Amazon DynamoDB with DbSchema — Reverse-Engineer, Design, and Explore Your Tables

Amazon DynamoDB's schemaless design makes it fast to start building, but as your application evolves, understanding the actual data model becomes harder. Tables accumulate attributes, access patterns multiply, and new team members have no clear picture of how data is structured. DbSchema bridges that gap: it connects to DynamoDB, reverse-engineers the table and index structures into a visual design model, and gives you a full set of tools to document, share, and explore your data.
1. Reverse-Engineering the Schema from DynamoDB
When you connect DbSchema to DynamoDB using the open-source DynamoDB JDBC driver, DbSchema samples each table and infers the schema structure — partition keys, sort keys, Global Secondary Indexes (GSIs), Local Secondary Indexes (LSIs), and the attribute types observed across sampled items. The result is displayed as an interactive entity-relationship diagram on the canvas, where each table shows its key structure and each index appears as a linked node.
Because DynamoDB is schemaless, different items in the same table can carry different attributes. DbSchema handles this by sampling a configurable number of items and building a union of all observed attribute names and types. The diagram gives your team a working reference of what the data actually looks like in production — not just what the key schema says.
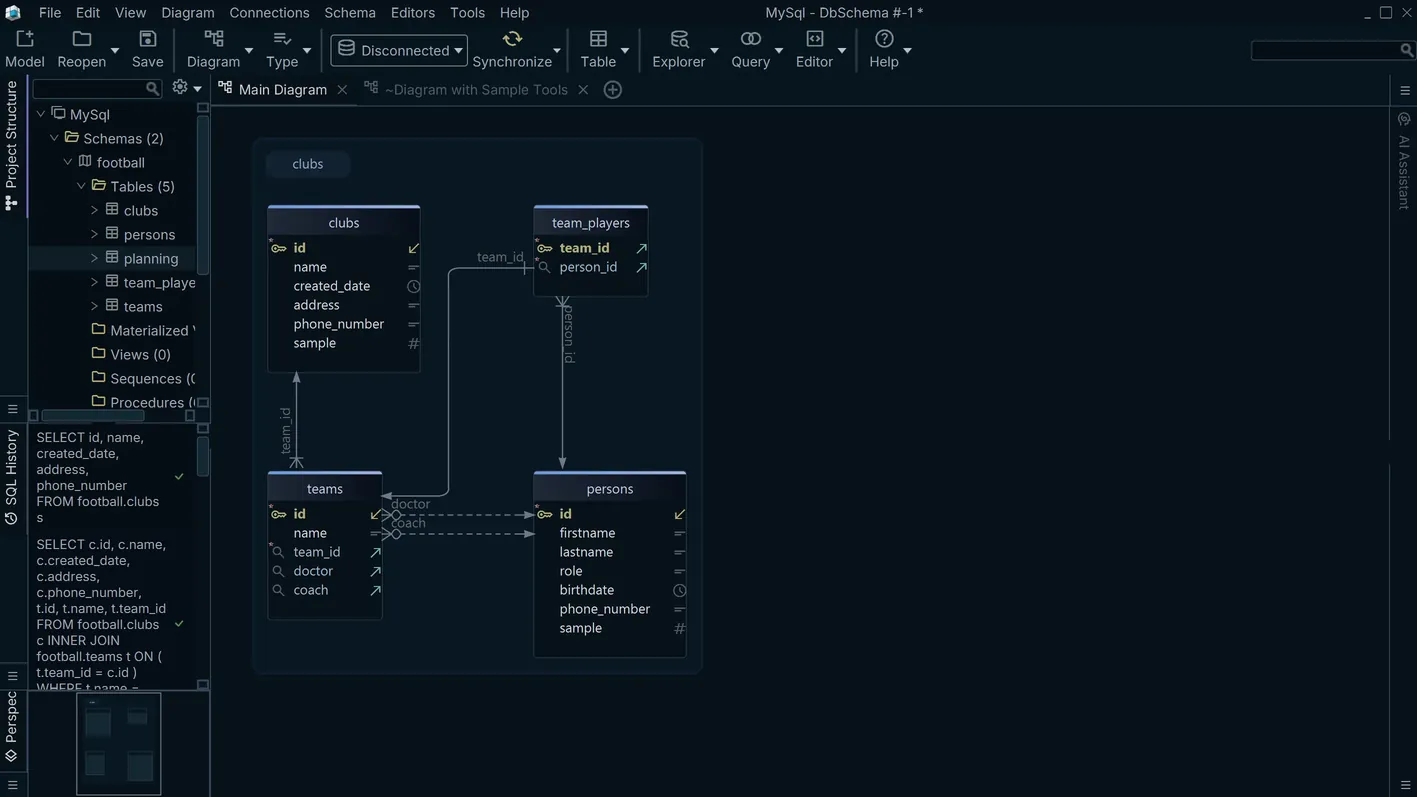
2. Saving the Schema to a Design Model File
Once reverse-engineered, the schema is saved into a .dbs project file. This file is XML-based and stores the complete design model: tables, attributes, indexes, virtual relationships, diagram layouts, and any documentation comments you add. The .dbs file is independent of the live database — you can open and work with it offline, inspect it in any text editor, and review the full schema without an active DynamoDB connection.
One practical consequence: when a new developer joins the team, they do not need AWS credentials to review the data model. They open the .dbs file in DbSchema and see the complete schema diagram immediately. Architects can design table changes in the model offline and synchronize to the live database when ready, without keeping a DynamoDB connection open throughout the design session.
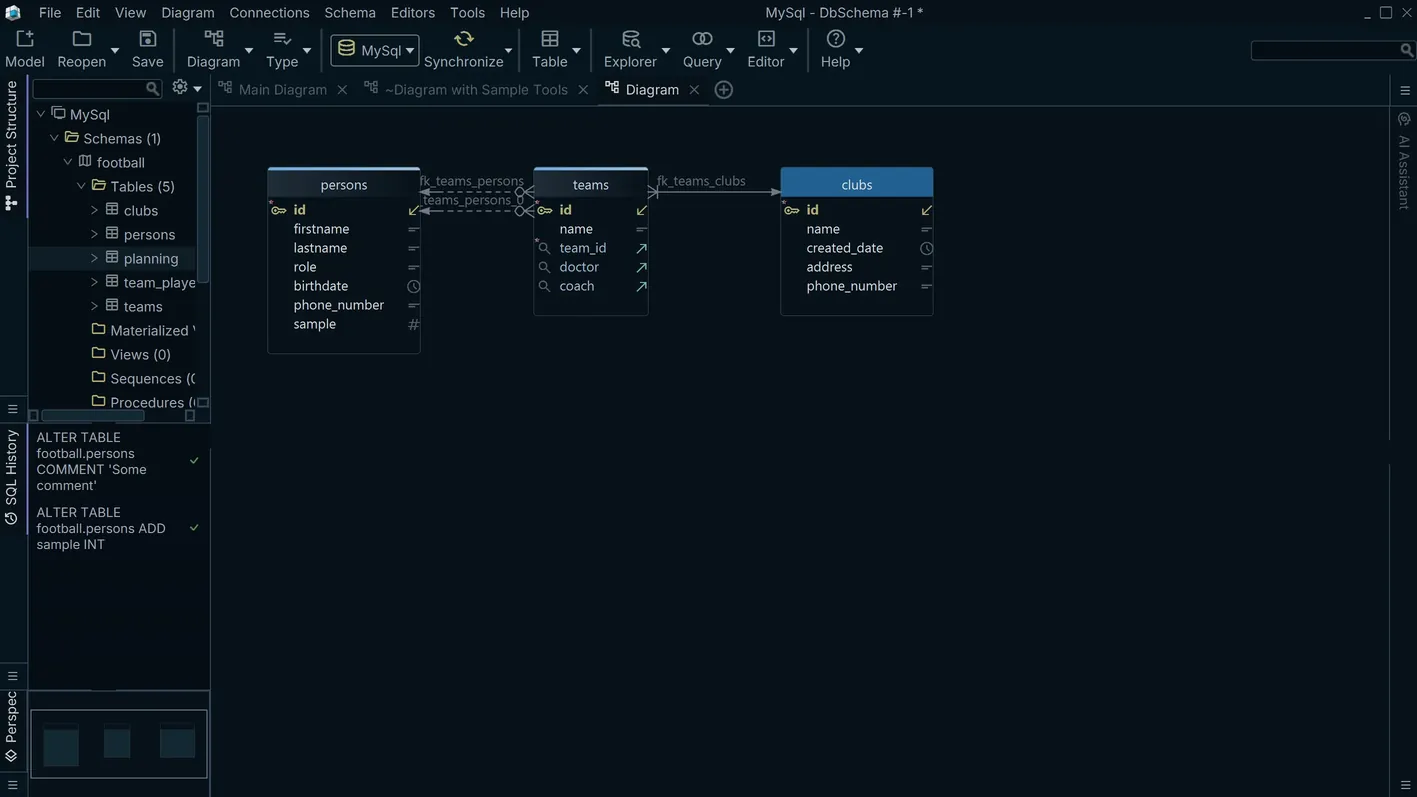
3. Sharing the Schema with Git
Because the .dbs file is plain XML, it works naturally with Git. Commit the file to your repository alongside your application code, and every schema change is tracked with a full history: who changed it, when, and why. Teams use this workflow to review schema changes in pull requests, branch for experimental access-pattern designs, and roll back to a previous model if a design direction proves wrong.
DbSchema integrates directly with Git from within the application. You can commit, push, pull, and review diffs without leaving DbSchema. When a teammate updates the schema model and pushes, you pull the changes and DbSchema immediately shows the updated diagram. For teams working across time zones, this is the simplest way to keep everyone aligned on the DynamoDB data model without scheduling meetings or writing manual changelogs.
4. Deploying the Schema Across Multiple Environments
A DynamoDB deployment typically spans at least three environments: local (DynamoDB Local for development), staging, and production. The schema model saved in the .dbs file can be compared against any of these environments. DbSchema's schema synchronization connects to the target DynamoDB instance, compares it against the model, highlights tables and indexes that exist in one but not the other, and generates the statements needed to bring them into alignment.
This makes it straightforward to provision a fresh DynamoDB Local instance for a new developer or a CI environment: connect DbSchema, run synchronization from the model, and the required tables and indexes are created. The same model drives every environment, eliminating the risk of configuration drift where a staging table is missing a GSI that production relies on.
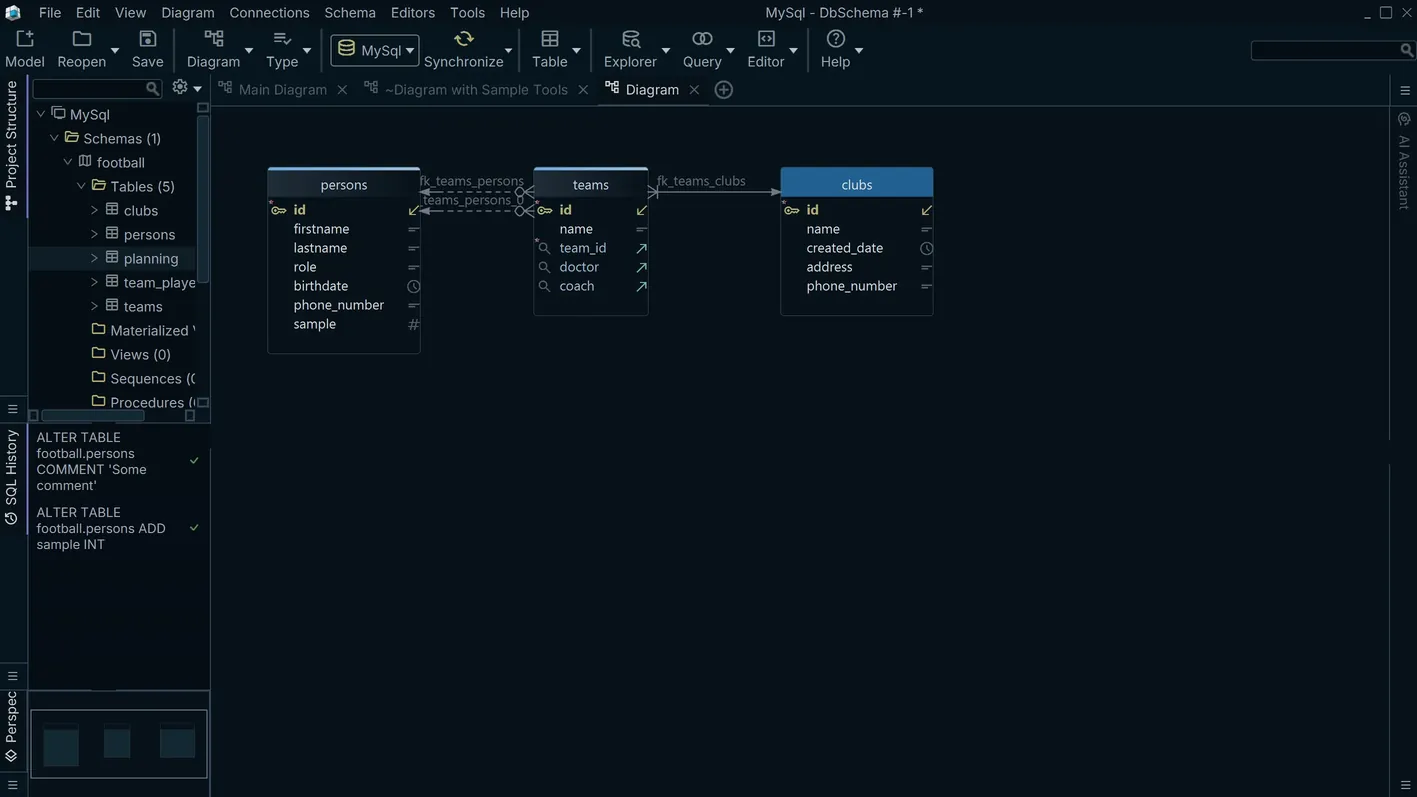
5. Creating Virtual Foreign Keys
DynamoDB does not enforce referential integrity — there are no native foreign keys. But in practice,
DynamoDB tables almost always have relationships. An Orders table references
Customers by customerId. A ProductReviews table references
both Products and Users. These relationships exist in application code
but are invisible in the database schema itself.
DbSchema lets you define virtual foreign keys — relationships that live in the
.dbs model file and are never sent to the database. In the diagram, they appear as connecting lines
between tables, making the data model immediately readable. Virtual foreign keys also activate
relational navigation in the data explorer: when browsing a row in the Orders table,
you can click the customerId value and DbSchema navigates to the matching row in
Customers. This turns a collection of independent tables into a navigable
relational model.
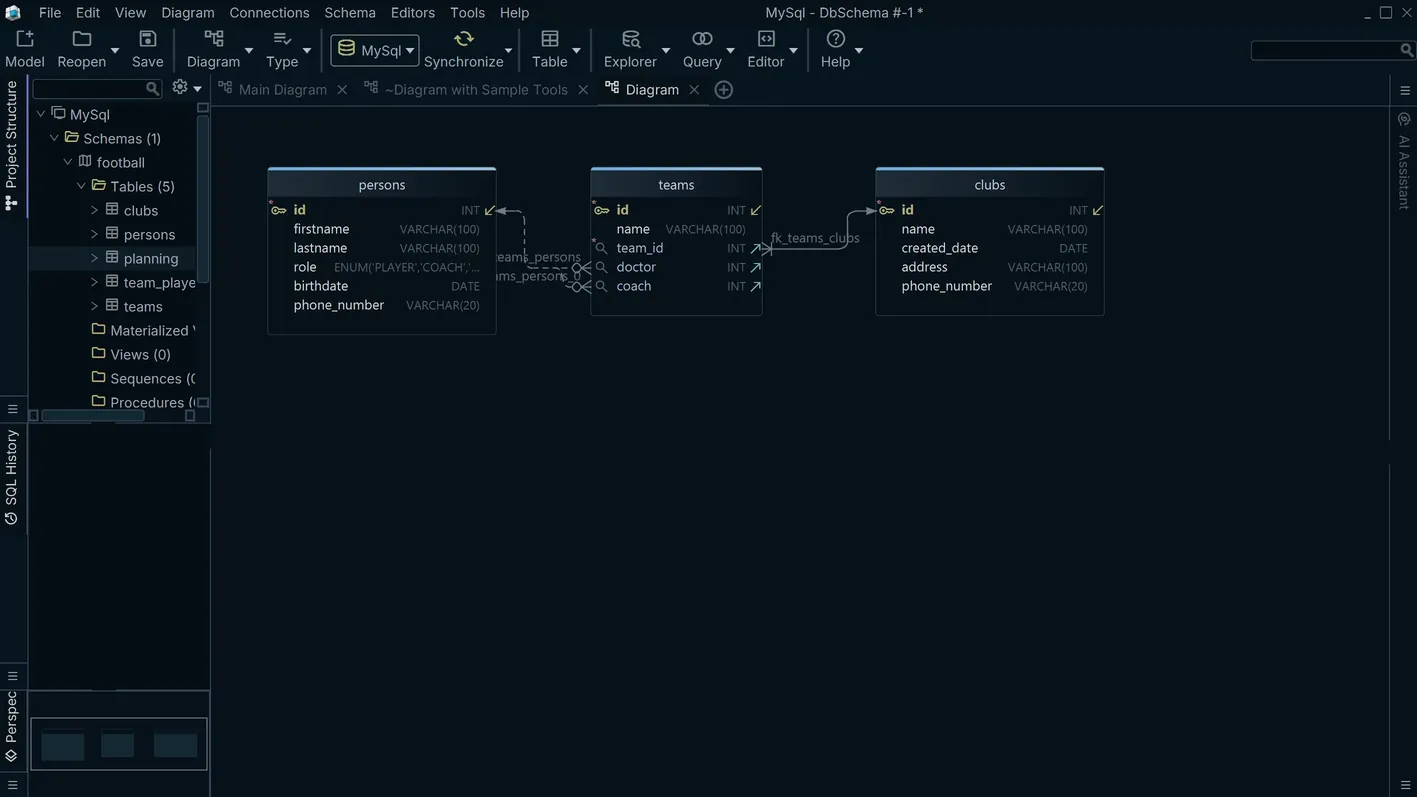
6. Exploring Data with the Data Explorer
The data explorer provides a visual interface for browsing DynamoDB table items. Open any table, apply filters on partition key or attribute values, paginate through results, and inspect the full structure of individual items. For tables that store nested documents as attributes, the explorer expands nested fields as additional columns so you can review the complete item shape at a glance without reading raw JSON.
With virtual foreign keys defined, the explorer becomes relational: clicking a foreign key value in one table immediately queries the referenced table for the matching record. This navigation is especially useful when debugging production data issues — you can trace a customer order through several related tables without writing a series of separate PartiQL queries or switching between the AWS console and a shell.

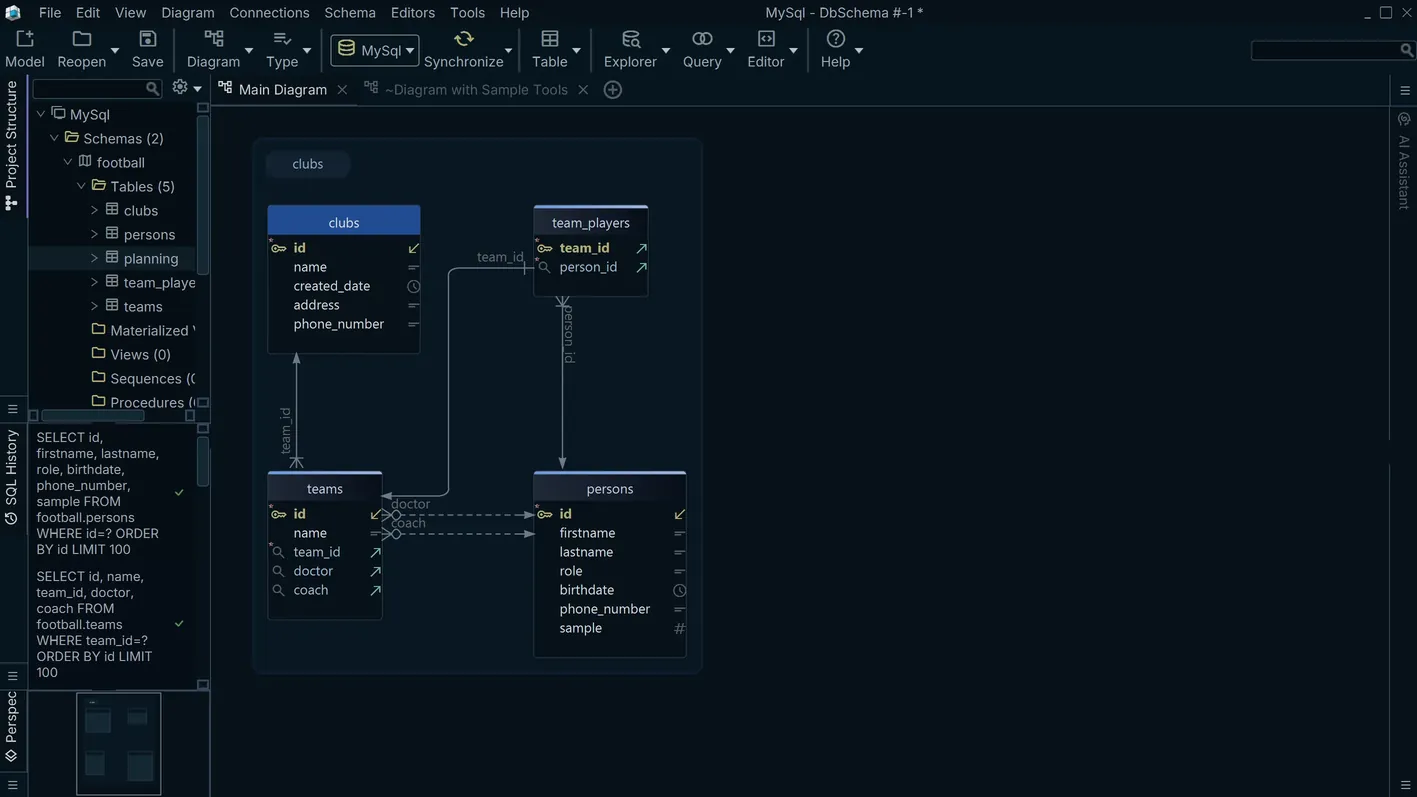
7. Building Queries Visually with the Query Builder
DbSchema's query builder lets you construct SQL-style queries against DynamoDB tables by clicking rather than typing. Select a table, choose the attributes to project, add filter conditions on any attribute, and specify sort order. DbSchema translates the visual selection into PartiQL and executes it against DynamoDB through the JDBC driver, returning results in a paginated grid.
The query builder is particularly useful for analysts and developers who need to answer ad-hoc questions about DynamoDB data without memorizing PartiQL syntax or the DynamoDB API. Partition key conditions are surfaced clearly in the interface, making it easy to write cost-efficient queries that target a specific partition rather than scanning an entire table.
8. Generating Test Data with the Data Generator
Before deploying an application against a new DynamoDB table structure, it helps to have realistic test data. DbSchema's data generator populates DynamoDB tables automatically, generating values that respect the attribute types and rules you define: date ranges for timestamp attributes, realistic names and emails for string fields, valid numeric ranges for numeric attributes.
You can control the volume of generated rows and configure custom generation rules per attribute.
Because the data generator is aware of virtual foreign keys, it produces referentially consistent
data across tables: every generated Orders row will reference a customerId
that was generated into the Customers table first. This makes the generated dataset
immediately useful for integration tests and performance benchmarks, without any manual cleanup to
fix broken references.
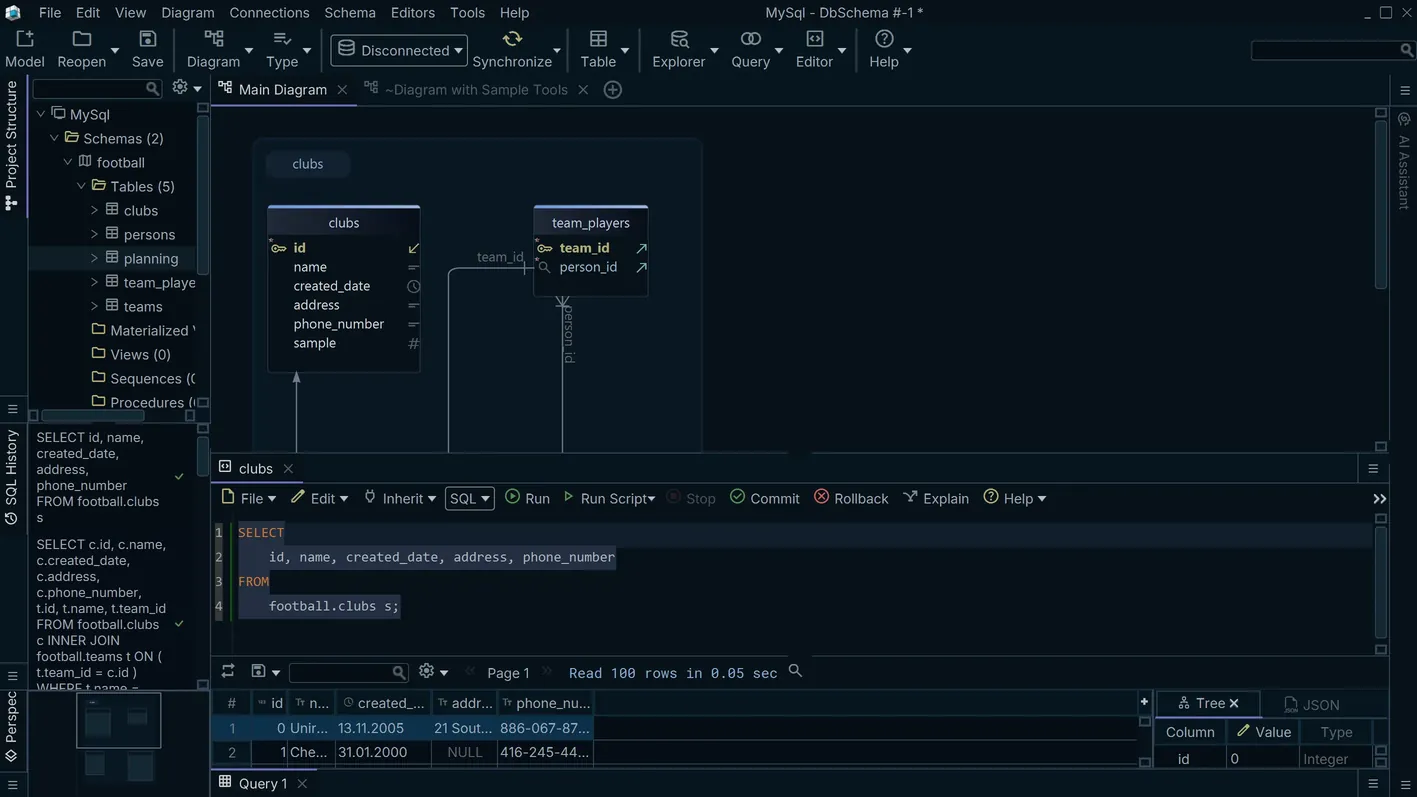
Getting Started with DbSchema and DynamoDB
DbSchema connects to DynamoDB using the open-source JDBC driver bundled with the application. In
the connection dialog, provide your AWS Access Key ID, Secret Access Key, and target region, or use
jdbc:dynamodb://localhost:8000 to connect to DynamoDB Local during development. Once
connected, DbSchema reverse-engineers the schema in seconds and you can start building the design
model, defining virtual foreign keys, and exploring data immediately.







