- Connect to CUBRID HA clusters with automatic failover support through the CUBRID JDBC driver's multi-host URL format.
Ready to map out a CUBRID class hierarchy visually? Download DbSchema for free and get an ER diagram from your database in minutes.
Related databases
Teams working with CUBRID often use these engines too. Explore dedicated guides and JDBC setup for each.