Download Hive JDBC Driver
What Is a JDBC Driver?
A JDBC driver is a Java library file (.jar) that enables Java applications to communicate with a database. The JDBC is a standard interface implemented by each database with a specific driver. Drivers are typically distributed by the database vendor or as open-source projects.
Understanding the JDBC URL
The connection parameters including the database location, database name and connection method are passed to the driver using the JDBC URL. The JDBC URL is a text starting with 'jdbc:...' which combines the hostname, port, database name, and any driver-specific parameters. The exact syntax can be different for each JDBC driver.
The Hive JDBC Driver
Apache Hive is a data warehouse system built on Hadoop, enabling SQL-like queries (HiveQL) over large datasets stored in HDFS or cloud object storage. It is widely used for batch ETL processing, data lake querying, and as a metastore for Spark and Presto/Trino workloads.
We use the Hive Uber driver. The JDBC source code is located on https://github.com/timveil/hive-jdbc-uber-jarThe driver archive is a zip file. Extract it and load the .jar files using DbSchema's Driver Manager.
DbSchema and Apache Hive
DbSchema connects to Hive via the Hive Uber JDBC driver and renders Hive tables, partitions, and views in the schema diagram. Use the SQL Editor to write HiveQL with partition filters and bucketing hints for optimal query performance.

Test the JDBC Driver using DbSchema
Get to your first ER diagram in minutes. No account, no credit card.
Install DbSchema in minutes
DbSchema is free. Download the installer for Windows, macOS, or Linux and start DbSchema. No signup required.
Connect or open a sample
Reverse engineer an existing database or open a sample model to explore tables, relations, and indexes visually.
Design, document, deploy
Edit your schema, generate interactive documentation, and roll out reviewed changes across environments.
Explore Hive Visually with DbSchema
Once the JDBC driver is configured, DbSchema connects to your Hive database and gives you a full graphical workbench — no command-line required. Available as a free Community Edition and a full-featured PRO Edition. No registration needed to get started.
Interactive ER Diagrams
Reverse-engineer your Hive schema into a drag-and-drop ER diagram. Arrange tables visually, add new columns, define foreign keys, and let DbSchema generate the DDL — all without writing SQL by hand.
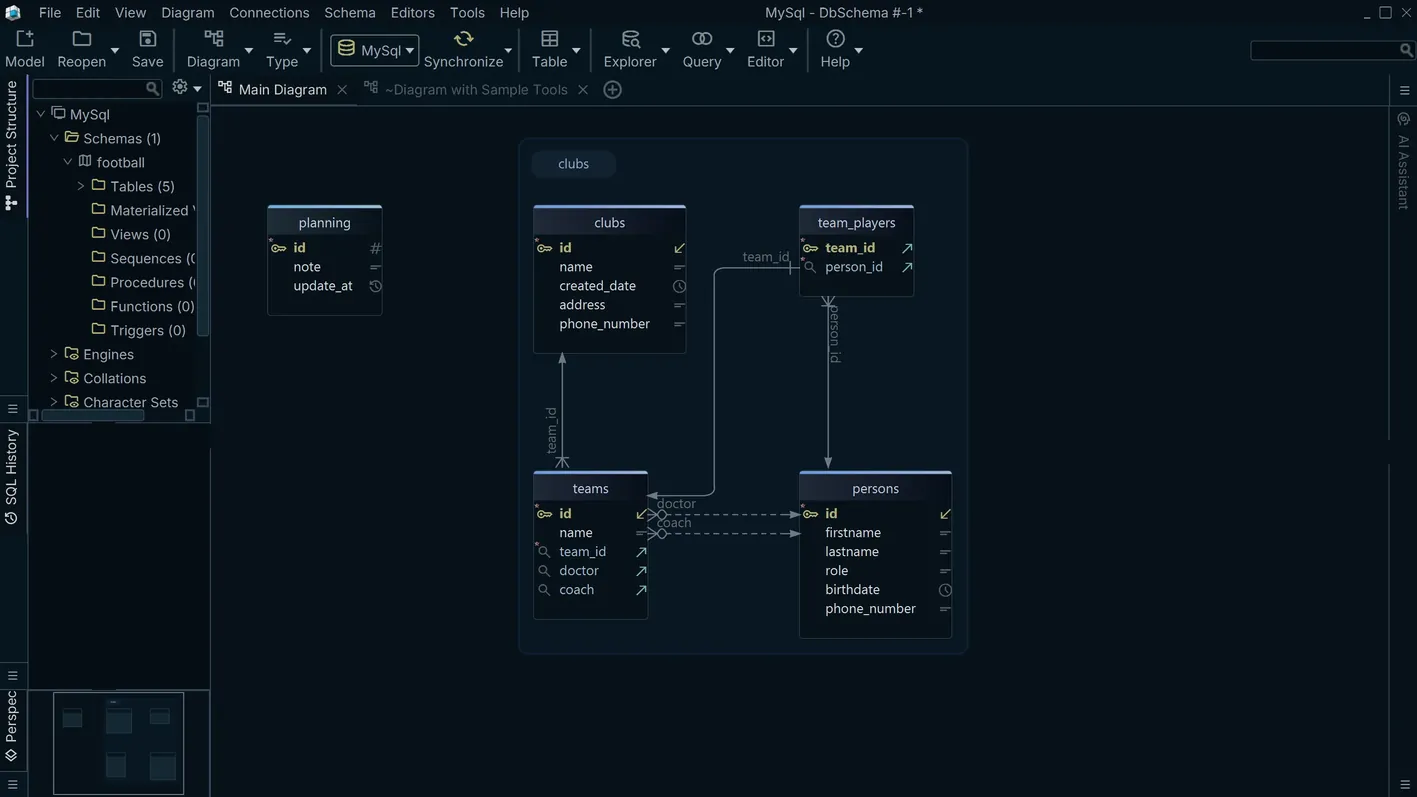
Visual Query Builder
Compose Hive queries by clicking on tables and columns — no SQL knowledge required. Add joins, filters, groupings, and aggregations through a point-and-click interface, then copy the generated SQL or run it directly against the live database.
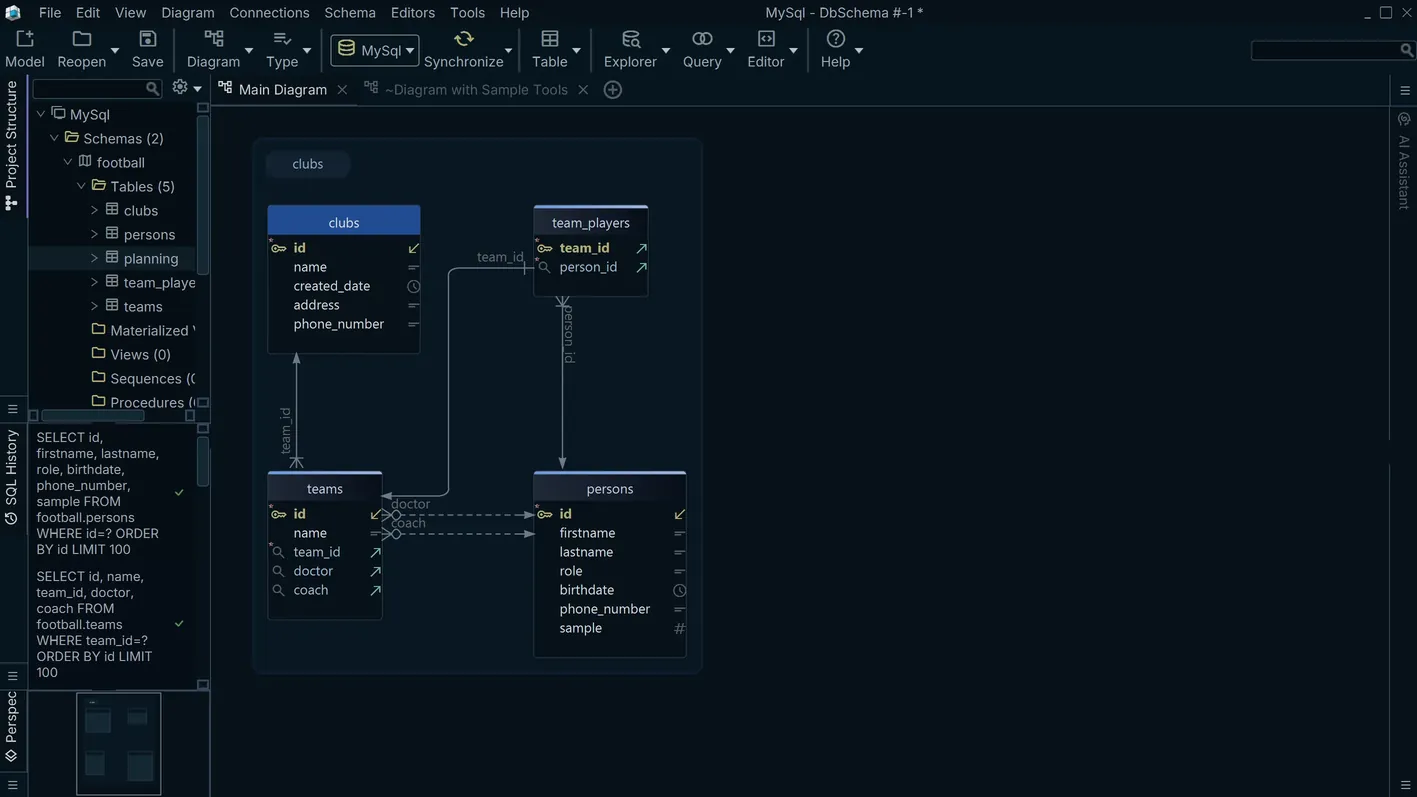
Relational Data Explorer
Browse Hive table data and follow foreign key relationships across tables in a single view. Edit cells inline, filter rows, and paginate through large datasets — all without leaving the explorer.

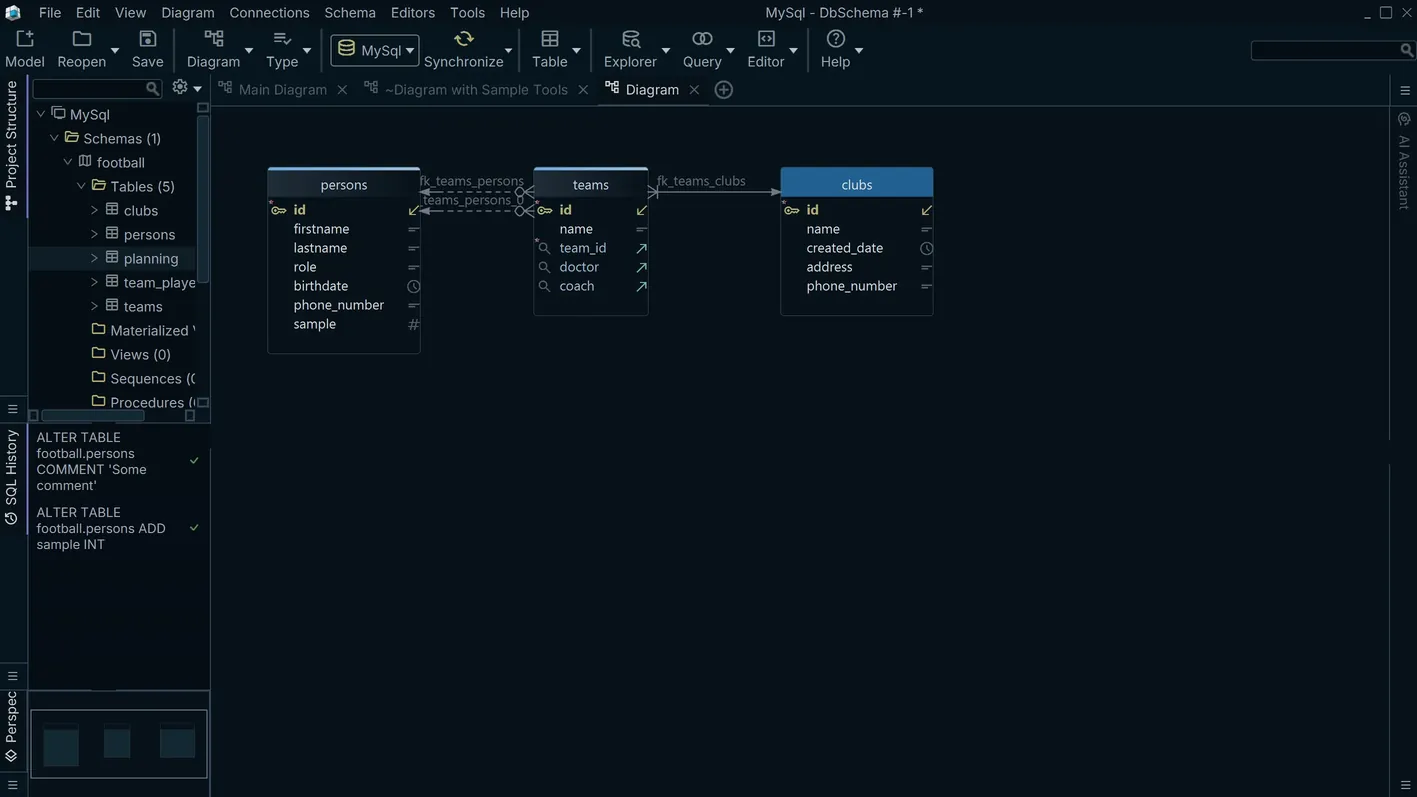
Schema Synchronization
Compare your Hive schema across development, staging, and production environments. DbSchema generates the exact ALTER statements needed to close the gap and lets you review every change before executing — reducing the risk of unintended schema drift.
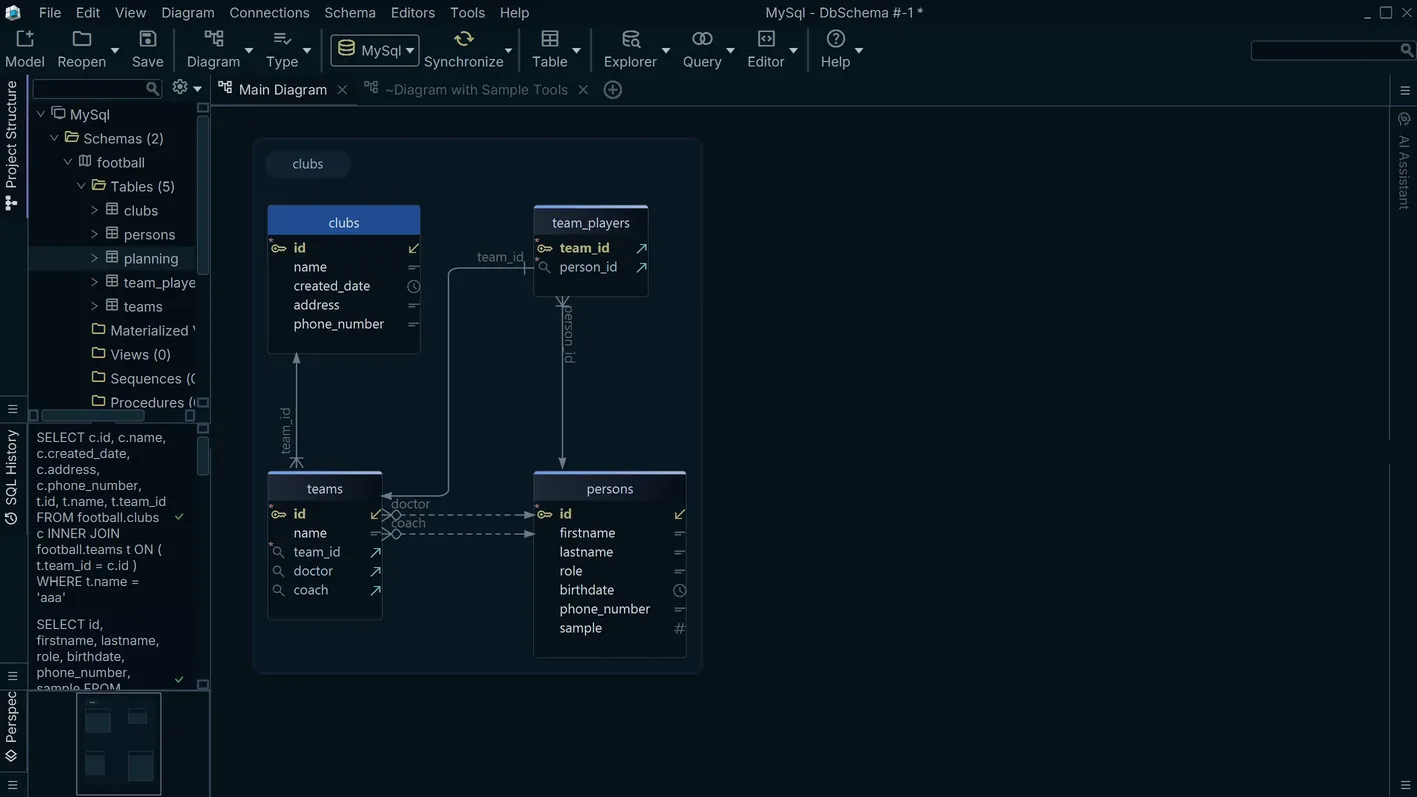
SQL Editor
Write and execute Hive queries in the integrated SQL editor with schema-aware autocomplete, syntax highlighting, and instant result display. Run scripts, inspect execution plans, and export results to CSV or JSON from a single interface.
HTML Schema Documentation
Generate a static HTML site documenting every table, column, type, index, and relationship in your Hive schema. Share it with your team or embed it in your project wiki — no extra tooling required.
For the full feature list and edition comparison, visit the DbSchema PRO Edition page.
Go deeper with Hive in DbSchema
ER diagrams, Git-based versioning, random data generator, and HTML schema docs.