Design and Manage DuckDB Databases with DbSchema
Build a clearer workflow for DuckDB: reverse engineer existing schemas into interactive ER diagrams, model changes visually, and generate reviewed SQL scripts before deployment.
DbSchema is built for visual modeling, schema documentation, and deployment. Keep an offline model in Git, collaborate across teams, and publish documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See DuckDB Features Download DuckDB JDBC Driver
What happens after you download?
Get to your first DuckDB schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to DuckDB or open a sample
Reverse engineer an existing DuckDB database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
DuckDB is an embedded analytical SQL engine optimized for columnar, vectorized query execution — often described as the SQLite of OLAP workloads. It runs in-process, stores data in a single file, and can query Parquet, CSV, and JSON files directly without loading them into the database first. DbSchema connects to DuckDB via its JDBC driver, displays table schemas and view definitions in the diagram canvas, and provides an SQL editor for running complex analytical queries against both native DuckDB tables and external data files.
Open DuckDB Files Without a Server
DuckDB databases are single files — no server process or network configuration is required. DbSchema opens a DuckDB file directly, reads the schema metadata, and renders tables, views, and their column definitions in the diagram canvas. This is useful for exploring DuckDB files produced by data pipelines, shared as analysis artifacts, or used as local data stores in Python and R data science workflows.
Download DbSchema Free See DuckDB Features
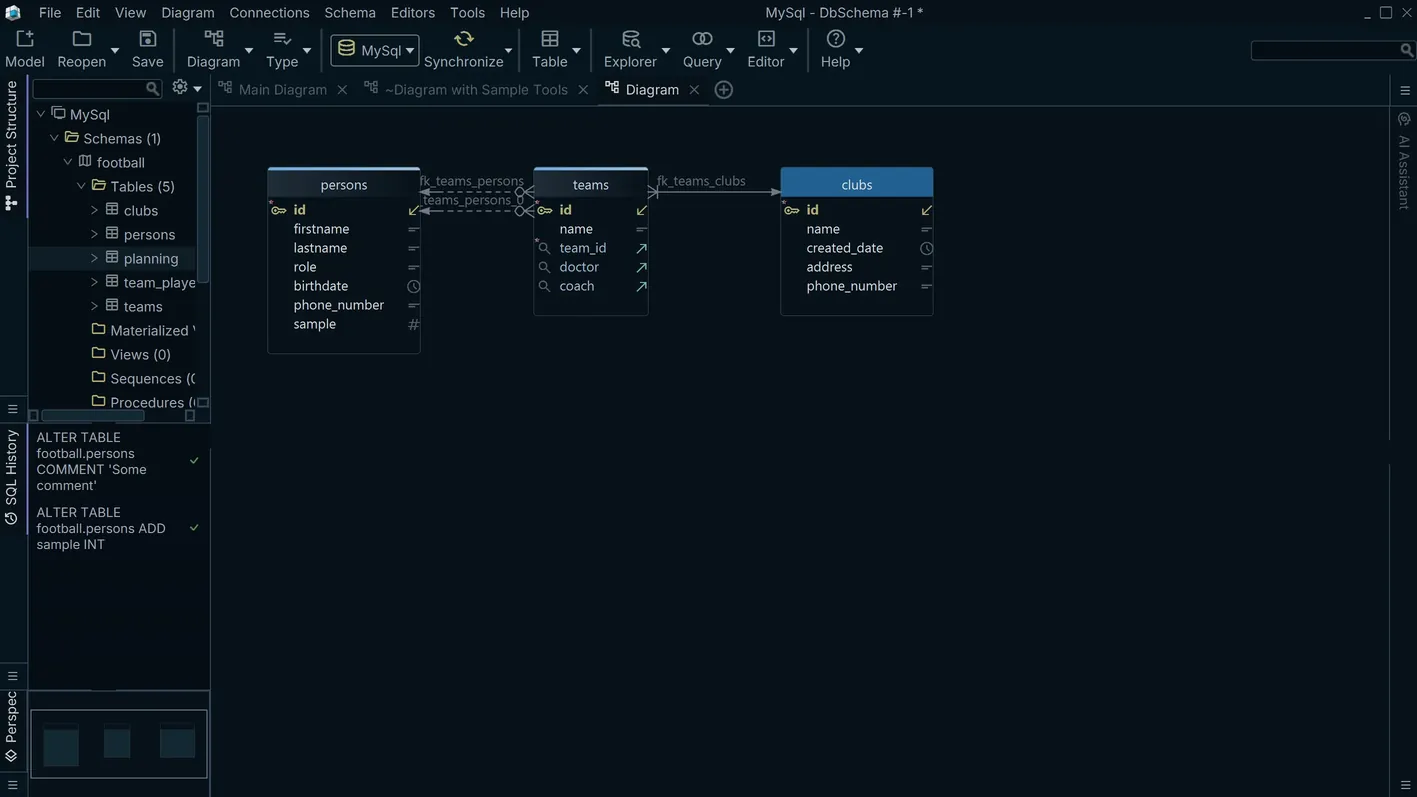
Run Analytical SQL Queries
DuckDB supports a rich analytical SQL dialect including window functions, PIVOT, UNPIVOT, and
direct file queries using read_parquet(), read_csv_auto(), and
read_json(). DbSchema's SQL editor lets you write and iterate on these queries,
inspect result sets inline, and export data — without switching to a Python notebook or a
separate CLI tool.
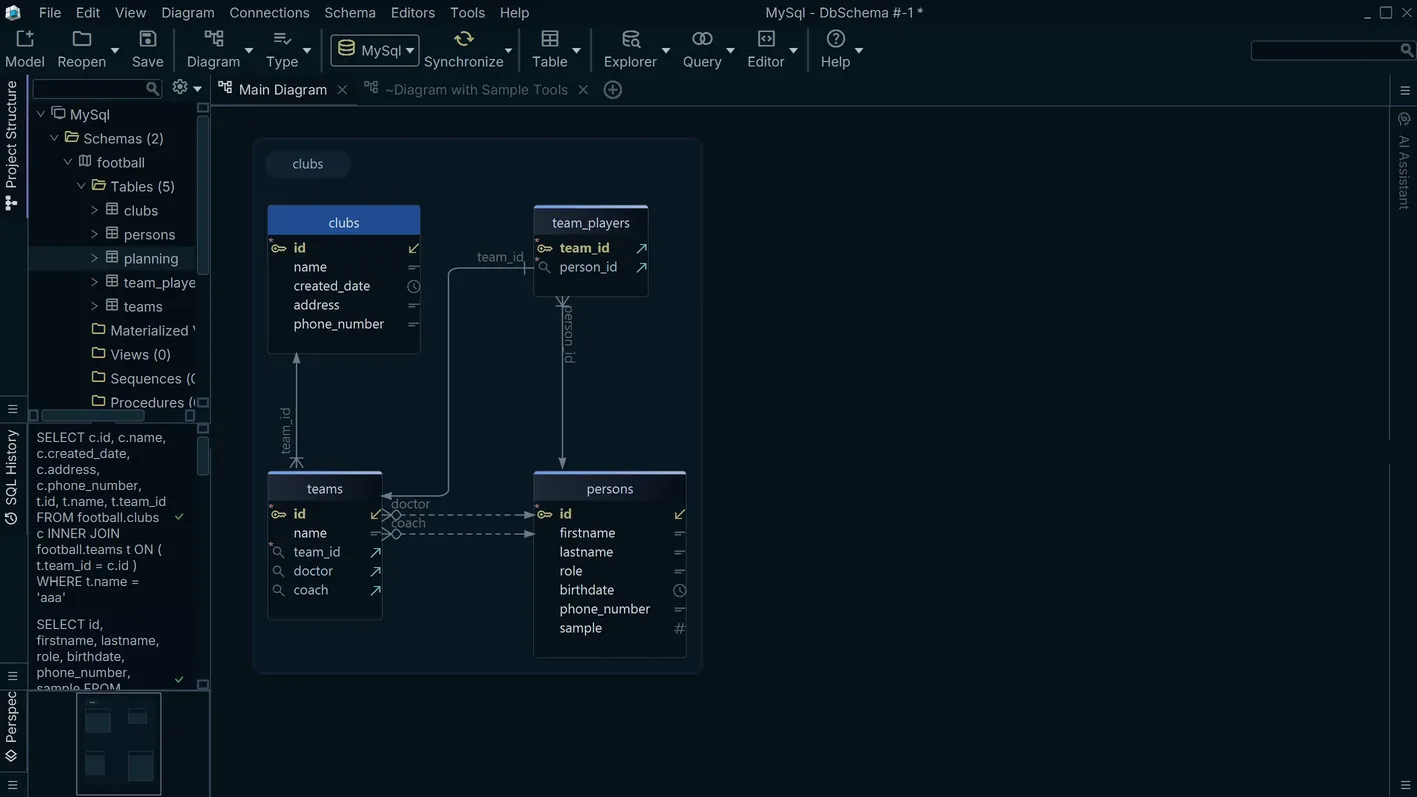
Explore Query Results in the Data Explorer
After running a query, the data explorer renders results in a paginated grid with column-level filtering. Use it to verify that an aggregation produces the expected row count, confirm that a Parquet file loaded with the correct column types, or audit individual records from a large result set without exporting to CSV first.

Connecting to DuckDB
DuckDB uses a file-based JDBC URL: jdbc:duckdb:/path/to/file.duckdb. For an
in-memory session without persistence, use jdbc:duckdb: with an empty path.
DbSchema downloads the DuckDB JDBC driver automatically — no manual driver installation is
required. Because DuckDB enforces single-writer access, close any other process that has the
database file open (such as a Python duckdb.connect() session) before connecting
from DbSchema to avoid a lock error.
Why Use DbSchema with DuckDB
- Open DuckDB files and visualize schemas without any server setup
- Run analytical SQL including window functions, PIVOT, and external file queries
- Inspect schema inference from Parquet and CSV files via DuckDB's catalog functions
- Browse query results without writing a separate Python or R client
- Document DuckDB table schemas for data engineering team reviews