Query and Browse CSV Files Like a Database
DbSchema gives CSV Files teams a design-first workflow: import the existing schema as an interactive ER diagram, refine it visually, and ship every change as a reviewed SQL script.
Built for visual modeling, schema documentation, and deployment, with an offline model you can keep in Git, team collaboration, and documentation that developers, analysts, and stakeholders can navigate in minutes.

Download DbSchema See CSV Files Features Download CSV Files JDBC Driver · All drivers
What happens after you download?
Get to your first CSV Files schema diagram in minutes. No account, no credit card.
Install in minutes
Download the installer for Windows, macOS, or Linux and launch DbSchema. No signup required.
Connect to CSV Files or open a sample
Reverse engineer an existing CSV Files database or open a sample model to explore tables, relationships, and indexes.
Design, document, and deploy
Edit schema visually, generate documentation, and prepare reviewed migration scripts for safer releases.
Query Flat Files as Relational Tables
CSV files are the most common format for exchanging and archiving structured data, but they lack the querying and inspection tools available to relational databases. DbSchema bridges that gap by connecting to a directory of CSV files through a JDBC driver — either CsvJdbc or DuckDB — and treating each file as a queryable table. Column types are inferred automatically from file contents, and the resulting schema appears in the diagram canvas without any prior import or transformation step.
Download DbSchema Free See CSV Files Features
Discover Column Schemas Without Importing Data
When DbSchema connects to a CSV directory, it reads the file headers and samples rows to infer column names and data types. The schema is displayed in the diagram canvas, making it easy to review which columns exist across multiple files and how they might relate to each other before loading data into a target database.
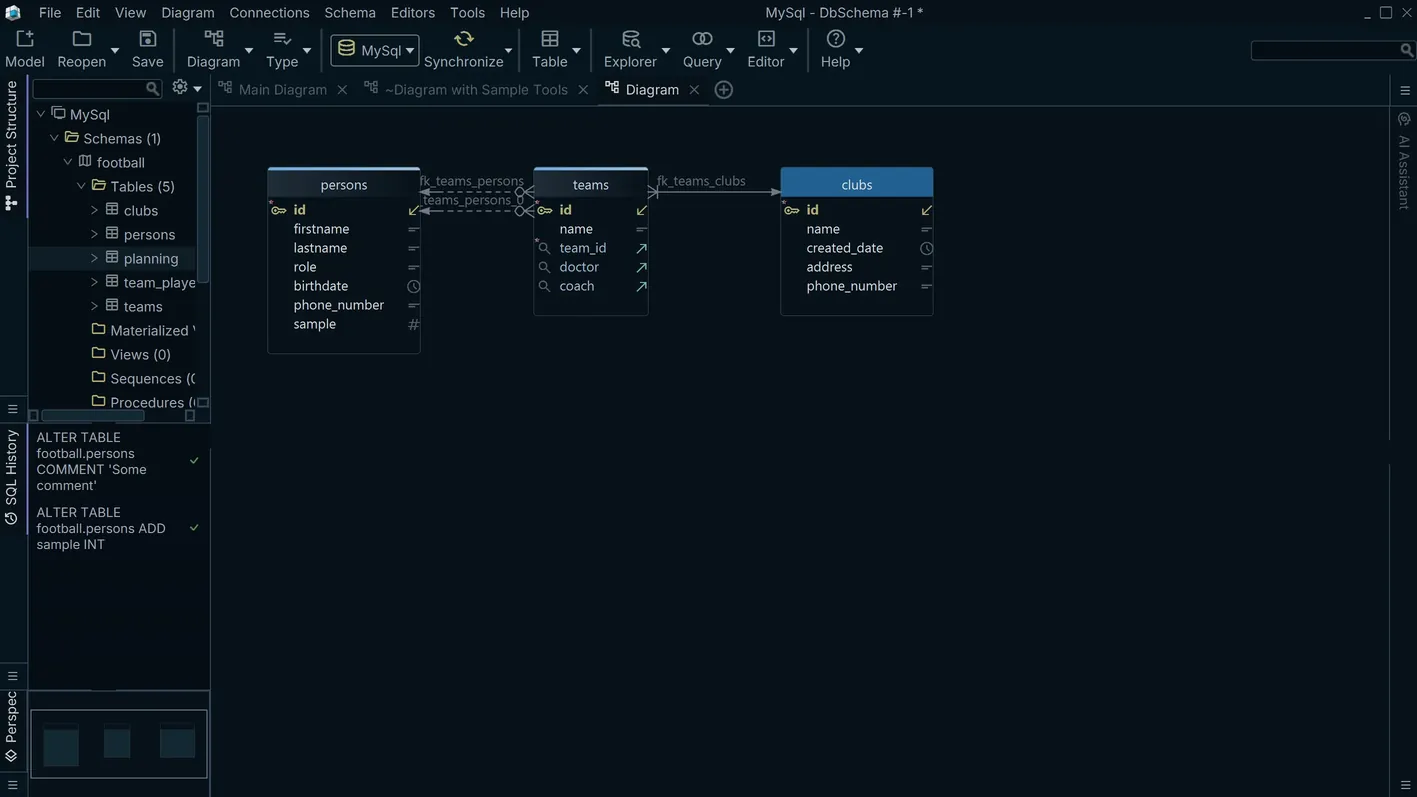
Browse and Filter CSV Data Visually
The data explorer renders CSV rows in a paginated grid with column-level filtering and sorting. Inspect large files without a spreadsheet application and verify that values conform to expected types before writing migration or ETL scripts.

Review and Refine Inferred Column Definitions
After auto-discovery, DbSchema lets you review and override the inferred column schema — rename columns, change data types, or mark fields as nullable. This is particularly useful when preparing a schema mapping for a migration to a structured relational database.
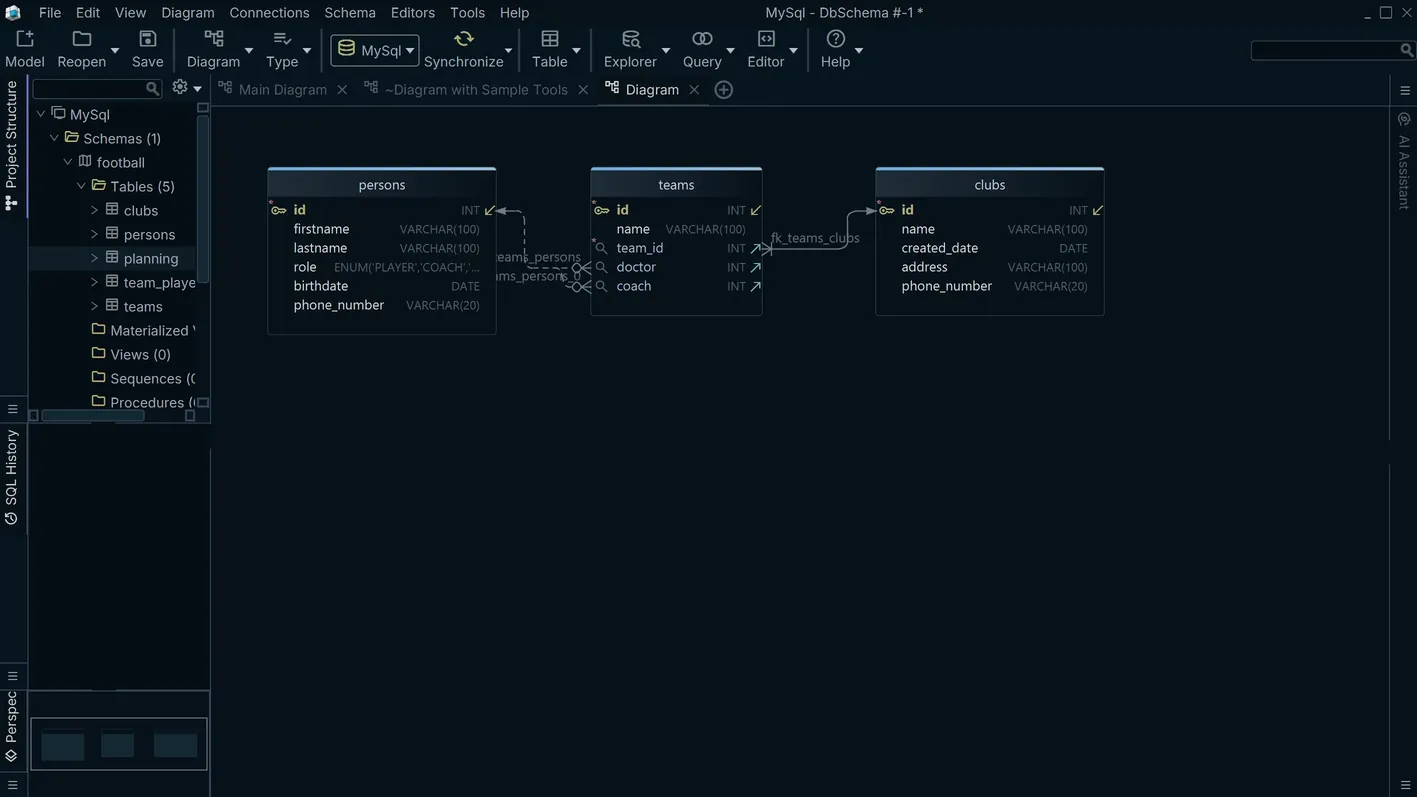
Explore and Document CSV Files with DbSchema
Turning a folder of CSV files into a queryable schema takes a handful of steps:
- Install DbSchema — no account is required to download it.
- Pick a JDBC approach: register the CsvJdbc driver (
csvjdbc.jar, from SourceForge) for a dedicated CSV connection, or connect to DuckDB in-memory instead. - For CsvJdbc, set the URL to
jdbc:relique:csv:/path/to/directoryso each.csvfile in that directory becomes a table; for DuckDB, callread_csv_auto('/path/to/file.csv')directly in the SQL editor. - Connect — DbSchema samples the files, infers column types, and renders the schema on the diagram canvas.
With CsvJdbc, column type inference can be adjusted through connection properties if the defaults don't match the actual data. DbSchema also maintains its own open-source CSV JDBC driver, with source code available on GitHub.
Why DbSchema for CSV Exploration
- Treat a directory of CSV files as a virtual schema — no import pipeline required.
- Run SQL
SELECT,JOIN, and aggregation queries across multiple files. - Inspect and override inferred column types before migrating data to a target database.
- Browse row contents in the data explorer with column filtering and pagination.
- Generate schema documentation from CSV-derived table definitions for data handovers.
Have a folder of CSVs waiting to be understood? Download DbSchema for free and turn those flat files into a documented, queryable schema without writing an import script.
Related databases
Teams working with CSV Files often use these engines too. Explore dedicated guides and JDBC setup for each.