DbSchema | Window Functions in SQL - Use in Data Analysis
Some days your company just isn’t doing well, and your data science lead will throw away any possible analysis he can think of, just to figure out the anomaly in data trends. Fortunately, with Window Functions in SQL, you can derive any variable or analysis required.
Window Function Benefit
Suppose we want a column that shows avg amount for each customer, without affecting the row count of the table.
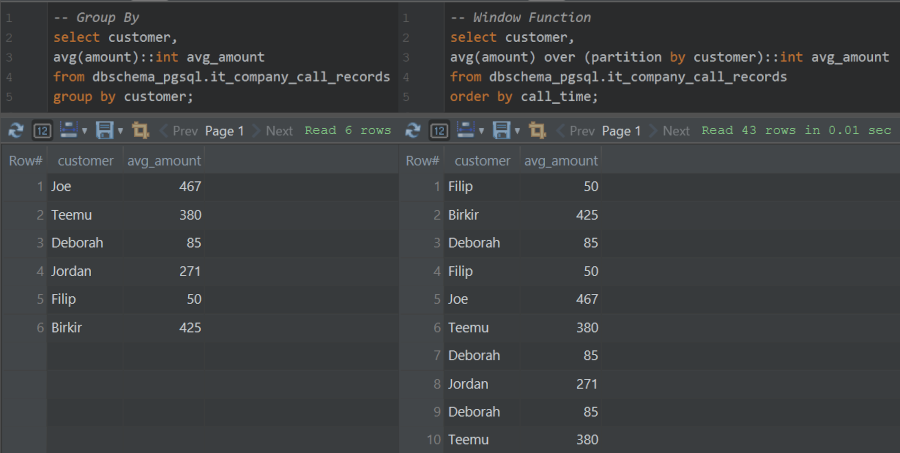
Using Group By limits the row count to the unique values of the grouped column, but by using window function we keep the table’s original row count and just append the desired column.
Extremely useful for feature engineering and creating variables that will be used in predictive modeling and validations.
Data Analysis with Window Functions in SQL Road Map:
- PostgreSQL Database and DbSchema Database Tool
- Postgres Random Data Generator
- Window Functions List in SQL
- Window Function Syntax Postgres
- Feature Engineering PostgreSQL
- Aggregate Window Functions
- Row Number Partition
- Postgres CTE
- Lag and Lead Window Functions
- Conclusion
PostgreSQL Database and DBSchema Database Tool

We will be using PostgreSQL as our Database and DbSchema as our Database Tools.
PostgreSQL is rapidly gaining popularity as the fastest open source SQL Database.
DbSchema is an intuitive Database Tool that supports
multiple Databases, including PostgreSQL.
It is unique from other DB Tools as it allows you to connect to DB in offline mode and make changes, that will be reflected once you go live.
It also has enhanced GUI (Graphical User Interface) functionality that allows you to visually draw out tables and queries instead of writing the code. Great for Beginners!
Postgres Random Data Generator
Using DbSchema, we create a table that shows calls of customers that may or may not have bought some IT service, with their respective amount
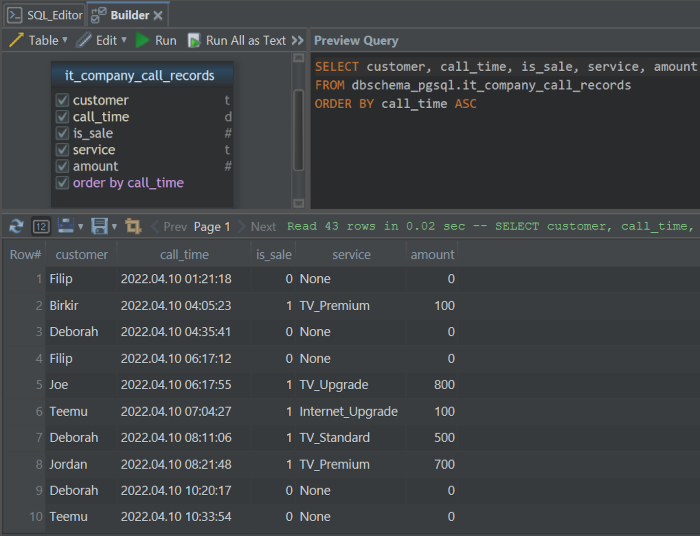
DbSchema has built in Random Data Generator that is very convenient
Data Tools > Data Generator > Select the desired table on which we want to generate the data
DbSchema gives a predefined set of values based on column types, but we can edit the values and their ranges through Edit Generator. Some examples for Generating values are mentioned here.
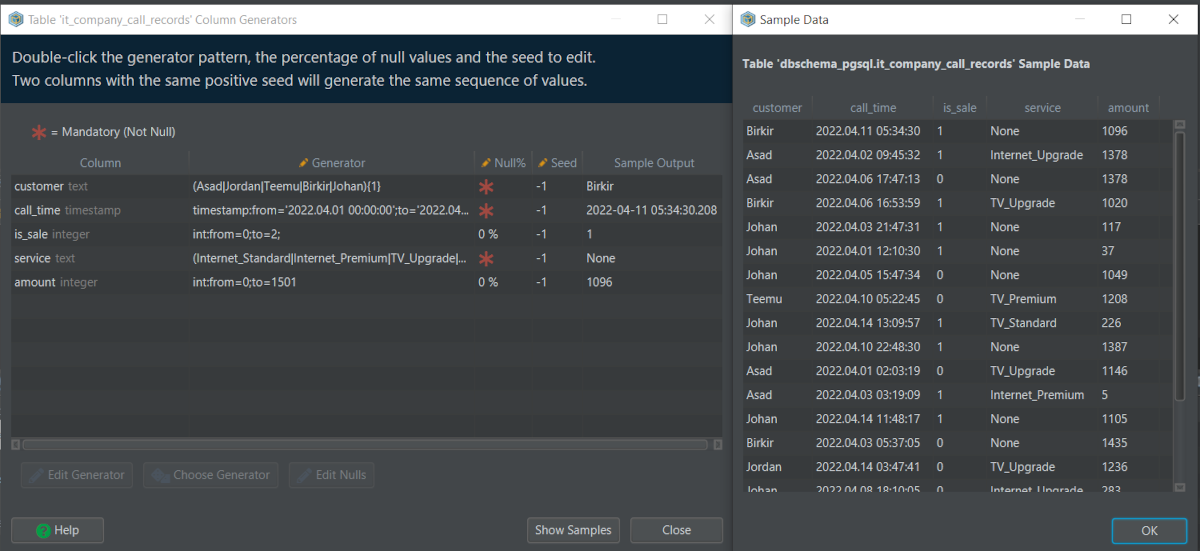
As we can see, we added custom values for each column in Generator tab, and Show Samples brings up the sample data that will be populated
For PostgreSQL learning purposes, to populate the table, we create a script that generates random data within the defined range of values for each column.
CREATE OR REPLACE FUNCTION generate_random_it_company_call_records(insert_count int)
RETURNS void
LANGUAGE plpgsql
AS $function$
declare v_insert_count int := insert_count::int;
begin
truncate table it_company_call_records_random;
while v_insert_count::int <> 0
loop
insert into it_company_call_records_random
(customer, call_time, is_sale,service, amount)
select a.*,
case when is_sale = 0 then 'None' else
(array['Internet_Premium','Internet_Standard','TV_Premium','TV_Standard','Internet_Upgrade','TV_Upgrade'])
[floor(random() * 6 + 1)] end as service,
case when is_sale = 0 then 0 else
round((random() * 900 + 1)::int+50,-2) end as amount
from (
select
(array['Asad','Jordan','Joe','Birkir','Deborah','Samir','Filip'])
[floor(random() * 7 + 1)] as customer,
('2022-04-15 00:00:00'::timestamp(0) + random() *
('2022-04-10 00:00:00'::timestamp(0) - '2022-04-1500:00:00'::timestamp(0)))::timestamp(0) as call_time,
random()::int is_sale)a;
v_insert_count = v_insert_count - 1;
end loop;
insert into it_company_call_records
select distinct on (customer, call_time, service) *
from it_company_call_records_random;
end ;
$function$
;
select generate_random_it_company_call_records(50);
In this script, we created conditional random data. For example, when is_sale column has 0 value, then logically service should be ‘None’ and amount should be 0.
As well, since our table has __Primary Key on __(customer,call_time,service), we remove duplicates using __distinct on` before inserting the random data.
However, Postgres Random Data Generation in DbSchema is very convenient and UI friendly in DbSchema, and you won’t have to worry about writing such scripts.
Window Functions List in SQL
| Aggregate Window Functions |
Value Window Functions |
Rank Window Functions |
|---|---|---|
| SUM() | NTH_VALUE() | RANK() |
| COUNT() | LAG() | DENSE_RANK() |
| AVG() | LEAD() | ROW_NUMBER() |
| MIN() | FIRST_VALUE() | PERCENT_RANK() |
| MAX() | LAST_VALUE() | CUME_DIST() |
The use of each window function is self-explanatory by its name, we’ll try to cover most of them through our data analysis on the generated data.
Window Function Syntax Postgres
Suppose we want to find the first call time for each customer. We will use the following components of window functions:
FIRST_VALUE(call_time) function to get the first call time
However, this will select the table’s first row call_time value and populate the column with itx. What we need is first call_time value for each customer. So we will divide our new column’s values for each customer by using:
Over to divide the rows into separate windows
Next, we will define the partition by clause on the column which we want to divide, in our case customer:
Partition By customer clause to separate the first_value for each customer.
So now we have a first value of call time for each customer, but we did not order our window function, so it will randomly pick the first row’s call_time value for each customer. So we will use order by clause on call_time to ensure first row is the first call time:
Order By call_time clause to order our call_time for each customer
The full query for this window function:
select customer, call_time,
first_value(call_time) over (partition by customer order by call_time) as first_call_time
from dbschema_pgsql.it_company_call_records
order by customer desc, call_time;
| customer | call_time | first_call_time | |
|---|---|---|---|
| 1 | Teemu | ||
| 2 | Teemu | 2022-04-10 10:33:54 | |
| 3 | Teemu | 2022-04-10 14:36:27 | |
| 4 | Teemu | 2022-04-11 02:53:46 | |
| 5 | Teemu | 2022-04-13 22:46:25 | |
| 6 | Jordan | ||
| 7 | Jordan | 2022-04-10 12:42:45 | |
| 8 | Jordan | 2022-04-11 09:01:55 | |
| 9 | Jordan | 2022-04-11 16:04:41 | |
| 10 | Jordan | 2022-04-12 07:10:50 |
As we can see, first_call_time column shows the first call_time for each customer.
Feature Engineering PostgreSQL
Feature Engineering is essential to derive useful variables from a raw dataset.
By performing data analysis, we can brainstorm some meaningful insights.
Then we’ll use window functions to create variables from these insights.
We’ll divide our analysis based on Window Functions List.
Aggregate Window Functions
Task # 1: We want to know the cumulative amount for each customer at each call record
(Meaning, do not include the amount from sales that occurred in a future call)
select *,
sum(amount) over (partition by customer order by call_time) as cumulative_amount
from dbschema_pgsql.tele_orders order by customer desc, call_time;
| customer | call_time | is_sale | service | amount | cumulative_amount | |
|---|---|---|---|---|---|---|
| 1 | Teemu | 2022-04-10 07:04:27 | 1 | Internet_Upgrade | 100 | 100 |
| 2 | Teemu | 2022-04-10 10:33:54 | 0 | None | 0 | 100 |
| 3 | Teemu | 2022-04-10 14:36:27 | 1 | Internet_Standard | 500 | 600 |
| 4 | Teemu | 2022-04-11 02:53:46 | 1 | Internet_Upgrade | 600 | 1200 |
| 5 | Teemu | 2022-04-13 22:46:25 | 1 | Internet_Standard | 700 | 1900 |
| 6 | Jordan | 2022-04-10 08:21:48 | 1 | TV_Premium | 700 | 700 |
| 7 | Jordan | 2022-04-10 12:42:45 | 1 | TV_Standard | 300 | 1000 |
| 8 | Jordan | 2022-04-11 09:01:55 | 0 | None | 0 | 1000 |
| 9 | Jordan | 2022-04-11 16:04:41 | 1 | Internet_Premium | 100 | 1100 |
| 10 | Jordan | 2022-04-12 07:10:50 | 1 | Internet_Premium | 800 | 1900 |
Task # 2: Now we want the cumulative amount again for each customer, but it needs to be for each day
(The cumulative amount should reset after each day)
All we have to do is add another __partition byclause for each call date.call_time::date` is used to cast a timestamp into date in Postgres.
select *,
sum(amount) over
(partition by customer,call_time::date order by call_time) as cumulative_amount_daywise
from dbschema_pgsql.it_company_call_records order by customer desc, call_time;
| customer | call_time | is_sale | service | amount | cumulative_amount_daywise | |
|---|---|---|---|---|---|---|
| 1 | Teemu | 2022-04-10 07:04:27 | 1 | Internet_Upgrade | 100 | 100 |
| 2 | Teemu | 2022-04-10 10:33:54 | 0 | None | 0 | 100 |
| 3 | Teemu | 2022-04-10 14:36:27 | 1 | Internet_Standard | 500 | 600 |
| 4 | Teemu | 1 | Internet_Upgrade | 600 | ||
| 5 | Teemu | 1 | Internet_Standard | 700 | ||
| 6 | Jordan | 2022-04-10 08:21:48 | 1 | TV_Premium | 700 | 700 |
| 7 | Jordan | 2022-04-10 12:42:45 | 1 | TV_Standard | 300 | 1000 |
| 8 | Jordan | 0 | None | 0 | ||
| 9 | Jordan | 2022-04-11 16:04:41 | 1 | Internet_Premium | 100 | 100 |
| 10 | Jordan | 1 | Internet_Premium | 800 |
Highlighted rows show transitions from one day to another. As we can see, the cumulative amount resets after each day too, for each customer.
Task # 3: We want to know the max amount , first call time and total calls made by the customer each day
Since the window function partition is the same, we can give it an __alias **customer_date** using __window.
select *,
max(amount) over customer_date as max_amount_daywise,
min(call_time) over customer_date as first_call_time_daywise,
count(*) over customer_date as total_calls_daywise
from dbschema_pgsql.it_company_call_records
window customer_date as (partition by customer,call_time::date)
order by customer desc, call_time;
| customer | call_time | is_sale | service | amount | max_amount_daywise | first_call_time_daywise | total_calls_daywise | |
|---|---|---|---|---|---|---|---|---|
| 1 | Teemu | 2022-04-10 07:04:27 | 1 | Internet_Upgrade | 100 | 500 | 2022-04-10 07:04:27 | 3 |
| 2 | Teemu | 2022-04-10 10:33:54 | 0 | None | 0 | 500 | 2022-04-10 07:04:27 | 3 |
| 3 | Teemu | 2022-04-10 14:36:27 | 1 | Internet_Standard | 500 | 500 | 2022-04-10 07:04:27 | 3 |
| 4 | Teemu | 2022-04-11 02:53:46 | 1 | Internet_Upgrade | 600 | 600 | 2022-04-11 02:53:46 | 1 |
| 5 | Teemu | 20202-04-13 22:46:25 | 1 | Internet_Standard | 700 | 700 | 2022-04-13 22:46:25 | 1 |
| 6 | Jordan | 2022-04-10 08:21:48 | 1 | TV_Premium | 700 | 700 | 2022-04-10 08:21:48 | 2 |
| 7 | Jordan | 2022-04-10 12:42:45 | 1 | TV_Standard | 300 | 700 | 2022-04-10 08:21:48 | 2 |
| 8 | Jordan | 2022-04-11 9:01:55 | 0 | None | 0 | 100 | 2022-04-11 09:01:55 | 2 |
| 9 | Jordan | 2022-04-11 16:04:41 | 1 | Internet_Premium | 100 | 100 | 2022-04-11 09:01:55 | 2 |
| 10 | Jordan | 2022-04-12 07:10:50 | 1 | Internet_Premium | 800 | 800 | 2022-04-12 07:10:50 | 1 |
Since we are using __MIN() instead of __FIRST_VALUE(), we do not have to use __order by` clause either.
Row Number Partition
In this section, we’ll do the analysis that requires the __Rank window function and __Row Number Partition.
Task # 4: We want to find the call number for each customer, overall and daywise
Once you understand how to divide our rows using __Partition by and __Order by, the only that changes for the most part is the window function itself.
Here, we will __partition by **customer** for overall and then __partition by additionally on date for daywise.
select *,
row_number() over (partition by customer order by call_time) as call_no_overall,
row_number() over (partition by customer,call_time::date order by call_time) as call_no_daywise
from dbschema_pgsql.it_company_call_records
order by customer desc, call_time;
| customer | call_time | is_sale | service | amount | call_no_overall | call_no_daywise | |
|---|---|---|---|---|---|---|---|
| 1 | Teemu | 2022-04-10 07:04:27 | 1 | Internet_Upgrade | 100 | 1 | 1 |
| 2 | Teemu | 2022-04-10 10:33:54 | 0 | None | 0 | 2 | 2 |
| 3 | Teemu | 2022-04-10 14:36:27 | 1 | Internet_Standard | 500 | 3 | 3 |
| 4 | Teemu | 2022-04-11 02:53:46 | 1 | Internet_Upgrade | 600 | 4 | 1 |
| 5 | Teemu | 2022-04-13 22:46:25 | 1 | Internet_Standard | 700 | 5 | 1 |
| 6 | Jordan | 2022-04-10 08:21:48 | 1 | TV_Premium | 700 | 1 | 1 |
| 7 | Jordan | 2022-04-10 12:42:45 | 1 | TV_Standard | 300 | 2 | 2 |
| 8 | Jordan | 2022-04-11 09:01:55 | 0 | None | 0 | 3 | 1 |
| 9 | Jordan | 2022-04-11 16:04:41 | 1 | Internet_Premium | 100 | 4 | 2 |
| 10 | Jordan | 2022-04-12 07:10:50 | 1 | Internet_Premium | 800 | 5 | 1 |
Task # 5: We want to rank each customer based on total amount spent
So this task requires a prerequisite, which is the total amount, because the ranking will be done based on the total amount> of each customer.
We will use CTE to first get the total amount.
CTE Postgres
Here, we’ll introduce Common Table Expression or CTE Postgres. We can create a table known as CTE, and use that table as a base table for our queries.
Just think of CTE as a temporary created table for our query.
In our case, we’ll create a CTE with the
with cte as (
select *,
sum(amount) over (partition by customer) as customer_total_amount
from dbschema_pgsql.it_company_call_records
)
select *,
dense_rank() over (order by customer_total_amount desc) as customer_rank
from cte
order by call_time;
| customer | call_time | is_sale | service | amount | customer_total_amount | customer_rank | |
|---|---|---|---|---|---|---|---|
| 1 | Filip | 2022-04-10 01:21:18 | 0 | None | 0 | 400 | 5 |
| 2 | Birkir | 2022-04-10 04:05:23 | 1 | TV_Premium | 100 | 1700 | 3 |
| 3 | Deborah | 2022-04-10 04:35:41 | 0 | None | 0 | 1100 | 4 |
| 4 | Filip | 2022-04-10 06:17:12 | 0 | None | 0 | 400 | 5 |
| 5 | Joe | 2022-04-10 06:17:55 | 1 | TV_Upgrade | 800 | 2800 | 1 |
| 6 | Teemu | 2022-04-10 07:04:27 | 1 | Internet_Upgrade | 100 | 1900 | 2 |
| 7 | Deborah | 2022-04-10 08:11:06 | 1 | TV_Standard | 500 | 1100 | 4 |
| 8 | Jordan | 2022-04-10 08:21:48 | 1 | TV_Premium | 700 | 1900 | 2 |
| 9 | Deborah | 2022-04-10 10:20:17 | 0 | None | 0 | 1100 | 4 |
| 10 | Teemu | 2022-04-10 10:33:54 | 0 | None | 0 | 1900 | 2 |
Using the CTE, we created for our __rank partition window.
I like to use __DENSE_RANK() instead of __RANK() as the latter would skip the number if 2 or more customers had the same rank.
As we see that Teemu and Jordan share rank 2.
Lag and Lead Window Functions
We’ll combine different analysis related to __value` window functions in one task.
Task # 6:
We want to find the
first service purchasedTime Difference in mins between the current call and the preceding callIf a call did not result in a sale, did the
leading call result in a sale?
(All 3 Tasks are to be done for each customer and not on overall data)
So we have 3 different variables that we need to create here:
For the first service, we just have to ensure that it’s value is not ‘None’.
We can do that by applying __Order by is_sale desc`, this will ensure first row is the one with a sale
Time Difference in minus can be calculated by subtracting current call with the __LAG(call_time)`, and then convert the result into minutes through casting.
Lag(call_time) will give us the previous row’s call_time, where the previous row depends on our __Partition by. To check for <g>no sale into sale</g>, first we can use __case statement to check if the current call had a sale or not, and then use __LEAD(sale)to check if the **leading call** had a **sale** or not.Lag will give us previous row and __Lead will give us next row.
select *,
first_value(service) over
(partition by customer order by is_sale desc,call_time) as first_service,
round(extract(epoch from (call_time -
lag(call_time) over (partition by customer order by call_time)))/60)
as mins_since_last_call,
case when is_sale = 0 and
lead(is_sale) over (partition by customer order by call_time) = 1
then 'Yes' else 'No' end as nosale_to_sale
from dbschema_pgsql.it_company_call_records
order by customer, call_time;
| customer | call_time | is_sale | service | amount | first_service | mins_since_last_call | nosale_to_sale | |
|---|---|---|---|---|---|---|---|---|
| 1 | Birkir | 2022-04-10 04:05:23 | 1 | TV_Premium | 100 | TV_Premium | No | |
| 2 | Birkir | 2022-04-10 10:56:31 | 1 | Internet_Standard | 800 | TV_Premium | 411 | No |
| 3 | Birkir | 2022-04-12 18:19:27 | 0 | None | 0 | TV_Premium | 3323 | Yes |
| 4 | Birkir | 2022-04-14 14:15:17 | 1 | TV_Premium | 800 | TV_Premium | 2636 | No |
| 5 | Deborah | 2022-04-10 04:35:41 | 0 | None | 0 | TV_Standard | Yes | |
| 6 | Deborah | 2022-04-10 08:11:06 | 1 | TV_Standard | 500 | TV_Standard | 215 | No |
| 7 | Deborah | 2022-04-10 10:20:17 | 0 | None | 0 | TV_Standard | 129 | No |
| 8 | Deborah | 2022-04-10 23:14:19 | 0 | None | 0 | TV_Standard | 774 | No |
| 9 | Deborah | 2022-04-11 04:58:07 | 0 | None | 0 | TV_Standard | 344 | No |
| 10 | Deborah | 2022-04-11 05:34:39 | 0 | None | 0 | TV_Standard | 37 | No |
As we can see, for Deborah, even though the service is ‘None’ for first row, but we skip it because we __order by` is_sale desc first and then call_time.
Conclusion
Window Functions in SQL enable us to perform any analysis and derive any variable required.
As well, Postgres is a powerful open source language that allows functionality like CTE. It’s famous for its parallel processing speed as compared to other SQL DBs.
Lastly, DbSchema is an UI-friendly Database Tool that supports multiple languages, including Postgres. Can also connect it to DBeaver/PGAdmin and other Database Tools or DB, and it replicates changes on runtime.
I highly recommend DbSchema as the Database Tool to start with, especially for PostgreSQL DB.
You can download DbSchema here.