See Your CrateDB Shards and Replicas as a Diagram
Connect DbSchema to CrateDB and turn the live schema into an editable visual model: explore relationships in interactive ER diagrams, plan changes on the canvas, and generate reviewed SQL scripts for deployment.
The workflow is designed for visual modeling, schema documentation, and deployment — keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See CrateDB Features Download CrateDB JDBC Driver · All drivers
What happens after you download?
Get to your first CrateDB schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to CrateDB or open a sample
Reverse engineer an existing CrateDB database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
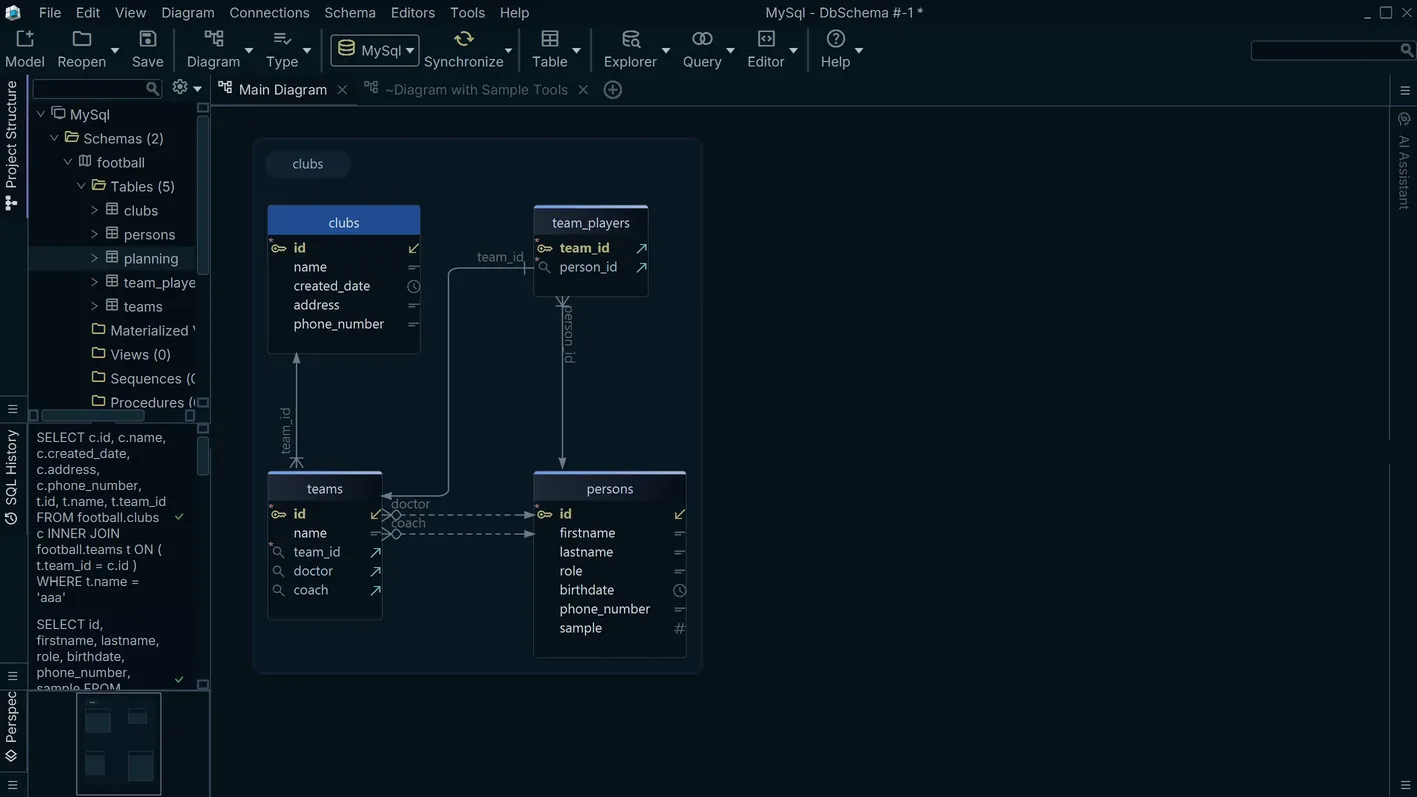
Distributed Sharding Model and Schema Visualization
CrateDB is a distributed SQL database engineered for machine data and IoT workloads, offering
PostgreSQL-compatible syntax alongside columnar storage and horizontal scaling through shards and
replicas. Each table in CrateDB is physically split into a configurable number of shards distributed
across cluster nodes, and each shard can be replicated for fault tolerance. DbSchema connects to
CrateDB using its PostgreSQL-compatible wire protocol and the CrateDB JDBC driver, introspecting tables,
columns, data types, and partition configurations. The resulting schema diagram captures the full table
structure including ARRAY and OBJECT column types, which are particularly
common in machine-data schemas where nested metadata accompanies sensor readings.
Download DbSchema Free See CrateDB Features
Writing SQL for IoT and Machine Data Analytics
CrateDB's SQL dialect includes full-text search predicates, array subscript expressions, and
object-column path access that go beyond standard relational SQL. DbSchema's SQL editor understands
the PostgreSQL-compatible connection and provides column auto-completion, syntax highlighting, and a
results grid that handles CrateDB's nested OBJECT values by flattening them into readable
columns. Queries involving time-bucket aggregations over large event tables benefit from CrateDB's
columnar storage engine, and the SQL editor displays execution time so you can evaluate the impact of
shard count and routing columns on query performance.
Exploring Large-Scale Time-Series and Event Data
The DbSchema data explorer lets you navigate CrateDB tables row by row with filter and sort controls.
For time-series event tables with hundreds of millions of rows, the explorer applies LIMIT
and offset-based pagination automatically, ensuring that browsing remains responsive regardless of
table size. You can filter by timestamp ranges or specific device identifiers, inspect
ARRAY column contents inline, and copy rows to the clipboard for further analysis. The
explorer also surfaces CrateDB's blob tables for object storage scenarios, letting you see blob
metadata alongside relational data in the same session.

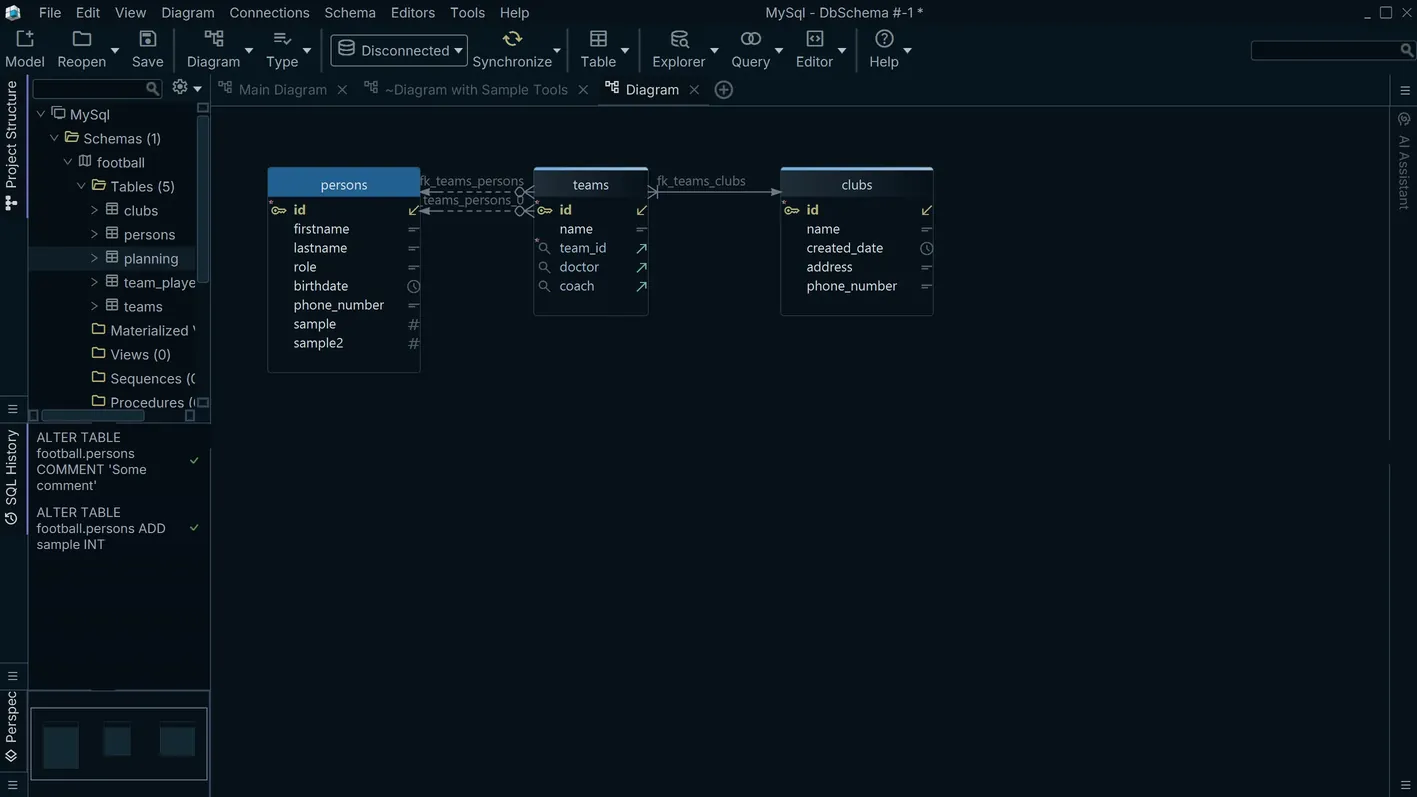
From Download to a CrateDB Schema Diagram
Bringing a CrateDB cluster into DbSchema involves the following steps:
- Install DbSchema — the download works without an account or license key for the free features.
- Download the CrateDB JDBC driver JAR (
io.crate.client.jdbc.CrateDriver) from the CrateDB releases page and register it in DbSchema's driver manager. - Point the connection at a CrateDB node using the JDBC URL
jdbc:crate://localhost:5432/, where 5432 is CrateDB's default PostgreSQL-compatible port — replacelocalhostwith the node's hostname for production deployments. - Enter the CrateDB username and password (newly installed clusters default to the
cratesuperuser with no password) and connect. - Review the reverse-engineered tables, including
ARRAYandOBJECTcolumns, in the generated ER diagram.
Enable TLS for production connections by appending SSL parameters to the JDBC URL. Because CrateDB clusters expose a single SQL endpoint regardless of node count, no special load-balancer configuration is needed on the DbSchema side.
Why Teams Use DbSchema with CrateDB
- Visualize CrateDB table schemas including complex
ARRAYandOBJECTcolumn types that are otherwise hard to document. - Write and test IoT analytics SQL with time-bucket aggregations and full-text predicates in DbSchema's SQL editor.
- Browse large event tables row by row in the data explorer without writing paginated queries manually.
- Generate schema documentation for CrateDB tables to share with data engineers and application developers onboarding to the platform.
- Design new CrateDB table schemas with shard and partition annotations in DbSchema's offline model before deploying to the cluster.
- Connect to CrateDB using the same familiar interface you use for PostgreSQL, taking advantage of protocol compatibility.
Want a clear picture of your IoT cluster's shards, replicas, and object columns? Download DbSchema for free and reverse-engineer your CrateDB schema today.
Related databases
Teams working with CrateDB often use these engines too. Explore dedicated guides and JDBC setup for each.